Información general



Aquest llibre conté el recull de pràctiques ha realitzar a l'assignatura d'Administració i Manteniment de Sistemes i Aplicacions (AMSA). Aquestes pràctiques estan enfocades a l'administració de sistemes GNU/Linux, en concret, amb la distribucions AlmaLinux i Debian.
-
AlmaLinux és una distribució de GNU/Linux basada en Red Hat Enterprise Linux (RHEL) i CentOS utilizarem la versió 9.4.
-
Debian és una distribució de GNU/Linux utilitzarem la versió 12.5.0.
Continguts
- Instal·lació i Configuració de Màquines Virtuals.
- Scripting.
- Arrancada del Sistema.
- Sistema de Fitxers.
- RAID.
- Servidors.
Utilització
Es tracten de laboratoris pràctics resolts que us permet experimentar amb els continguts teòrics presentats a les sessions de teoria. Moltes comandes i configuracions es troben amagades inicialment per tal que pugueu intentar resoldre els exercicis per vosaltres mateixos. Si us trobeu amb problemes o voleu comprovar la vostra solució, podeu consultar la solució clicant al botó en forma d'ull 👁️.
Adicionalment, es demanara l'entrega d'informes per a cada laboratori. Aquests informes han d'intentar donar resposta a les preguntes plantejades en el context de cada laboratori.
Instal·lació d'una màquina virtual
Per a realitzar tots els laboratoris d'aquest curs, necessitareu una màquina virtual amb un sistema operatiu basat en Linux. En aquest curs us proposo utilitzar, dos distribucions molt populars per a servidors en entorns de producció.
-
Debian 12: Debian és una distribució de Linux molt popular i estable. És una de les distribucions més antigues i utilitzades en servidors. Debian és conegut per la seva estabilitat, seguretat i facilitat d'ús. És una excel·lent opció per a servidors web, servidors de correu electrònic, servidors de bases de dades i altres aplicacions de servidor. Concretament, utilitzarem la versió 12.5.0.
-
AlmaLinux 9: AlmaLinux és una distribució de Linux basada en Red Hat Enterprise Linux (RHEL). És una distribució de Linux empresarial que ofereix suport a llarg termini i actualitzacions de seguretat. Es una de les alternativa open-source de RHEL. Concretament, utilitzarem la versió 9.4.
Software de virtualització
En aquest curs, us recomano utilitzar VMWare com a software de virtualització. VMWare és un dels software de virtualització més populars i utilitzats en entorns de producció. A més, VMWare ofereix una versió gratuïta per a ús personal i educatiu:
- Windows: VMWare Workstation Player
- Mac: VMWare Fusion
A més, VMWare funciona en les principals arquitectures de processador com x86 i ARM. Durant el curs, els exemple i el suport es basaran en l'ús de VMWare. Resta a la vostra elecció utilitzar un altre software de virtualització com VirtualBox, KVM, UTM o d'altres.
Tasques
- Instal·la un màquina virtual amb Debian 12.5.0 en mode text
- Informació bàsica sobre hostname i
hostnamectl - Informació bàsica sobre resolució de noms
- Informació bàsica sobre com connectar-se a una màquina virtual amb SSH i transferència de fitxers
Activitats
- Documenta el procés d'instal·lació de la màquina virtual amb AlmaLinux 9.4 amb una interfície gràfica.
- Descriu les diferències entre el procés d'instal·lació de les dues distribucions.
- Investiga com es pot crear un clon d'una màquina virtual amb VMware i documenta el procés. Comenta els avantatges i inconvenients de clonar una màquina virtual.
Rúbriques d'avaluació
Realització de les tasques: 100%
| Criteris d'avaluació | Excel·lent (5) | Notable(3-4) | Acceptable(1-2) | No Acceptable (0) |
|---|---|---|---|---|
| Contingut | El contingut és molt complet i detallat. S'han cobert tots els aspectes de la tasca. | El contingut és complet i detallat. S'han cobert la majoria dels aspectes de la tasca. | El contingut és incomplet o poc detallat. Falten alguns aspectes de la tasca. | El contingut és molt incomplet o inexistent. |
| Estil | L'estil és molt adequat i professional. S'ha utilitzat un llenguatge tècnic precís. | L'estil és adequat i professional. S'ha utilitzat un llenguatge tècnic precís. | L'estil és poc adequat o professional. Hi ha errors en el llenguatge tècnic. | L'estil és molt poc adequat o professional. Hi ha molts errors en el llenguatge tècnic. |
| Precisió i exactitud | La informació és precisa i exacta. No hi ha errors. | La informació és precisa i exacta. Hi ha pocs errors. | La informació és imprecisa o inexacta. Hi ha errors. | La informació és molt imprecisa o inexacta. Hi ha molts errors. |
| Organització | La informació està ben organitzada i estructurada. És fàcil de seguir. | La informació està organitzada i estructurada. És fàcil de seguir. | La informació està poc organitzada o estructurada. És difícil de seguir. | La informació està molt poc organitzada o estructurada. És molt difícil de seguir. |
| Justificació | S'han justificat les respostes amb arguments vàlids i exemples pràctics. | S'han justificat les respostes amb arguments vàlids. | S'han justificat les respostes amb arguments poc vàlids. | No s'han justificat les respostes. |
| Expansió | S'han ampliat les respostes amb informació addicional rellevant. | S'han ampliat les respostes amb informació addicional. | S'han ampliat les respostes amb informació poc rellevant. | No s'han ampliat les respostes. |
| Suport gràfic o audiovisual | S'han utilitzat recursos gràfics o audiovisuals per aclarir la informació. | S'han utilitzat recursos gràfics o audiovisuals. | S'han utilitzat pocs recursos gràfics o audiovisuals. | No s'han utilitzat recursos gràfics o audiovisuals. |
Instal·lació del sistema operatiu Debian 12
En aquest laboratori, instal·larem el sistema operatiu Debian 12 en una màquina virtual i descriurem els components principals del sistema operatiu. Aquesta instal·lació és la base per a tots els laboratoris que realitzarem en aquest curs. En alguns, us demanaré que modifiqueu alguns paràmetres de configuració per adaptar-los a les necessitats del laboratori.
Configuració de la màquina virtual amb VMWare
- Selecciona l’opció
Create a New Virtual Machinea VMWare Workstation Player o VMWare Fusion. - Selecciona Install from disc or image.
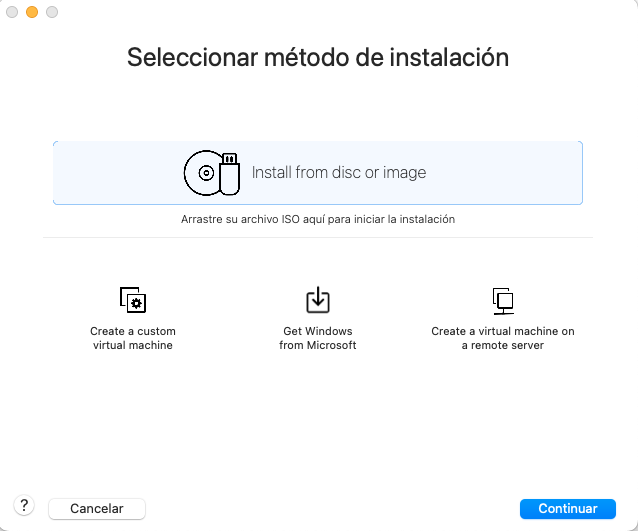
- Selecciona la imatge ISO de Debian 12.
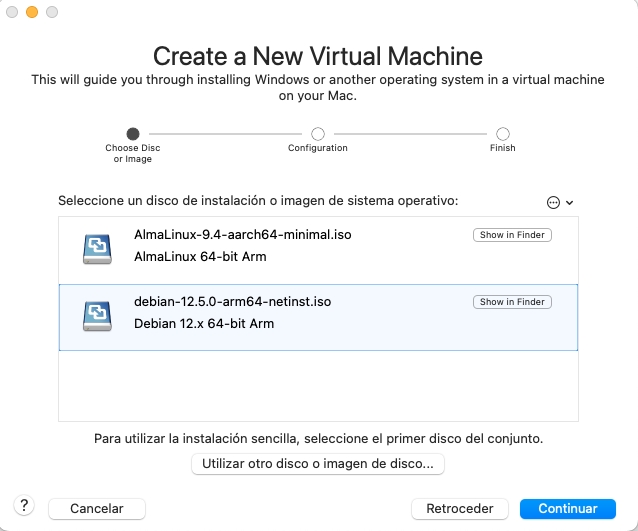
- Configura els recursos de la màquina virtual.
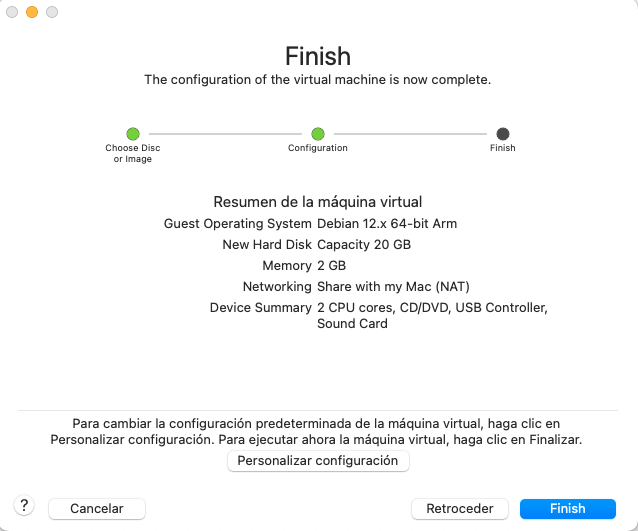
Instal·lació del sistema operatiu
-
Un cop iniciada la màquina virtual, podeu seleccionar la opció Install o bé Graphical install.
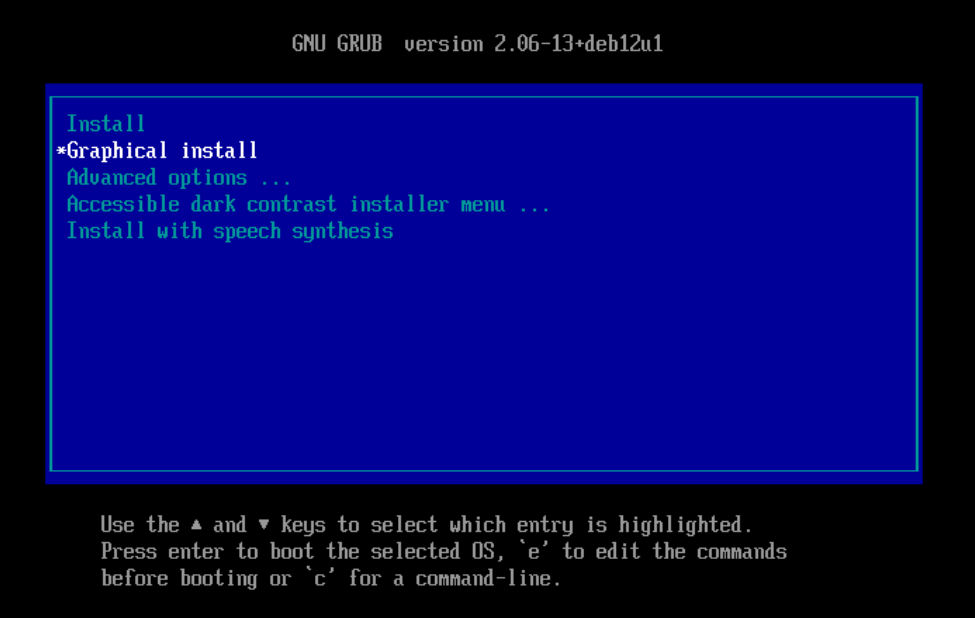
En aquest tutoriral, seleccionarem la opció Graphical install per a una instal·lació més amigable. La principal diferència entre les dues opcions és l'entorn gràfic.
-
Selecciona l'idioma d'instal·lació.
Podeu seleccionar l'idioma que vulgueu per a la instal·lació. En aquest cas, seleccionarem l'idioma Català.
-
Selecciona la ubicació geogràfica.
En aquest cas, seleccionarem la ubicació Espanya.
-
Selecciona la disposició del teclat.
En aquest cas, seleccionarem la disposició de teclat Català. Això ens asegurarà un mapeig correcte del teclat.
-
Espereu que el sistema carregui els components necessaris.
-
Configura la xarxa.
- El primer pas és configurar el nom d'amfitrió o hostname. Aquest nom permet identificar de forma única el vostre sistema. Podeu deixar el nom per defecte o canviar-lo al vostre gust.
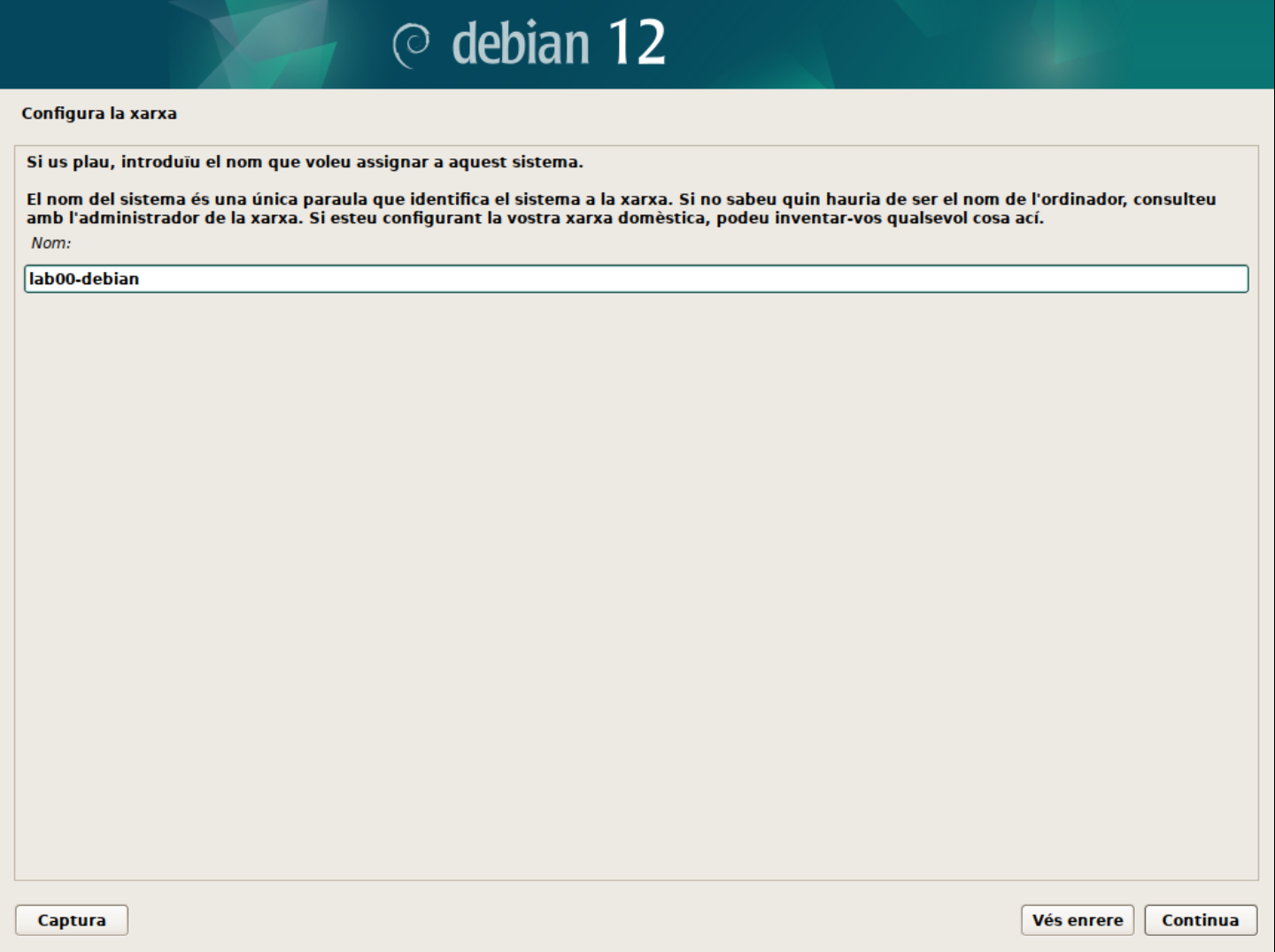
En aquest cas, hem canviat el nom d'amfitrió a
lab00-debian.🚀 Consell:
Els administradors de sistemes acostumen a administrar múltiples servidors i dispositius. Per tant, és important identificar cada dispositiu amb un nom únic per facilitar la gestió i la comunicació entre ells. Per tant, us recomano que utilitzeu un nom d'amfitrió significatiu per identificar-lo fàcilment.
Us recomano un cop instal·lat el sistema que doneu una ullada a l'apartat Hostname per obtenir més informació sobre com gestionar el nom d'amfitrió.
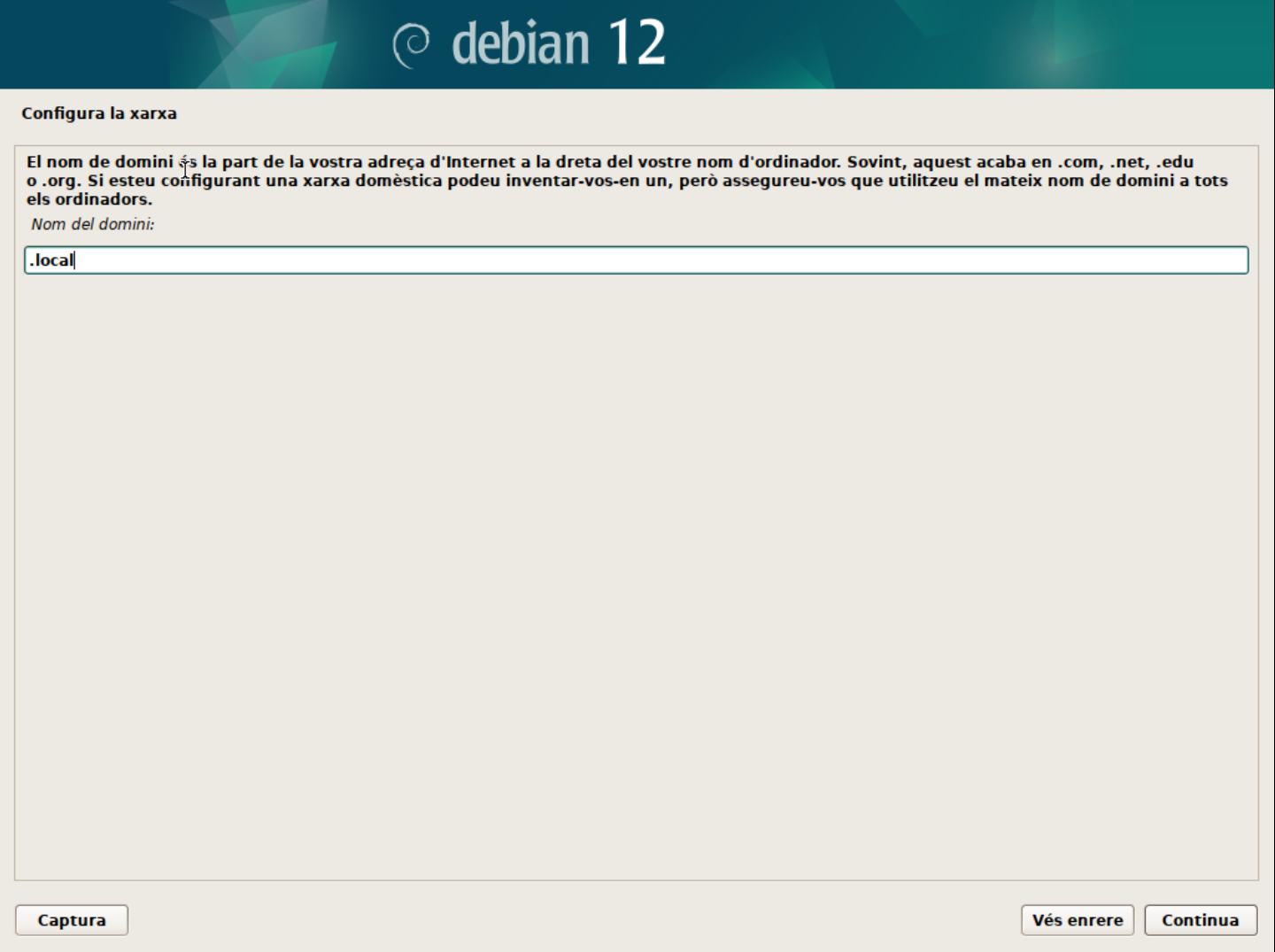
- El segon pas és configurar el domini de la xarxa. Aquest pas el podeu deixar en blanc si no teniu un domini específic. O bé, podem utilitzar
.localcom a domini local per identicar que el servidor pertany a la xarxa local.
💡 Nota:
En un domini empresarial, normalment s'utilitza el nom de domini de l'empresa. Imagina que aquesta màquina virtual és el servidor d'una base de dades mysql de l'empresa
acme.com. En aquest cas, el domini seriaacme.com. I el nom d'amfitrió podria sermysql01.acme.com. -
Configura l'usuari administrador.

En aquest punt, heu de tenir en compte que si no poseu cap contrasenya, es crearà l'usuari normal amb permisos de
sudoi això us permetra executar comandes amb privilegis d'administrador.Si poseu una contrasenya, aquesta serà la contrasenya de l'usuari
rooti no es crearà un usuari normal amb permisos desudo. I tampoc s'instal·larà el paquetsudo.⚠️ Compte
Com utilitzarem les màquines virtuals com a laboratoris de pràctiques, no cal que poseu una contrasenya molt segura. Podeu utilitzar una com a
1234. Però, recordeu que en un entorn real, la seguretat és molt important i cal utilitzar contrasenyes segures. -
Configura un usuari normal.
- Nom complet: Podeu posar el vostre nom complet o el que vulgueu.
- Nom d'usuari: Podeu posar el vostre nom d'usuari o el que vulgueu.
- Contrasenya: El mateix que per l'usuari
root.
-
Configura la zona horària.
En aquest cas, seleccionarem la zona horària de Madrid.
-
Configura el disc dur.
- Particionament: Durant el curs apendreu a realitzar particionament manual i, també discutirem sobre LV (Logical Volumes) i LVM (Logical Volume Manager). Però, per a una instal·lació senzilla, de moment, seleccionarem la primera opció (Guiat - utilitzar tot el disc).
- Selecciona el disc on instal·lar el sistema. En el meu cas, només tinc un disc virtual amb l'etiqueta
/dev/nvme0n1. L'etiqueta indica el tipus de disc (NVMe) i el número de disc (1). Es possible tenir altres etiquetes com/dev/sdaper discos SATA o/dev/vdaper discos virtuals.
- Particions: Durant el curs apendreu les avantatges i com gestionar sistemes amb particions separades. Però, de moment, seleccionarem la primera opció (Totes les dades en una sola partició).
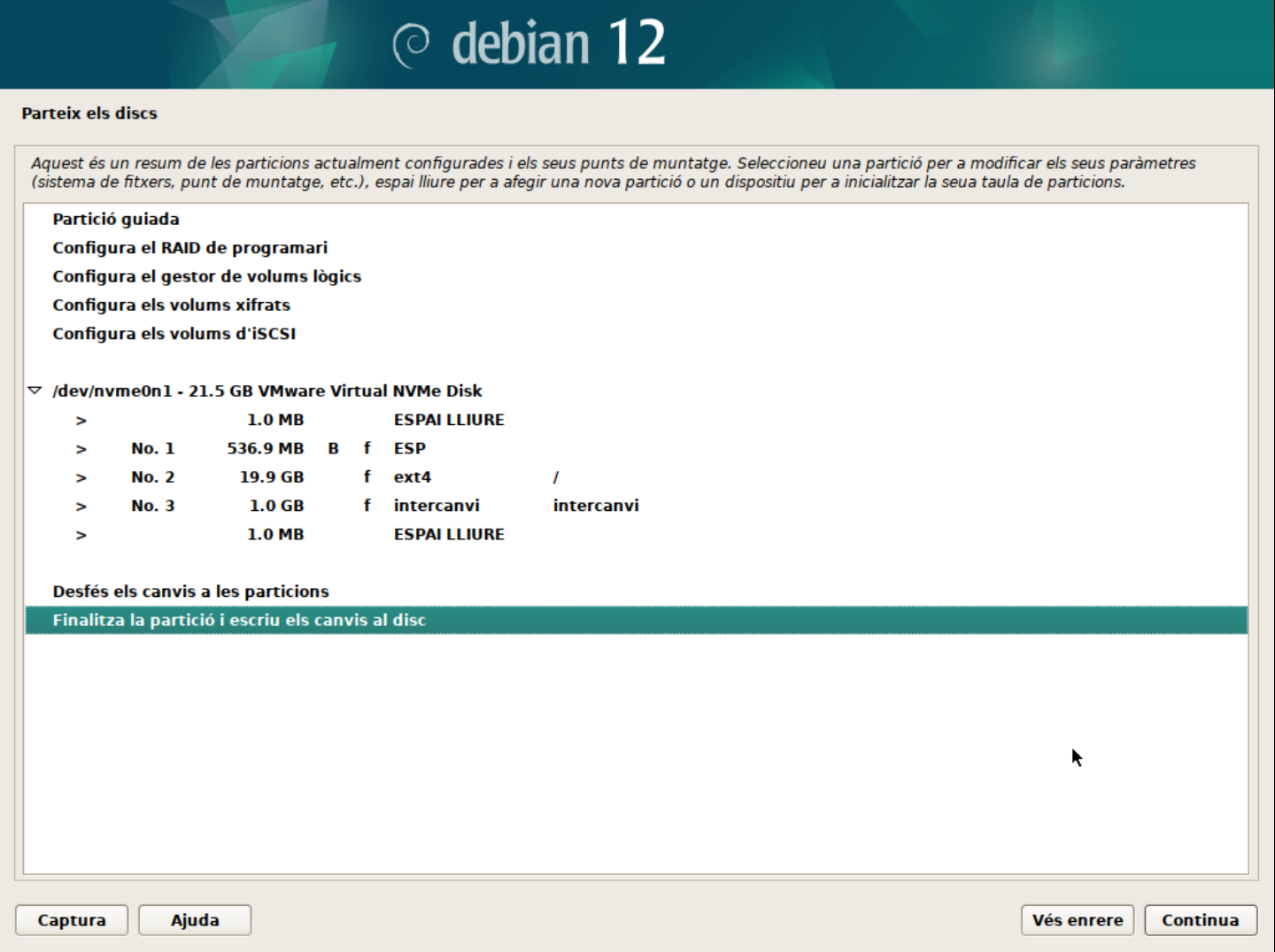
- Confirmeu els canvis. En aquest punt, el sistema crearà les particions necessàries:
- La primera partició serà la partició
/booton es guardaran els fitxers de boot. - La segona partició serà la partició
/on es guardaran els fitxers del sistema. - La tercera partició serà la partició de swap on es guardaran les dades de la memòria virtual.
- La primera partició serà la partició
👁️ Observació:
En aquest punt es poden fer moltes personalitzacions com ara:
- Configurar un sistema RAID.
- Configurar un sistema LVM.
- Configurar un sistema de xifrat. Tots aquests temes els veurem més endavant en el curs.
- Escriu els canvis al disc.
-
Espera que s'instal·li el sistema.
-
Configura el gestor de paquets.
- Analitzar els discos de la instal·lació. Aquest pas permet seleccionar els discos on es troben els paquets d'instal·lació. Normalment, aquest pas no cal modificar-lo.
-
Configura el gestor de paquets. En aquest cas, seleccionarem el servidor de paquets més proper a la nostra ubicació.
-
Filtrar els servidors de paquets per ubicació.
-
Seleccionar el servidor de paquets.
👀 Nota:
A vegades, els servidors de paquets poden estar saturats o no funcionar correctament. En aquest cas, podeu seleccionar un servidor alternatiu o provar més tard.
-
-
Configura el proxy. Si esteu darrere d'un proxy, podeu configurar-lo en aquest pas.
ℹ️ Què és un proxy?
Un proxy és un servidor intermediari entre el vostre sistema i Internet. Aquest servidor pot ser utilitzat per controlar l'accés a Internet, per protegir la vostra privacitat o per accelerar la connexió a Internet. Les peticions de connexió a Internet es fan a través del servidor proxy, que actua com a intermediari i reenvia les peticions al servidor de destinació. Per exemple, en una empresa, el proxy pot ser utilitzat per controlar l'accés a Internet dels empleats i protegir la xarxa interna de possibles amenaces.
-
Espera que s'instal·lin els paquets.
-
Configura el paquet
popularity-contest.- Aquest paquet permet enviar informació anònima sobre els paquets instal·lats al servidor de Debian per millorar la selecció de paquets i la qualitat dels paquets. Podeu seleccionar si voleu participar en aquest programa o no.
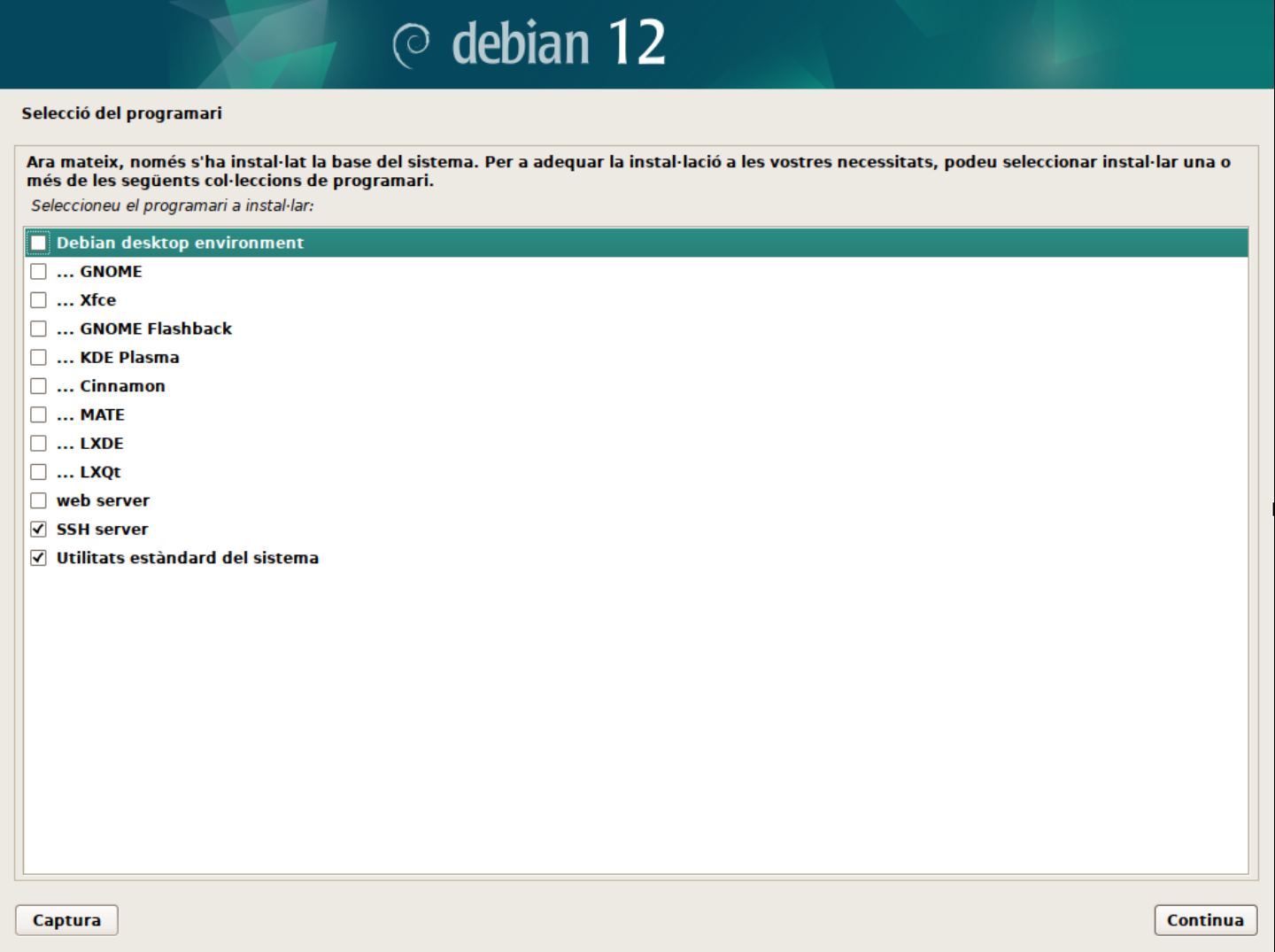
-
Selecció de programari. En aquest punt podeu seleccionar si voleu un servidor en mode text o amb interfície gràfica. També us permet seleccionar si voleu instal·lar els serveis web i ssh al servidor i finalment si voleu les utilitats estàndard del sistema. Aquestes opcions les anirem modifciant en funció dels laboratoris que realitzarem. Per defecte, seleccionarem el servidor en mode text, el servei SSH activat i les utilitats estàndard del sistema.
ℹ️ Què és un servidor en mode text?
Un servidor en mode text és un servidor que no té una interfície gràfica. Això significa que tota la interacció amb el servidor es fa a través de la línia de comandes. Aquest tipus de servidor és molt comú en entorns de producció, ja que consumeix menys recursos i és més segur que un servidor amb interfície gràfica.
ℹ️ Què és el servei SSH?
El servei SSH (Secure Shell) és un protocol de xifratament que permet connectar-se de forma segura a un servidor remot. Aquest servei és molt utilitzat per administrar servidors a distància, ja que permet accedir al servidor de forma segura i xifratada.
-
Espera que s'instal·li el programari.
-
Instal·lació acabada. Un cop finalitzada la instal·lació, el sistema es reiniciarà i podreu accedir al GRUB per seleccionar el sistema operatiu.
-
El GRUB us permet accedir al sistema operatiu. En aquest cas, seleccionarem Debian GNU/Linux. La resta d'opcions les veurem més endavant en el curs.
ℹ️ Què és el GRUB?
Com veurem al capítol de Booting, el GRUB és un gestor d'arrencada que permet seleccionar el sistema operatiu que volem iniciar. Aquest gestor és molt útil en sistemes amb múltiples sistemes operatius o múltiples versions del mateix sistema operatiu.
-
Inicieu sessió amb l'usuari i la contrasenya que heu configurat durant la instal·lació.

-
Tanqueu la sessió amb la comanda
exit. -
Inicieu sessió amb l'usuari
rooti la contrasenya que heu configurat durant la instal·lació.
Hostname
Els administradors de sistemes acostumen a administrar múltiples servidors i dispositius. Per tant, és important identificar cada dispositiu amb un nom únic per facilitar la gestió i la comunicació entre ells. El nom d'un dispositiu s'anomena nom d'amfitrió o hostname. Per a gestionar el nom d'amfitrió d'un sistema Linux, utilitzarem la comanda hostnamectl.
Comprovar el nom d'amfitrió actual
Per comprovar el nom d'amfitrió actual del vostre sistema, podeu utilitzar la comanda hostnamectl:
hostnamectl
Aquesta comanda us mostrarà informació sobre el vostre sistema, incloent el nom d'amfitrió actual.
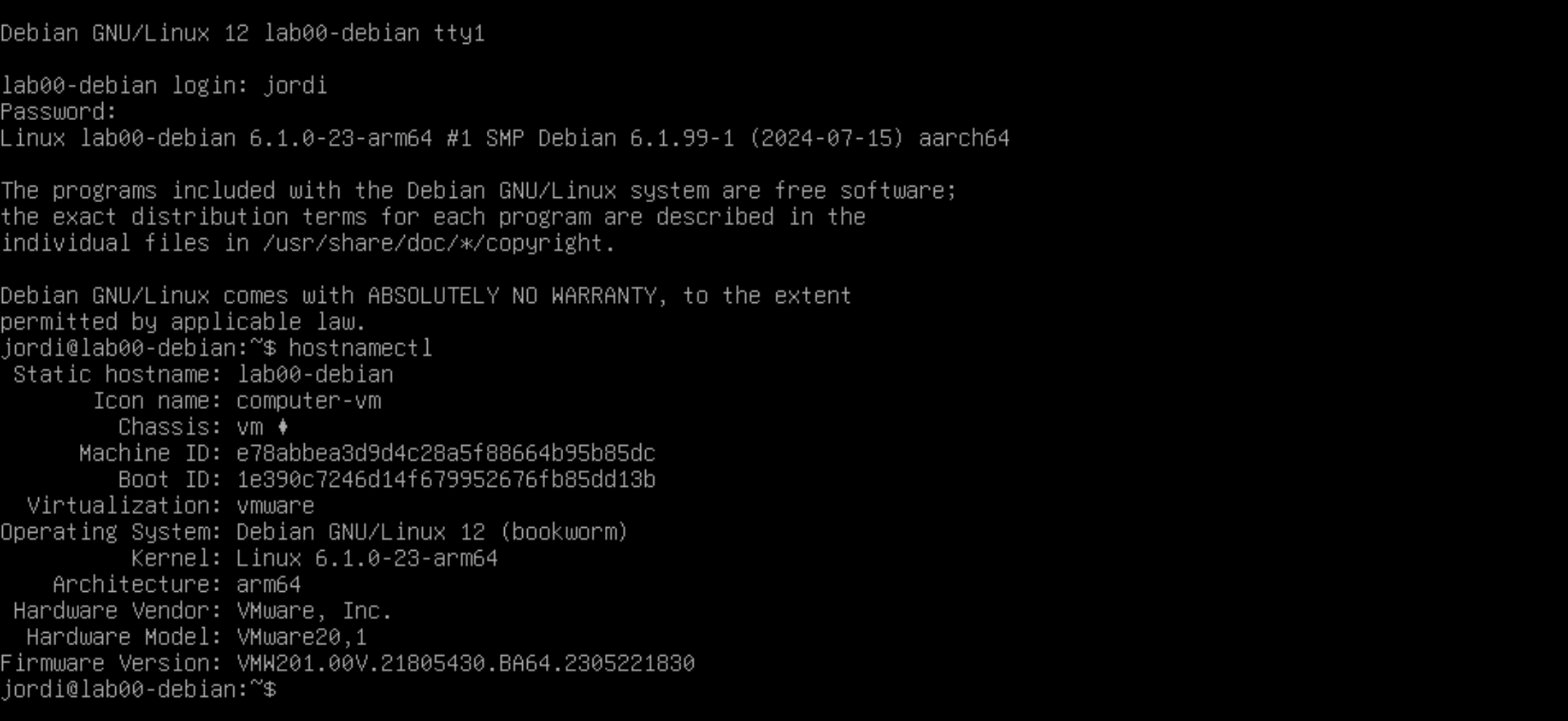
A part del nom d'amfitrió, també podeu veure informació com la versió del sistema operatiu, el kernel, la data i l'hora actuals, etc.
Modificar el nom d'amfitrió
Per canviar el nom d'amfitrió del vostre sistema, podeu utilitzar la comanda hostnamectl amb l'opció set-hostname. Per exemple, si voleu canviar el nom d'amfitrió a nou-nom, executeu la següent comanda:
hostnamectl set-hostname nou-nom
Aquesta comanda canviarà el nom d'amfitrió del vostre sistema a nou-nom. Si voleu comprovar que el canvi s'ha aplicat correctament, torneu a executar la comanda hostnamectl. Per aplicar el canvi, sortiu de la sessió actual exit i torneu a iniciar sessió.

🔗 Recordatori:
Cal tenir en compte que aquesta comanda requereix permisos d'administrador. Per tant, és possible que hàgiu de precedir la comanda amb
sudoo executar-la com a usuariroot.
Nom en xarxa
Hi ha dos maneres d'identificar un servidor o dispositiu connectat en una xarxa, o bé utilitzant la direcció IP del dispositiu o bé utilitzant el seu nom d'amfitrió. Per poder resoldre el nom d'amfitrió correctament, cal configurar-lo correctament en el sistema o disposar d'un servidor DNS que pugui resoldre el nom d'amfitrió en una adreça IP.
Network Address Translation (NAT)
Per defecte, VMWare utilitza una xarxa NAT per connectar les màquines virtuals. Per fer-ho, VMWare crea una xarxa privada a la qual es connecten les màquines virtuals i utilitza la xarxa de l'amfitrió per connectar-se a Internet. Això permet a les màquines virtuals connectar-se a Internet a través de l'amfitrió sense necessitat de configurar una xarxa addicional. Ara bé, això també significa que les màquines virtuals utilitzen una adreça IP privada que no és accessible des de l'exterior. Tot i això, aquesta configuració la podeu canviar si cal. Però, pels nostres laboratoris, aquesta configuració és suficient.
ℹ️ Què és NAT?
La xarxa NAT (Network Address Translation) és una tècnica que permet a diversos dispositius connectar-se a Internet utilitzant una única adreça IP pública. Aquesta tècnica és àmpliament utilitzada per a xarxes domèstiques i petites empreses per permetre a diversos dispositius connectar-se a Internet sense necessitat de disposar d'una adreça IP pública per a cada dispositiu.
Ús de la direcció IP
La direcció IP és una forma única d'identificar un dispositiu en una xarxa. Cada dispositiu connectat a una xarxa ha d'estar configurat amb una adreça IP única per poder comunicar-se amb altres dispositius. Les adreces IP poden ser dinàmiques (assignades per un servidor DHCP) o estàtiques (configurades manualment).
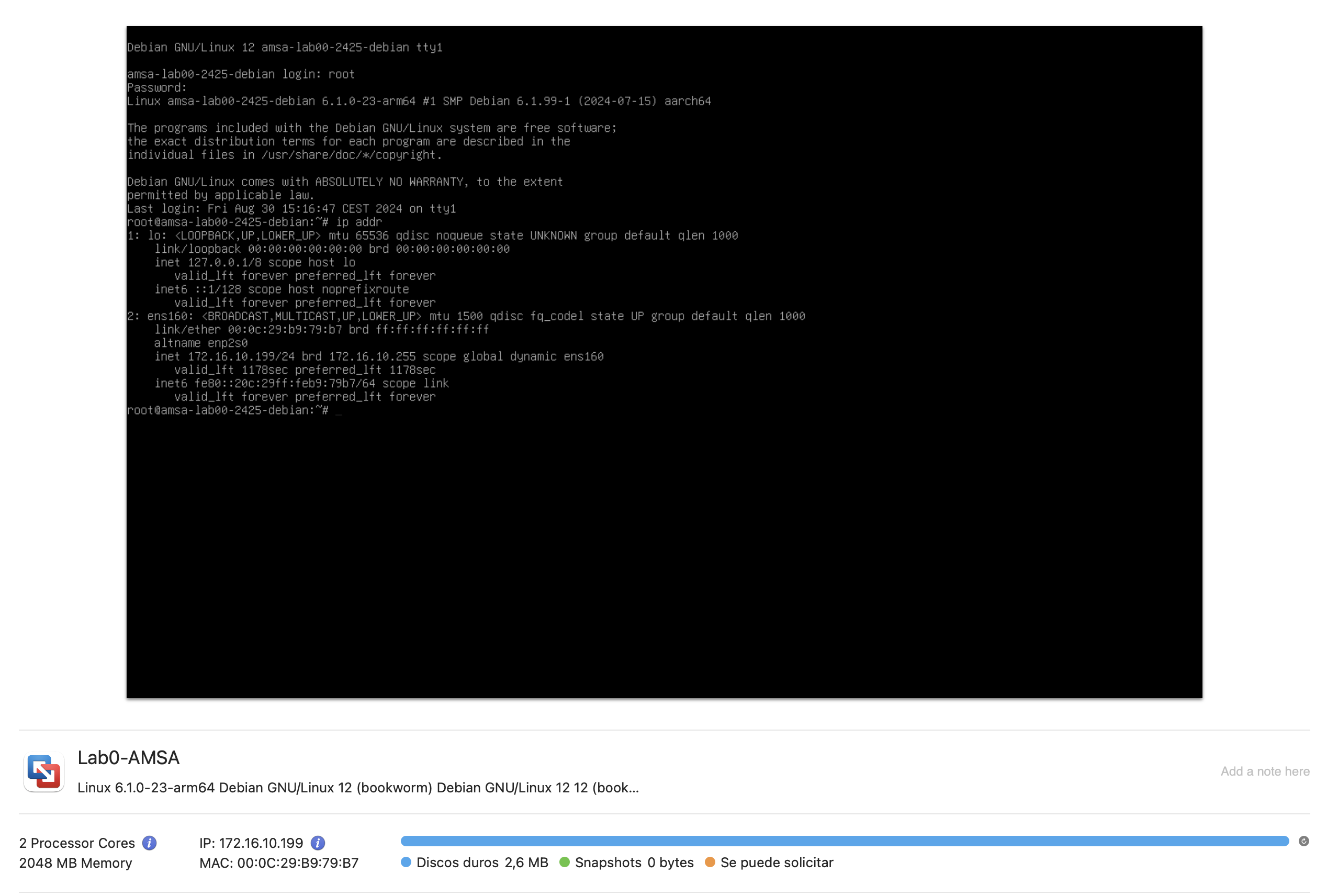
Quan es crea una màquina virtual utilitzant el programari VMWare per defecte, la màquina virtual obté una adreça IP a través del servidor DHCP de VMWare. Aquesta adreça IP es pot utilitzar per accedir a la màquina virtual des de l'amfitrió o altres dispositius de la xarxa.
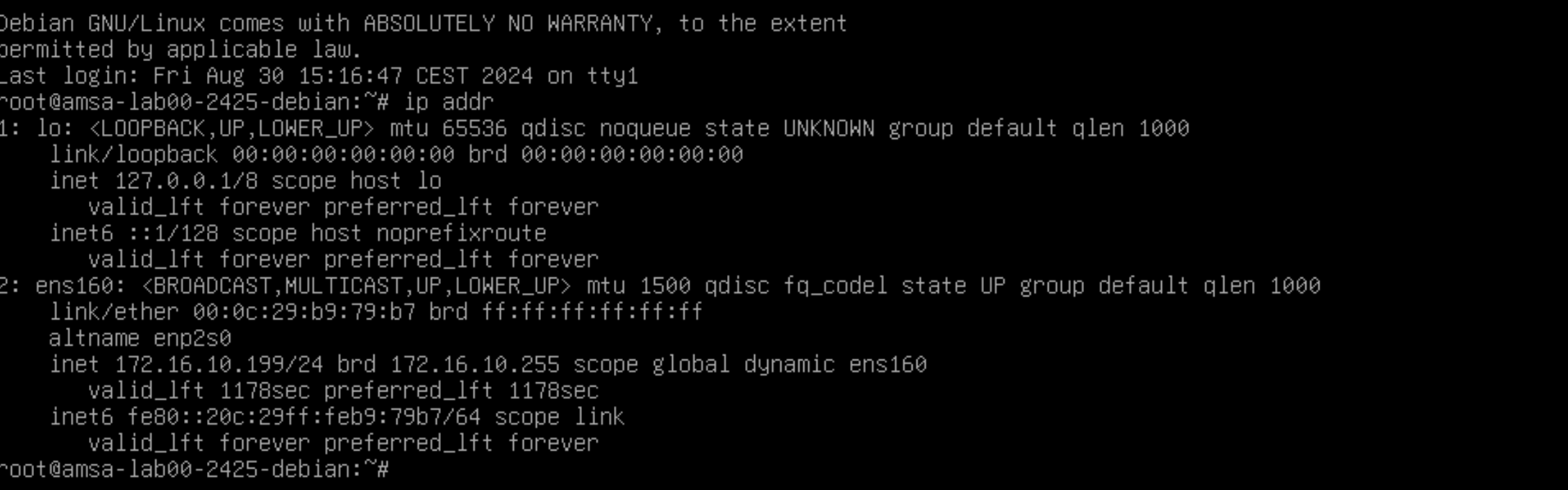
Per obtenir aquesta informació podeu consultar la interficie gràfica de VMWare o bé utilitzar la comanda ip addr en la terminal de la màquina virtual.
-
Interfície gràfica de VMWare:
-
Comanda
ip addr:ip addrAquesta comanda us mostrarà la informació de la interfície de xarxa de la màquina virtual, incloent la seva adreça IP.
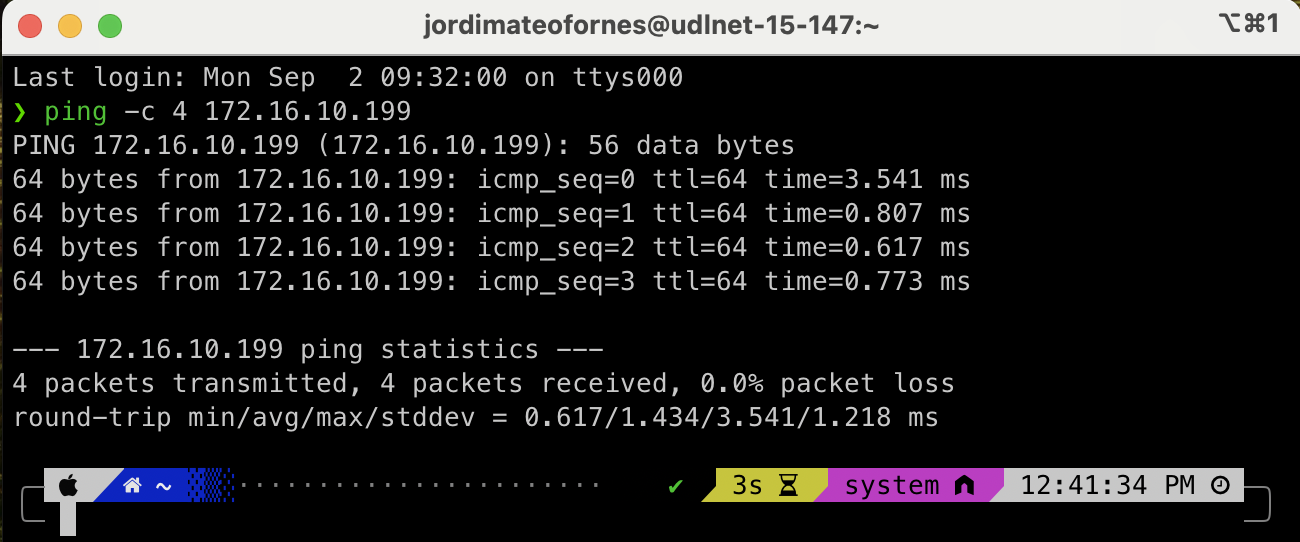
Podeu testar la connectivitat de la màquina virtual amb l'amfitrió o altres dispositius de la xarxa utilitzant la comanda ping. Per exemple, per provar la connectivitat amb l'amfitrió, podeu utilitzar la següent comanda:
ping -c 4 <adreça IP de l'amfitrió>
Ús del nom d'amfitrió
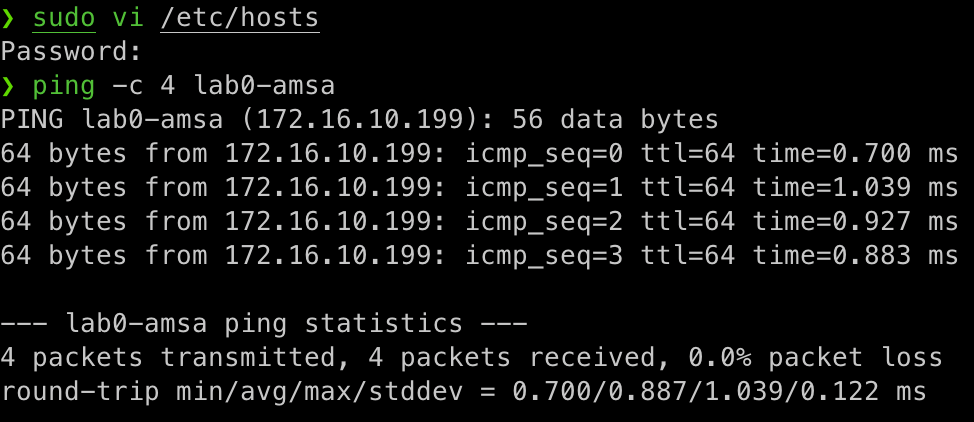
El nom d'amfitrió és una forma més fàcil de recordar i identificar un dispositiu en una xarxa. En lloc d'utilitzar una adreça IP, podeu utilitzar un nom d'amfitrió per connectar-vos a un dispositiu. Per exemple, en lloc de connectar-vos a 172.16.10.199, podeu connectar a lab0-amsa.
Per fer-ho, cal modificar la configuració del vostre ordinador local perquè pugui resoldre el nom d'amfitrió correctament. Això es pot fer afegint una entrada al fitxer /etc/hosts amb el nom d'amfitrió i la seva adreça IP. Per exemple afegint la següent línia al fitxer /etc/hosts:
# /etc/hosts
172.16.10.199 lab0-amsa
- Windows:
C:\Windows\System32\drivers\etc\hosts - Linux:
/etc/hosts - macOS:
/etc/hosts
Un cop afegida aquesta entrada, podeu provar la connectivitat amb la màquina virtual utilitzant el nom d'amfitrió:
ping -c 4 lab0-amsa
Una forma alternativa de resoldre el nom d'amfitrió és utilitzar un servidor DNS. Un servidor DNS és un servidor que tradueix els noms d'amfitrió en adreces IP i viceversa. Aquest és el cas de la majoria de xarxes corporatives i d'Internet, on es fa servir un servidor DNS per resoldre els noms de domini.
Connexió SSH i SFTP
En els nostres laboratoris, utilitzarem màquines virtuals per simular els nostres servidors. Per tant, sempre tindreu accés físic a les màquines virtuals a través de la interfície gràfica de VMWare. No obstant això, en un entorn de producció, no sempre tindreu accés físic als servidors o no us resultarà pràctic anar físicament a cada servidor per gestionar-los. Per tant, és important tenir una forma de connectar-vos als servidors de forma remota per poder gestionar-los de manera eficient.
ℹ️ Què és SSH?
SSH (Secure Shell) és un protocol de xarxa que permet als usuaris connectar-se a un dispositiu remot de forma segura. SSH utilitza una connexió xifrada per autenticar els usuaris i protegir les dades que es transmeten entre els dispositius. Això fa que SSH sigui una eina molt útil per connectar-se a servidors remots de forma segura.
ℹ️ Què és SFTP?
SFTP (SSH File Transfer Protocol) és un protocol de transferència de fitxers que permet als usuaris transferir fitxers de forma segura entre dos dispositius. SFTP utilitza SSH per autenticar els usuaris i xifrar les dades que es transmeten entre els dispositius. Això fa que SFTP sigui una eina molt útil per transferir fitxers de forma segura entre servidors remots.
ℹ️ Què és secure copy (SCP)?
SCP (Secure Copy) és una eina que permet als usuaris copiar fitxers de forma segura entre dos dispositius utilitzant SSH. SCP utilitza SSH per autenticar els usuaris i xifrar les dades que es transmeten entre els dispositius.
Connexió SSH entre la vostra màquina i la màquina virtual
Per connectar-vos a una màquina virtual utilitzant SSH, necessitareu l'adreça IP de la màquina virtual o bé el hostname de la màquina virtual. A més, necessitareu un client SSH instal·lat al vostre sistema local. A continuació, us mostrem com connectar-vos a una màquina virtual utilitzant SSH:
-
Mac/Linux:
ssh <usuari>@<adreça IP o hostname>
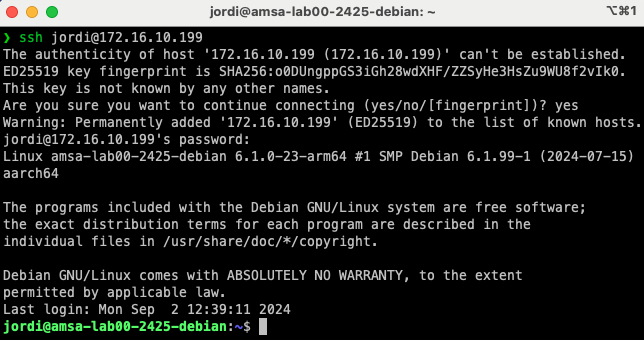
On: <usuari> és el nom d'usuari amb el qual voleu connectar-vos a la màquina virtual i <adreça IP o hostname> és l'adreça IP o el hostname de la màquina virtual a la qual voleu connectar-vos.
Un cop connectats, podreu interactuar amb la màquina virtual com si estiguéssiu connectats físicament a la màquina. Per sortir de la sessió SSH, executeu la comanda exit.
- Windows: Obrir una sessió de PowerShell i executar la comanda anterior. També podeu utilitzar un client SSH com PuTTY.
ℹ️ Què és el fingerprint que es mostra quan connecteu per primera vegada a un servidor SSH?
El fingerprint és una empremta digital única que identifica un servidor SSH. Quan connecteu per primera vegada a un servidor SSH, el vostre client SSH us mostrarà el fingerprint del servidor perquè pugueu verificar que esteu connectant-vos al servidor correcte. Això us protegeix contra atacs de suplantació de servidor.
😵💫 Troubleshooting:
Si una IP d'una màquina virtual a la qual havíeu accedit prèviament es reassigna a una altra màquina virtual i intenteu accedir a la màquina virtual original, el client SSH mostrarà un missatge d'advertència. Això succeeix perquè el fingerprint del servidor ha canviat. Quan connecteu per primera vegada a un servidor SSH, el vostre client SSH emmagatzema aquest fingerprint en el fitxer
~/.ssh/known_hostsper a futures referències.Si el fingerprint del servidor canvia (per exemple, perquè l'adreça IP s'ha reassignat a una altra màquina virtual), el client SSH detectarà aquesta discrepància i mostrarà un missatge d'advertència per protegir-vos contra possibles atacs de suplantació de servidor. Aquest missatge us informa que el servidor al qual esteu intentant connectar-vos no coincideix amb el fingerprint emmagatzemat.
Per resoldre aquest problema i poder connectar-vos al servidor, podeu eliminar l'entrada del servidor del fitxer
~/.ssh/known_hosts. Això permetrà al client SSH acceptar el nou fingerprint i establir la connexió sense mostrar l'advertència.Per resoldre aquest problema, simplement elimineu l'entrada del servidor del fitxer
~/.ssh/known_hostsi torneu a intentar connectar-vos al servidor. En el sistema operatiu Windows, el fitxerknown_hostses troba a la carpetaC:\Users\<usuari>\.ssh\known_hosts.
Transferència de fitxers amb SFTP
Per transferir fitxers entre la vostra màquina local i la màquina virtual utilitzant SFTP, necessitareu l'adreça IP de la màquina virtual o bé el hostname de la màquina virtual. A més, necessitareu un client SFTP instal·lat al vostre sistema local. A continuació, us mostrem com transferir fitxers entre la vostra màquina local i la màquina virtual utilitzant SFTP:
-
Mac/Linux:
sftp <usuari>@<adreça IP o hostname>:<ruta>On:
<ruta>és la ruta al directori de la màquina virtual on voleu transferir els fitxers.- Els fitxers es transferiran al directori actual de la vostra màquina local.
Un cop connectats, podeu utilitzar les comandes
putigetper transferir fitxers entre la vostra màquina local i la màquina virtual. Si voleu transferir un directori sencer, podeu utilitzar la comandaput -roget -r. Per acabar la sessió SFTP, executeu la comandaexit. -
Windows: Obrir una sessió de PowerShell i executar la comanda anterior. També podeu utilitzar un client SFTP com WinSCP.
Si voleu fer servir SCP en lloc de SFTP, podeu utilitzar la comanda scp en lloc de sftp. La sintaxi de la comanda scp és similar a la de la comanda cp de Linux. Per exemple, per copiar un fitxer de la vostra màquina local a la màquina virtual, executeu la següent comanda:
scp <fitxer> <usuari>@<adreça IP o hostname>:<ruta>
on:
<fitxer>és el fitxer que voleu copiar.<ruta>és la ruta al directori de la màquina virtual on voleu copiar el fitxer.- El fitxer es copiarà al directori especificat de la màquina virtual.
- Si voleu copiar un directori sencer, podeu utilitzar l'opció
-r.
Exemple pràctic de transferència de fitxers
-
Crear un fitxer
fitxer.txta la vostra màquina local.echo "Aquest és un fitxer de prova" > fitxer.txt -
Copia el fitxer
fitxer.txta la màquina virtual a la ruta/home/usuari.- Amb scp:
scp fitxer.txt jordi@172.16.10.199:/home/jordi- Amb sftp:
sftp jordi@172.16.10.199:/home/jordi put fitxer.txt -
Edita el fitxer
fitxer.txta la màquina virtual.echo "Aquest és un fitxer de prova editat" > fitxer.txt -
Copia el fitxer
fitxer.txtde la màquina virtual a la vostra màquina local.sftp jordi@172.16.10.199:/home/jordi get fitxer.txt
Scripting
En aquest laboratori es realitzaran tasques de scripting amb Bash i Awk. Aquests llenguatges són molt utilitzats en l'administració de sistemes GNU/Linux per automatitzar tasques repetitives.
Objectius
- Repassar els conceptes bàsics de Bash estudiats al curs de Sistemes Operatius.
- Aprendre a utilitzar Awk per processar fitxers de text.
- Conèixer les diferències entre Bash i Awk.
- Combina Bash i Awk per a realitzar tasques més complexes.
Continguts
Activitat
Heu d’incorporar al repositori cinc exemples diferents, ordenats de menor a major complexitat. Cada exemple ha de ser únic i ha d’incloure una explicació detallada del que fa el codi, així com versions tant en bash com en AWK. Si l’exemple que tenies pensat ja ha estat implementat per un company, hauràs de buscar-ne un de nou. Per tant, és recomanable que revisis els exemples que ja han publicat els teus companys abans de publicar els teus propis exemples.
Rúbriques d'avaluació
Presentació d'un Pull Request amb els scripts realitzats: 100%
- Format: Markdown
- Fitxer:
Scripts/awk-repo.md
En aquest laboratori s'avaluarà la capacitat de l'estudiant per a generar nous scripts en Bash i Awk. Aquest scripts hauran de ser funcionals i correctes, així com també hauran de ser ben documentats.
| Criteris d'avaluació | Excel·lent (5) | Notable(3-4) | Acceptable(1-2) | No Acceptable (0) |
|---|---|---|---|---|
| Contingut | El contingut és molt complet i detallat. S'han cobert tots els aspectes de la tasca. | El contingut és complet i detallat. S'han cobert la majoria dels aspectes de la tasca. | El contingut és incomplet o poc detallat. Falten alguns aspectes de la tasca. | El contingut és molt incomplet o inexistent. |
| Operacionals | Els scripts generats són funcionals i correctes. No hi ha errors. | Els scripts generats són funcionals i correctes. Hi ha pocs errors. | Els scripts generats són funcionals i correctes. Hi ha errors. | Els scripts generats no són funcionals o correctes. |
| Creatius | Els scripts generats són originals i no s'han copiat de cap font. | Els scripts generats són originals i no s'han copiat de cap font. | Els scripts generats són originals i no s'han copiat de cap font. | Els scripts generats són còpia d'altres scripts. |
| Documentació | Els scripts estan ben documentats i s'ha explicat el seu funcionament. | Els scripts estan ben documentats i s'ha explicat el seu funcionament. | Els scripts estan documentats. Falta explicar el seu funcionament. | Els scripts no estan documentats. |
| Presentació | Els scripts s'han lliurat en un format adequat i s'han seguit les indicacions del professor. | Els scripts s'han lliurat en un format adequat i s'han seguit les indicacions del professor. | Els scripts s'han lliurat en un format adequat. Falten algunes indicacions del professor. | Els scripts no s'han lliurat en un format adequat. |
| Didàctics | Els scripts són fàcils de seguir i entenent per a qualsevol persona. | Els scripts són fàcils de seguir i entenent per a qualsevol persona. | Els scripts són fàcils de seguir i entenent per a qualsevol persona. | Els scripts són difícils de seguir i entenent. |
| Optimització | Els scripts són eficients i no es poden millorar. | Els scripts són eficients i no es poden millorar. | Els scripts són eficients i es poden millorar. | Els scripts no són eficients. |
Bash
En aquest laboratori repassarem els conceptes bàsics de Bash, el llenguatge de programació de scripts més utilitzat en sistemes GNU/Linux. Aquest laboratori està enfocat en repassar els conceptes bàsics que vau estudiar en l'assignatura de Sistemes Operatius.
Contextualització
En aquest laboratori crearem una aplicació per gestionar una llista de pokemons. Aquesta aplicació haurà de permetre afegir, llistar, eliminar i buscar pokemons. A més a més, haureu de fer servir un fitxer per emmagatzemar la informació dels pokemons.
Preparació
- Entorn de treball: Màquina virtual amb una distribució GNU/Linux instal·lada pot ser Debian o AlmaLinux.
Objectius
- Repassar els conceptes bàsics de Bash.
Tasques
-
Creeu un esquelet pel vostre script Bash.
#!/bin/bash # Constants # Functions # Main return 0 -
Implementeu una constant
POKEDEX_FILEamb el nom del fitxer on emmagatzemareu la informació dels pokemons.POKEDEX_FILE="pokedex.txt" -
Implementeu un menu amb la sintaxi
caseque permeti executar les següents comandes:help,list,search,deleteinew.case $1 in help) pokedex_help ;; list) pokedex_list ;; search) pokedex_search $2 ;; delete) pokedex_delete $2 ;; new) pokedex_new $2 $3 $4 $5 $6 $7 ;; *) echo "Comanda no trobada." pokedex_help ;; esac -
Implementeu la funció
pokedex_helpque mostri per pantalla les instruccions d'ús del script.function pokedex_help() { echo "Ús: ./pokedex.sh <comanda> <arguments>" echo "Comandes:" echo " list: Llistar pokemons" echo " search <name>: Buscar pokemon" echo " delete <name>: Eliminar pokemon" echo " new <name> <type> <hp> <attack> <defense> <speed>: Afegir pokemon" } -
Implementeu la funció
pokedex_listque llegeixi el fitxerPOKEDEX_FILEi mostri per pantalla la llista de pokemons.- Podeu fer servir la comanda
catper llegir el fitxerPOKEDEX_FILE.
function pokedex_list() { cat $POKEDEX_FILE }- Assegureu-vos que existeix el fitxer
POKEDEX_FILE.
if [[ ! -f $POKEDEX_FILE ]]; then echo "El fitxer $POKEDEX_FILE no existeix." return 1 fi - Podeu fer servir la comanda
-
Implementeu la funció
pokedex_search <name>que llegeixi el fitxerPOKEDEX_FILEi mostri per pantalla la informació del pokemon amb nom<name>.- Podeu fer servir la comanda
grepper buscar el pokemon amb nom<name>.
function pokedex_search() { grep $1 $POKEDEX_FILE }- Assegureu-vos que la funció
pokedex_searchrep un argument.
if [[ -z $1 ]]; then echo "Has d'indicar el nom del pokemon." echo "Ús: ./pokedex.sh search <name>" return 1 fi - Podeu fer servir la comanda
-
Implementeu la funció
pokedex_delete <name>que elimini el pokemon amb nom<name>del fitxerPOKEDEX_FILE.- Podeu fer servir la comanda
sedper eliminar el pokemon amb nom<name>.
function pokedex_delete() { sed -i "/$1/d" $POKEDEX_FILE }- Assegureu-vos que la funció
pokedex_deleterep un argument.
if [[ -z $1 ]]; then echo "Has d'indicar el nom del pokemon." echo "Ús: ./pokedex.sh delete <name>" return 1 fi - Podeu fer servir la comanda
-
Implementeu la funció
pokedex_new <name> <type> <hp> <attack> <defense> <speed>que permet afegir un nou pokemon a la pokedex.- Podeu fer servir la comanda
echoper afegir el nou pokemon al fitxerPOKEDEX_FILE.
function pokedex_new() { echo "$1 $2 $3 $4 $5 $6" >> $POKEDEX_FILE }- Assegureu-vos que la funció
pokedex_newrep tots els arguments necessaris.
if [[ -z $1 || -z $2 || -z $3 || -z $4 || -z $5 || -z $6 ]]; then echo "Has d'indicar el nom, tipus, hp, attack, defense i speed del pokemon." echo "Ús: ./pokedex.sh new <name> <type> <hp> <attack> <defense> <speed>" return 1 fi - Podeu fer servir la comanda
Introducció al llenguatge AWK
Objectius
- Entendre la sintaxi bàsica d'AWK.
- Aprendre a utilitzar AWK per processar fitxers de text.
- Entendre les diferències entre AWK i BASH.
Prerequisits
- Una màquina virtual amb sistema operatiu Linux, preferiblement AlmaLinux 9.4. Es recomana accedir a la màquina virtual mitjançant SSH.
Què és AWK?
AWK és un llenguatge de programació potent i versàtil, dissenyat específicament per a l’anàlisi de patrons i el processament de text. La seva funció principal és processar fitxers de text de manera eficient, permetent la transformació de dades, la generació d’informes i la filtració de dades.
Pràcticament tots els sistemes Unix disposen d’una implementació d’AWK. Això inclou sistemes operatius com GNU/Linux, macOS, BSD, Solaris, AIX, HP-UX, entre d’altres. Per consultar el manual d’AWK, pots utilitzar la comanda man awk. Per consultar la versió d’AWK instal·lada al teu sistema, pots utilitzar la comanda awk -W version.
AWK es caracteritza per ser compacte, ràpid i senzill, amb un llenguatge d’entrada net i comprensible que recorda al llenguatge de programació C. Disposa de construccions de programació robustes que inclouen if/else, while, do/while, entre d’altres. L’eina AWK processa una llista de fitxers com a arguments. En cas de no proporcionar fitxers, AWK llegeix de l’entrada estàndard, permetent així la seva combinació amb pipes per a operacions més complexes.
Utilització de l'eina AWK
Pots trobar tota la informació sobre el funcionament de l’eina AWK a la pàgina de manual. Per exemple, per obtenir informació sobre la comanda awk, pots utilitzar la comanda man awk. Aquesta comanda et proporcionarà tota la informació necessària per utilitzar l’eina AWK.
-
Pots utilitzar l’eina amb el codi escrit directament acció-awk a la línia de comandes o combinada en un script:
awk [-F] '{acció-awk}' [ fitxer1 ... fitxerN ] -
També pots utilitzar l’eina amb tota la sintaxi awk guardada en un fitxer script-awk des de la línia de comandes o combinada amb altres scripts:
awk [-F] -f script-awk [ fitxer1 ... fitxerN ]
En aquests exemples, [-F] és una opció que permet especificar el caràcter delimitador de camps, {acció-awk} és el codi AWK que vols executar, i [ fitxer1 ... fitxerN ] són els fitxers d’entrada que AWK processarà. Si no s’especifica cap fitxer, AWK llegirà de l’entrada estàndard.
Fitxer de Dades d'Exemple per utilitzar en aquest Laboratori
En aquest laboratori, farem servir un fitxer de dades específic com a conjunt de dades d’exemple. Aquest fitxer representa una pokedex i es pot obtenir amb la següent comanda:
curl -O https://gist.githubusercontent.com/armgilles/194bcff35001e7eb53a2a8b441e8b2c6/raw/92200bc0a673d5ce2110aaad4544ed6c4010f687/pokemon.csv
Aquest fitxer conté 801 línies (800 pokemons + 1 capçalera) i 13 columnes. Les columnes són les següents:
- #: Número de pokémon
- Name: Nom del pokémon
- Type 1: Tipus 1 del pokémon
- Type 2: Tipus 2 del pokémon
- Total: Total de punts de tots els atributs
- HP: Punts de vida
- Attack: Atac
- Defense: Defensa
- Sp. Atk: Atac especial
- Sp. Def: Defensa especial
- Speed: Velocitat
- Generation: Generació
- Legendary: Llegendari (0: No, 1: Sí)
Per comprovar aquestes dades, podem fer servir les següents comandes:
-
Utilitzeu la comanda
wcper comptar el nombre de línies del fitxer:wc -l pokemon.csv -
Utilitzeu la comanda
headper mostrar les primeres 10 línies del fitxer:head pokemon.csv -
Utilitzeu les comandes
wciheadper comptar el nombre de columnes del fitxer. Recordeu que les columnes estan separades per comes:head -1 pokemon.csv | tr ',' '\n' | wc -l
Awk - Bàsic
Estrucutra Bàsica d'AWK
El llenguatge AWK s'organitza amb duples de la forma patró { acció }. El patró pot ser una expressió regular o una condició lògica. L’acció és el que es vol realitzar amb les línies que compleixen el patró. Per tant, AWK processa els fitxers línia per línia. Per cada línia del fitxer, AWK avalua el patró. Si el patró és cert, executa l’acció. Si el patró és fals, passa a la següent línia.
Per exemple, si volem imprimir totes les línies d'un fitxer (acció) que contenten una expressió regular definida a regex (patró), podem fer servir la següent sintaxi:
awk '/regex/ { print }' fitxer
Observeu que utilitzem el caràcter / per indicar que el patró és una expressió regular.
A més, AWK ens permet utilitzar una estructura de control BEGIN i END. La clàusula BEGIN s'executa abans de processar qualsevol línia i la clàusula END s'executa després de processar totes les línies. Aquestes clausules són opcionals i no són necessàries en tots els casos.
BEGIN { acció }
patró { acció }
END { acció }
Per exemple, si volem indicar que estem començant a processar un fitxer, podem fer servir la clàusula BEGIN. I si volem indicar que hem acabat de processar el fitxer, podem fer servir la clàusula END. A continuació, teniu un exemple de com utilitzar les clàusules BEGIN i END:
awk '
BEGIN { print "Començant a processar el fitxer..." }
/regex/ { print }
END { print "Finalitzant el processament del fitxer..." }
' fitxer
Aprenent a utilitzar AWK amb Exemples
Sintaxis Bàsica
En aquesta secció veurem com podem utiltizar AWK per substituir algunes comandes bàsiques de bash com cat, grep, cut.
cat
La comanda cat ens permet mostrar el contingut d'un fitxer. Per exemple, per mostrar el contingut del fitxer pokemon.csv:
cat pokemon.csv
Podem fer servir AWK per fer el mateix. Per exemple, per mostrar el contingut del fitxer pokemon.csv:
awk '{print}' pokemon.csv
on {print} és l'acció que volem realitzar. En aquest cas, volem imprimir totes les línies del fitxer. Això és equivalent a la comanda cat.
AWK també ens permet acompanyar l'acció amb variables. Per exemple, la variable $0 conté tota la línia. Per tant, podem utilitzar la variable $0 per imprimir totes les línies del fitxer:
awk '{print $0}' pokemon.csv
Nota: AWK processa els fitxers línia per línia. Per cada línia del fitxer, AWK avalua l'acció. Es a dir, amb la comanda awk '{print $0}' pokemon.csv estem indicant que per cada línia del fitxer, imprimeixi la línia sencera. Per tant, aquesta comanda és equivalent a la comanda cat.
Podeu comparar les sortides de les comandes cat i awk per assegurar-vos que són les mateixes utilitzant la comanda diff:
diff <(cat pokemon.csv) <(awk '{print $0}' pokemon.csv)
grep
La comanda grep ens permet cercar patrons en un fitxer. Per exemple, per mostrar totes les línies que contenen la paraula "Char" al fitxer pokemon.csv:
grep Char pokemon.csv
Podem fer servir AWK per fer el mateix. Per exemple, per mostrar totes les línies que contenen la paraula "Char" al fitxer pokemon.csv:
awk '/Char/ {print}' pokemon.csv
on /Char/ és el patró que volem cercar. Per tant, tenim un patró de cerca i una acció a realitzar. En aquest cas, estem cercant linia per linia la paraula "Char" i si la trobem, imprimim tota la línia. Això és equivalent a la comanda grep.
Una confusió comuna es pensar que l'expressió /Char/ indica que la línia comença per "Char". Això no és cert. L'expressió /Char/ indica que la línia conté la paraula "Char". Per exemple, podem buscar totes les línies del fitxer pokemon.csv que contenen el patró "ois":
awk '/ois/ {print}' pokemon.csv
En la sortida, veureu que tant les paraules "poison" del tipus de pokémon com els diferents noms de pokémon que contenen la paraula "ois" són mostrats.
1,Bulbasaur,Grass,Poison,318,45,49,49,65,65,45,1,False
9,Blastoise,Water,-,530,79,83,100,85,105,78,1,False
...
71,Victreebel,Grass,Poison,490,80,105,65,100,70,70,1,False
...
691,Dragalge,Poison,Dragon,494,65,75,90,97,123,44,6,False
Conteu quantes línies compleixen aquest patró, combinant AWK amb la comanda wc:
awk '/ois/ {print}' pokemon.csv | wc -l
En aquest cas, hi ha 64 entrades que satisfan aquest patró.
cut
La comanda cut ens permet extreure columnes d'un fitxer. Per exemple, per mostrar només la primera columna del fitxer pokemon.csv:
cut -d, -f1 pokemon.csv
on -d, indica que el separador de camps és la coma i -f1 indica que volem la primera columna. Podem fer servir AWK per fer el mateix. Per exemple, per mostrar només la primera columna del fitxer pokemon.csv:
awk -F, '{print $1}' pokemon.csv
on -F, indica que el separador de camps és la coma i {print $1} indica que volem la primera columna. Això és equivalent a la comanda cut.
Cada item separat pel separador de camps es denomina camp. Per exemple, en el fitxer pokemon.csv, cada columna separada per una coma és un camp. Per defecte, el separador de camps és l'espai en blanc. Per tant, si no especifiquem el separador de camps, AWK utilitzarà l'espai en blanc com a separador de camps.
Si intentem imprimir la tercera columna sense especificar el separador de camps, la sortida no serà correcta:
awk '{print $3}' pokemon.csv
Això és degut a que el separador de camps per defecte és l'espai en blanc i no la coma. Ara bé, si modifiquem el separador de camps a l'espai en blanc, enlloc de la coma, podem obtenir la sortida correcta:
sed 's/,/ /g' pokemon.csv | awk '{print $3}'
En aquest cas, estem substituint totes les comes per espais en blanc i després utilitzant AWK per imprimir la tercera columna.
Verificacions lògiques
Es pot utilitzar com a patró una expressió composta amb operadors i retornar true o false.
| Operador | Significat |
|---|---|
| < | Menor |
| > | Major |
| <= | Menor o igual |
| >= | Major o igual |
| == | Igualtat |
| != | Desigualtat |
| ~ | Correspondència amb expressió regular |
| !~ | No correspondència amb expressió regular |
| ! | Negació |
| && | AND |
| || | OR |
| () | Agrupació |
Per utilizar aquestes expressions, podem fer servir la següent sintaxi:
awk 'patró { acció }' fitxer
on el patró és una expressió composta amb operadors lògics i l'acció és el que es vol fer amb les línies que compleixen el patró. Per exemple:
-
Mostrar tots els pokemons que tenen més de 100 punts d'atac (valor de la columna 7):
awk -F, '$7 > 100 {print}' pokemon.csv -
Mostrar tots els pokemons que tenen més de 100 punts d'atac (valor de la columna 7) i són de la primera generació (valor de la columna 12):
awk -F, '$7 > 100 && $12 == 1 {print}' pokemon.csv -
Mostrar tots els pokemons que tenen més de 100 punts d'atac (valor de la columna 7) o són de la primera generació (valor de la columna 12):
awk -F, '$7 > 100 || $12 == 1 {print}' pokemon.csv -
Mostrar tots els pokemons que són Mega pokemons (contenen la paraula "Mega" a la columna 2):
awk -F, '$2 ~ /Mega/ {print}' pokemon.csv -
Mostra tots els pokemons que no són Mega pokemons (no contenen la paraula "Mega" a la columna 2):
awk -F, '$2 !~ /Mega/ {print}' pokemon.csv
Exercicis Bàsics
Aquests exercicis estan resolts en bash i en AWK. Podeu provar-los en el vostre sistema per entendre com funcionen. Intenta resoldre primer els exercicis en bash i després en AWK. Un cop pensada la solució, podeu comparar-la amb la solució proporcionada.
-
Implementeu una comanda que permeti filtrar tots els pokemon de tipus foc (Foc) i imprimir únicament per stdout el nom i els seus tipus (columnes 2, 3 i 4).
- En bash podem fer servir la comanda grep per filtrar les línies que contenen la paraula "Fire" i la comanda cut per extreure les columnes 2, 3 i 4:
grep Fire pokemon.csv | cut -d, -f2,3,4- En AWK:
awk -F, '/Fire/ {print $2,$3,$4}' pokemon.csv -
Implementeu una comanda que permeti imprimir totes les línies que continguin una 'b' o una 'B' seguida de "ut". Mostra només el nom del pokémon (columna 2).
- En AWk podem fer servir l'expressió regular [bB]ut:
awk -F, '/[bB]ut/ {print $2}' pokemon.csv- En bash podem fer servir la comanda grep amb l'argument -i per ignorar la diferència entre majúscules i minúscules:
grep -i "but" pokemon.csv | cut -d, -f2 -
Implementeu una comanda que permeti imprimir totes les línies que comencin per un "K" majúscula. Mostra només el nom del pokémon (columna 2).
- En bash podem fer servir la comanda grep amb el meta caràcter ^ per indicar que la línia comença per "K" majúscula:
grep "^K" pokemon.csv | cut -d, -f2- En AWK:
awk -F, '$2 ~ /^K/ {print $2}' pokemon.csv!Compte: Per defecte, les expressions regulars actuen sobre tota la línia $0. Si voleu aplicar l'expressió regular a una columna determinada, necessiteu l'operador (~). Si intenteu aplicar:
awk -F,'/^K/ {print $2}' pokemon.csvno funcionarà ja que l'inici ^ de $0 serà un enter. -
Imprimiu tots els pokemons que siguin del tipus foc o lluita. Imprimiu el nom, tipus 1 i tipus 2. Podeu fer servir l'operador | per crear l'expressió regular.
- En AWK podem fer servir l'operador | per combinar dos patrons:
awk -F, '/Fire|Fighting/ {print $2,$3,$4}' pokemon.csv- En bash, podeu fer servir l'argument -E per utilitzar expressions regulars exteses amb la comanda grep:
grep -E "Fire|Fighting" pokemon.csv | cut -d, -f2,3,4 -
Imprimiu tots els pokemons que siguin del tipus foc i lluita. Imprimiu el nom, tipus 1 i tipus 2. Podeu fer servir l'operador && per crear l'expressió regular.
- En AWK podem fer servir l'operador && per combinar dos patrons:
awk -F, '/Fire/ && /Fighting/ {print $2,$3,$4}' pokemon.csv- En bash, podeu fer servir l'argument -E per utilitzar expressions regulars exteses amb la comanda grep:
grep -E "Fire.*Fighting|Fighting.*Fire" pokemon.csv | cut -d, -f2,3,4En aquest cas no podem fer servir l'operador && ja que grep no permet aquesta funcionalitat. Per tant, hem de fer servir l'operador | per combinar els dos patrons. A més, hem de fer servir l'expressió regular **Fire.Fighting|Fighting.Fire per indicar que volem les línies que contenen "Fire" seguit de "Fighting" o "Fighting" seguit de "Fire".
-
Imprimiu el nom de tots els pokemons de la primera generació que siguin llegendaris. Per fer-ho utilitzeu les columnes 12 i 13. La columna 12 indica la generació amb valors númerics (1,2,3,...) i la columna 13 indica si un pokémon és llegendari o no (0: No, 1: Sí).
- En AWK podem fer servir l'operador && per combinar dos patrons:
awk -F, '$12 == 1 && $13 == "True" {print $2}' pokemon.csv- En bash, podem fer servir la comanda grep per filtrar les línies que contenen la primera generació i són llegendaris i la comanda cut per extreure la columna 2:
grep "1,True" pokemon.csv | cut -d, -f2Aquesta solució no és la més òptima, ja que es podria donar el cas que altres columnes continguessin la paraula "1,True". Per solucionar-ho podem fer un script més complex que comprovi que la columna 12 conté el valor 1 i la columna 13 conté la paraula "True".
#!/bin/bash while IFS=, read -r col1 col2 col3 col4 col5 col6 col7 col8 col9 col10 col11 col12 col13; do if [[ "$col12" == "1" ]] && [[ "$col13" == "True" ]]; then echo "$col2" fi done < pokemon.csv
Awk - Intermedi
Variables en AWK
El llenguatge de programació AWK ens permet definir variables i utilitzar-les en les nostres accions. Les variables en AWK són dinàmiques i no necessiten ser declarades abans d'utilitzar-les. Això significa que podem utilitzar una variable sense haver-la declarat prèviament.
Per exemple, si volem comptar el nombre de línies que hi ha al fitxer pokemon.csv, podem fer servir una variable per a emmagatzemar el nombre de línies. A continuació, mostrem un exemple de com comptar el nombre de línies del fitxer pokemon.csv:
awk 'BEGIN { n=0 } { ++n } END{ print n }' pokemon.csv
On n és la variable que utilitzem per emmagatzemar el nombre de línies. Per començar, inicialitzem la variable n a 0 amb la clàusula {BEGIN}. Aquesta clausula és opcional, ja que les variables en AWK són dinàmiques i no necessiten ser declarades prèviament. Després, incrementem la variable n per a cada línia amb la clàusula {++n}. Finalment, utilitzem la clàusula {END} per imprimir el valor de la variable n després de processar totes les línies.
Operacions Aritmètiques
| Operador | Aritat | Signigicat |
|---|---|---|
| + | Binari | Suma |
| - | Binari | Resta |
| * | Binari | Multiplicació |
| / | Binari | Divisió |
| % | Binari | Mòdul |
| ^ | Binari | Exponent |
| ++ | Unari | Increment 1 unitat |
| -- | Unari | Decrement 1 unitat |
| += | Binari | x = x+y |
| -= | Binari | x = x-y |
| *= | Binari | x=x*y |
| /= | Binari | x=x/y |
| %= | Binari | x=x%y |
| ^= | Binari | x=x^y |
Implementeu un script que comprovi que el Total (columna 5) és la suma de tots els atributs (columnes 6,7,8,9,10 i 11). La sortida ha de ser semblant a:
Charmander->Total=309==309
Charmeleon->Total=405==405
Charizard->Total=534==534
-
En AWK:
awk -F, '{ print $2"->Total="$5"=="($6+$7+$8+$9+$10+$11)}' pokemon.csv -
En bash:
#!/bin/bash while IFS=, read -r col1 col2 col3 col4 col5 col6 col7 col8 col9 col10 col11 col12 col13; do if [[ "$col5" == "$((col6+col7+col8+col9+col10+col11))" ]]; then echo "$col2->Total=$col5==$((col6+col7+col8+col9+col10+col11))" fi done < pokemon.csv
Variables Internes
AWK té variables internes que són molt útils per a la manipulació de dades. Aquestes variables són:
| Variable | Contingut |
|---|---|
| $0 | Conté tot el registre actual |
| NF | Conté el valor del camp (columna) actual. |
| $1,$2..., | $1 conté el valor del primer camp i així fins l'últim camp. noteu que $NF serà substituït al final pel valor de l'últim camp. |
| NR | Índex del registre actual. Per tant, quan es processa la primera línia aquesta variable té el valor 1 i quan acaba conté el nombre de línies processades. |
| FNR | Índex del fitxer actual que estem processant. |
| FILENAME | Nom del fitxer que estem processant. |
Per exemple:
-
Utilitzeu la variable NR per simplificar la comanda per comptar el nombre de línies del fitxer pokemon.csv:
awk 'END{ print NR }' pokemon.csv -
Traduïu la capçalera del fitxer pokemon.csv al catala. La capçalera és la següent: # Name Type 1 Type 2 Total HP Attack Defense Sp. Atk Sp. Def Speed Generation Legendary. La traducció és la següent: # Nom Tipus 1 Tipus 2 Total HP Atac Defensa Atac Especial Defensa Especial Velocitat Generació Llegendari. I després imprimiu la resta de línies del fitxer.
awk 'NR==1 { $1="#"; $2="Nom"; $3="Tipus 1"; $4="Tipus 2"; $5="Total"; $6="HP"; $7="Atac"; $8="Defensa"; $9="Atac Especial"; $10="Defensa Especial"; $11="Velocitat"; $12="Generació"; $13="Llegendari"; print $0 } NR>1 {print}' pokemon.csv -
Implementeu una comanda que permeti detectar entrades incorrectes a la pokedex. Un entrada incorrecta és aquella que no té 13 valors per línia. En cas de detectar una entrada incorrecta, la eliminarem de la sortida i comptarem el nombre de línies eliminades per mostrar-ho al final.
awk 'NF != 13 { n++ } NF == 13 { print } END{ print "There are ", n, "incorrect entries." }' pokemon.csv
Condicionals
Les sentències condicionals s'utilitzen en qualsevol llenguatge de programació per executar qualsevol sentència basada en una condició particular. Es basa en avaluar el valor true o false en les declaracions if-else i if-elseif. AWK admet tot tipus de sentències condicionals com altres llenguatges de programació.
Implementeu una comanda que us indiqui quins pokemons de tipus foc són ordinaris o llegendaris. Busquem una sortida semblant a:
Charmander is a common pokemon.
Charizard is a legendary pokemon.
...
La condició per ser un pokémon llegendari és que la columna 13 sigui True.
awk -F, '/Fire/ { if ($13 == "True") { print $2, "is a legendary pokemon." } else { print $2, "is a common pokemon." } }' pokemon.csv
Es pot simplificar la comanda anterior amb l'ús de l'operador ternari ?::
awk -F, '/Fire/ { print $2, "is a", ($13 == "True" ? "legendary" : "common"), "pokemon." }' pokemon.csv
Formatant la sortida
AWK ens permet també utilitzar una funció semblant al printf de C. Permet imprimir la cadena
amb diferents formats: printf("cadena",expr1,,expr2,...)
| %20s | Es mostraran 20 caràcters de la cadena alineats a la dreta per defecte. |
| %-20s | Es mostraran 20 caràcters de la cadena alineats a l'esquerra per defecte. |
| %3d | Es mostrarà un enter de 3 posicions alineat a la dreta |
| %03d | Es mostrarà un enter de 3 posicions completat amb un 0 a l'esquerra i tot alineat a la dreta |
| %-3d | Es mostrarà un enter de 3 posicions alineat a la esquerra. |
| &+3d | Idem amb signe i alineat a la dreta |
| %10.2f | Es mostrarà un nombre amb coma flotant amb 10 posicions, 2 de les quals seràn decimals. |
Per exemple:
awk -F, \
' BEGIN{
max=0
min=100
}
{
if ($3 =="Fire") {
n++
attack+=$7
if ($7 > max){
pmax=$2
max=$7
}
if ($7 < min){
pmin=$2
min=$7
}
}
}
END{ printf("Avg(Attack):%4.2f \nWeakest:%s \nStrongest:%s\n",attack/n,pmin,pmax)
}' pokemon.csv
Exercicis Intermedis
-
Implementeu un script que compti tots els pokemons que tenim a la pokedex i que tingui la sortida següent:
Counting pokemons... There are 800 pokemons.Recordeu que la primera línia és la capçalera i no la volem comptar.
-
En bash:
!/bin/bash echo "Counting pokemons..." n=`wc -l pokemon.csv` n=`expr $n - 1` echo "There are $n pokemons." -
En AWK:
awk 'BEGIN { print "Counting pokemons..." } { ++n } END{ print "There are ", n-1, "pokemons." }' pokemon.csv
-
-
Implementeu un comptador per saber tots els pokemons de tipus foc de la primera generació descartant els Mega pokemons i que tingui la sortida següent:
Counting pokemons... There are 12 fire type pokemons in the first generation without Mega evolutions.-
Per fer-ho en bash, podeu combinar les comandes grep, cut, wc i expr. Nota, l'argyment -v de grep exclou les línies que contenen el patró i la generació s'indica a la columna 12 amb el valor 1:
!/bin/bash echo "Counting pokemons..." n=`grep Fire pokemon.csv | grep -v "Mega" | cut -d, -f12 | grep 1 | wc -l` n=`expr $n - 1` echo "There are $n pokemons in the first generation without Mega evolutions."- Per fer-ho en AWK, teniu el negador ! per negar el patró:
awk -F, 'BEGIN { print "Counting pokemons..." } /Fire/ && !/Mega/ && $12 == 1 { ++n } END{ print "There are ", n, "fire type pokemons in the first generation without Mega evolutions." }' pokemon.csvEn aquest exemple, hem utilitzat l'operador lògic && per combinar dos patrons. Això significa que la línia ha de contenir el patró Fire i no ha de contenir el patró Mega. Això ens permet filtrar els Mega pokemons del nostre comptador. A més, hem utilitzat l'operador ! per negar el patró Mega. Això significa que la línia no ha de contenir el patró Mega. Finalment, hem utilitzat la clàusula {END} per imprimir el resultat final.
-
-
Indiqueu a quina línia es troba cada pokémon del tipus foc. Volem imprimir la línia i el nom del pokémon. La sortida ha de ser semblant a:
Line: 6 Charmander Line: 7 Charmeleon Line: 8 Charizard Line: 9 CharizardMega Charizard X Line: 10 CharizardMega Charizard Y ... Line: 737 Litleo Line: 738 Pyroar Line: 801 Volcanionon el format de cada línia és Line: n\tNom del pokémon.
-
En AWK podem fer servir la variable NR per obtenir el número de línia actual. A més a més, podeu formatar la sortida amb
print cadena,variable,cadena,variable,...:awk -F, '/Fire/ {print "Line: ", NR, "\t" $2}' pokemon.csv -
En bash:
#!/bin/bash while IFS=, read -r col1 col2 col3 rest; do ((line_number++)) # Check if the line contains the word "Fire" if [[ "$col2" == *"Fire"* || "$col3" == *"Fire"* ]]; then echo "Line: $line_number $col2" fi done < pokemon.csv
-
-
Implementeu un script que permeti comptar el nombre de pokemons de tipus foc i drac. La sortida ha de ser semblant a:
Fire:64 Dragon:50 Others:689-
En AWK:
awk -F, 'BEGIN{ fire=0; dragon=0; others=0 } /Fire/ { fire++ } /Dragon/ { dragon++ } !/Fire|Dragon/ { others++ } END{ print "Fire:" fire "\nDragon:" dragon "\nOthers:" others }' pokemon.csv -
En bash:
#!/bin/bash fire=0 dragon=0 others=0 while IFS=, read -r col1 col2 col3 col4 col5 col6 col7 col8 col9 col10 col11 col12 col13; do if [[ "$col3" == *"Fire"* || "$col4" == *"Fire"* ]]; then ((fire++)) fi if [[ "$col3" == *"Dragon"* || "$col4" == *"Dragon"* ]]; then ((dragon++)) fi if [[ "$col3" != *"Fire"* && "$col4" != *"Fire"* && "$col3" != *"Dragon"* && "$col4" != *"Dragon"* ]]; then ((others++)) fi done < pokemon.csv echo "Fire:$fire" echo "Dragon:$dragon" echo "Others:$others"
-
-
Imprimiu la pokedex amb una nova columna que indiqui la mitjana aritmètica dels atributs de cada pokémon. La sortida ha de ser semblant a:
#,Name,Type 1,Type 2,Total,HP,Attack,Defense,Sp. Atk,Sp. Def,Speed,Generation,Legendary,Avg 1,Bulbasaur,Grass,Poison,318,45,49,49,65,65,45,1,False,53 2,Ivysaur,Grass,Poison,405,60,62,63,80,80,60,1,False,67.5 3,Venusaur,Grass,Poison,525,80,82,83,100,100,80,1,False,87.5-
En AWK:
awk -F, '{ if (NR==1) print $0",Avg"; else print $0","($6+$7+$8+$9+$10+$11)/6 }' pokemon.csv -
En bash:
#!/bin/bash while IFS=, read -r col1 col2 col3 col4 col5 col6 col7 col8 col9 col10 col11 col12 col13; do if [[ "$col1" == "#" ]]; then echo "$col1,$col2,$col3,$col4,$col5,$col6,$col7,$col8,$col9,$col10,$col11,$col12,$col13,Avg" else avg=$((($col6+$col7+$col8+$col9+$col10+$col11)/6)) echo "$col1,$col2,$col3,$col4,$col5,$col6,$col7,$col8,$col9,$col10,$col11,$col12,$col13,$avg" fi done < pokemon.csvNota: Bash de forma nativa no permet operacions aritmètiques amb nombres decimals. Per fer-ho, cal utilitzar una eina com
bc. En aquest cas, podeu adaptar el codi per utilitzarbcquan calculeu la mitjana i fer servirprintfper formatar la sortida amb el nombre de decimals que vulgueu.
-
-
Cerca el pokémon més fort i més feble tenint en compte el valor de la columna 7 dels pokemons de tipus foc de la primera generació.
-
En AWK, assumiu que el valors de la columna 7 van de 0 a 100:
awk -F, 'BEGIN{ max=0; min=100 } /Fire/ && $12 == 1 { if ($7 > max) { max=$7; pmax=$2 } if ($7 < min) { min=$7; pmin=$2 } } END{ print "Weakest: "pmin "\nStrongest: "pmax }' pokemon.csv -
En bash:
#!/bin/bash max=0 min=100 while IFS=, read -r col1 col2 col3 col4 col5 col6 col7 col8 col9 col10 col11 col12 col13; do if [[ "$col3" == *"Fire"* ]] && [[ "$col12" == "1" ]]; then if [[ "$col7" -gt "$max" ]]; then max=$col7 pmax=$col2 fi if [[ "$col7" -lt "$min" ]]; then min=$col7 pmin=$col2 fi fi done < pokemon.csv echo "Weakest: $pmin" echo "Strongest: $pmax"
-
Awk - Avançat
Variables definides quan executem AWK
| Variable | Valor per defecte | Significat |
|---|---|---|
| RS | /n (Salt de línia) | Valor que fem servir per separar els registres (entrada) |
| FS | Espais o tabulacions | Valor que fem servir per separar els camps en l'entrada. |
| OFS | espai | Valor que fem servir per separar el camps en la sortida. |
| ORS | /n (Salt de línia) | Valor que fem servir per separar els registres (sortida). |
| ARGV | - | Taula inicialitzada amb els arguments de la línia de comandes (opcions i nom del script awk s'exclouen). |
| ARGC | - | Nombre d'arguments. |
| ENVIRON | Variables entorn | Taula amb les variables entorn exportades per la shell. |
Per exemple:
-
Transformeu el fitxer pokemon.csv en un fitxer amb els camps separats per tabulacions:
awk -F, 'BEGIN{OFS="\t"} {print $0}' pokemon_tab.csv -
Per fer servir el fitxer pokemon_tab.csv podem utilitzar els mateixos scripts que hem fet servir amb el fitxer pokemon.csv. Però indicant que el separador de camps és un tabulador. Per exemple, per comptar el nombre de pokemons lluitadors:
awk -F"\t" '/Fighting/ {print $2}' pokemon_tab.csv -
Si volem fer servir una variable entorn per indicar el tipus de pokemons que volem comptar, podem fer-ho així:
awk -F"\t" -v type=$TYPE '{ if ($3 == type) { print $2 } }' pokemon_tab.csvon $TYPE és una variable entorn que conté el tipus de pokemons que volem comptar.
Bucles
El llenguatge AWK també ens permet fer bucles accepta les següents estructures:
for (expr1;expr2;expr3) { acció }: Aquest bucle executa la primera expressió, després avalua la segona expressió i si és certa executa l'acció. Després executa la tercera expressió i torna a avaluar la segona expressió. Això es repeteix fins que la segona expressió sigui falsa.
Per exemple, transformeu el fitxer pokemon.csv en un fitxer amb els camps separats per ; utilitzant un bucle for:
awk -F, \
'BEGIN{OFS=";";}
{
for (i=1;i<=NF;i++)
printf("%s%s",$i,(i==NF)?"\n":OFS)
}' pokemon.csv
while (condició) { acció }: Aquest bucle executa l'acció mentre la condició sigui certa.
Per exemple, substituïu els camps del tipus de pokemon per un camps tipus compost per els dos tipus de pokemon separats per un / dels primers 10 pokemons:
awk -F, \
'BEGIN{OFS=",";}
{
while (NR>1 && NR <= 11) {
print $1, $2, $3 "/" $4, $5, $6, $7, $8, $9, $10, $11, $12, $13
getline
}
}' pokemon.csv
La comanda getline ens permet llegir la següent línia de l'entrada. Això ens permet llegir la següent línia dins del bucle while. Si no fem servir la comanda getline, el bucle while es quedaria en un bucle infinit ja que la condició NR <= 11 sempre seria certa.
do { acció } while (condició): Aquest bucle executa l'acció una vegada i després avalua la condició. Si la condició és certa, torna a executar l'acció.
Per exemple, utilitzeu el bucle do per comptar el nombre de pokemons de tipus foc:
awk -F, \
'BEGIN{print "Counting pokemons..."; n=0}
{
do {
if ($3 == "Fire" || $4 == "Fire")
n++
} while (getline)
}
END{print "There are ", n, "fire type pokemons."}' pokemon.csv
Instruccions de control:
break: Finalitza el bucle actual.continue: Salta a la següent iteració del bucle.next: Salta a la següent línia de l'entrada.
Per exemple:
-
Cerqueu la primera entrada que compleixi les següents condicions: el tipus de pokemon és "Fire" i la seva velocitat és més gran que 100:
awk -F, 'BEGIN {found = 0} { if (found == 0) { for (i=1; i<=NF; i++) { if ($i == "Fire" && $7 > 100) { print "El primer Pokémon de tipus Fire amb velocitat superior a 100 és: " $2; found = 1; break } } } }' pokemon.csvObservació:
breakfinalitza el bucle actual que recorre els camps de la línia. Per tant, ens permet deixar de buscar en una línia quan ja hem trobat el que volem. -
Cerqueu totes les entrades que compleixen les següents condicions: el tipus de pokemon és "Fire" i la seva velocitat és més gran que 100:
awk -F, '{ for (i=1; i<=NF; i++) { if ($i == "Fire" && $7 > 100) { print $2 } } }' pokemon.csvo bé
awk -F, '{ for (i=1; i<=NF; i++) { if ($i == "Fire" && $7 > 100) { print $2; break } } }' pokemon.csvObservació:
breakens permet que quan trobem un pokemon que compleix les condicions, no cal seguir buscant en la mateixa línia i podem passar a la següent. En aquest cas,nextseria equivalent abreak. -
Cerqueu tots els pokemons que són voladors i de foc assumint que les columnes poden estar en qualsevol ordre i que cada entrada pot estar ordenada de forma diferent:
awk -F, '{ for (i=1; i<=NF; i++) { if ($i == "Fire") { for (j=1; j<=NF; j++) { if ($j == "Flying") { print $2; next } } } } }' pokemon.csvObservació:
nextens permet que quan trobem un pokemon que compleix les condicions, no cal seguir buscant en la mateixa línia i podem passar a la següent.Observació:
breakens donaria el mateix resultat en aquest cas. Perònextés més eficient perquè no cal seguir recorrent els camps de la línia. La comandabreakseguiria recorrent els camps al bucle de la variable i.
Arrays
AWK també ens permet fer servir arrays. Per exemple, podem fer servir un array per comptar el nombre de pokemons de cada tipus:
awk -F, '
{
if (NR > 1) {
type1 = $3
type2 = $4
types[type1]++
if (type2 != "") {
types[type2]++
}
}
}
END {
for (type in types) {
print type, types[type]
}
}' pokemon.csv
Els arrays en AWK són associatius, és a dir, no cal indicar la posició de l'element en l'array. Per exemple, si volem comptar el nombre de pokemons de cada tipus per generació:
gawk -F, '
{
if (NR > 1) {
type1 = $3
type2 = $4
gen = $12
types[type1][gen]++
if (type2 != "") {
types[type2][gen]++
}
}
}
END {
for (type in types) {
printf "%s\n", type
for (gen in types[type]) {
printf " Gen %d: %d\n", gen, types[type][gen]
}
}
}' pokemon.csv
Nota: En aquest exemple, hem fet servir un array bidimensional. El llenguatge
awkno permet declarar arrays multidimensionals, per poder fer-lo servir necessitem la extensió gawk. Per instal·lar-la, podeu fer servir la comandaapt install gawkodnf install gawk.
Per fer-ho en AWK, podem utiltizar una clau combinada amb el tipus i la generació i la funció split per separar les dues claus:
awk -F, '
{
if (NR > 1) {
type1 = $3
type2 = $4
gen = $12
types[type1 " " gen]++
if (type2 != "") {
types[type2 " " gen]++
}
}
}
END {
for (typegen in types) {
split(typegen, temp, " ")
type = temp[1]
gen = temp[2]
printf "%s %d: %d\n", type, gen, types[typegen]
}
}' pokemon.csv | sort -k2 -n
Exercicis Avançats AWK
-
Implementeu un script que mostri la pokedex en ordre invers. Però mantenint la primera línia com a capçalera.
awk -F, ' { if (NR == 1) { print $0 } else { lines[NR] = $0 } } END { for (i = NR; i > 1; i--) { print lines[i] } }' pokemon.csv -
Implementeu un script que simuli la comanda
sort -t, -k5 -n pokemon.csv. Aquesta comanda ordena el fitxer pokemon.csv pel camp Total de forma numèrica. Podeu fer servir la funcióasortper ordenar els pokemons. Aquesta funció ordena un array i retorna el nombre d'elements de l'array ordenat. Per exemple:asort(array, sorted, "@val_num_asc")ordena l'array array de forma numèrica ascendent i guarda el resultat a l'array sorted.
A més, podeu fer servir la funció
splitque ens permet dividir una cadena de text en un array. Per exemple:split("a,b,c,d", array, ",")divideix la cadena de text "a,b,c,d" en l'array array amb els valors "a", "b", "c" i "d".
awk -F, ' { if (NR == 1) { print $0 } else { lines[NR] = $0 totals[NR] = $5 " " NR } } END { n = asort(totals, sorted, "@val_num_asc") for (i = 1; i <= n; i++) { split(sorted[i], temp, " ") line = temp[2] print lines[line] } }' pokemon.csv -
Implementeu un script que mostri una taula resum amb els pokemons de cada tipus a cada generació. Un exemple de la sortida esperada:
Tipus Gen 1 Gen 2 Gen 3 Gen 4 Gen 5 Gen 6 Normal 24 15 18 18 19 8 Dragon 4 2 15 8 12 9 Ground 14 11 16 12 12 2 Electric 9 9 5 12 12 3 Poison 36 4 5 8 7 2 Steel 2 6 12 12 12 5 Bug 14 12 14 11 18 3 Grass 15 10 18 17 20 15 Fire 14 11 9 6 16 8 Dark 1 8 13 7 16 6 Ice 5 5 7 8 9 4 Fighting 9 4 9 10 17 4 Water 35 18 31 15 18 9 Ghost 4 1 8 9 9 15 Flying 23 19 14 16 21 8 Rock 12 8 12 7 10 9 Fairy 5 8 8 2 3 14 Psychic 18 10 28 10 16 8 Notes:
- Els tipus de pokemons es troben a la columna 3 i 4 i la generació a la columna 12.
- Utilitzeu printf per formatar la sortida.
- En AWK:
awk -F, ' BEGIN { print "| Tipus | Gen 1 | Gen 2 | Gen 3 | Gen 4 | Gen 5 | Gen 6 |" print "|------------|-------|-------|-------|-------|-------|-------|" } { if (NR > 1) { type1 = $3 type2 = $4 gen = $12 types[type1][gen]++ if (type2 != "") { types[type2][gen]++ } } } END { for (type in types) { printf "| %-10s |", type for (gen = 1; gen <= 6; gen++) { printf " %-5s |", types[type][gen] ? types[type][gen] : 0 } print "" } }' pokemon.csv -
Implementeu un parser que transformi el fitxer
pokemon.csven un fitxerpokemon.json. Aquest fitxer ha de ser formatat de forma correcta. Podeu assumir que coneixeu els headers del fitxer i la tipologia de les seves dades. Per exemple, la primera línia del fitxer pokemon.csv ha de ser transformada en:{ "Name": "Bulbasaur", "Type 1": "Grass", "Type 2": "Poison", "Total": 318, "HP": 45, "Attack": 49, "Defense": 49, "Sp. Atk": 65, "Sp. Def": 65, "Speed": 45, "Generation": 1, "Legendary": false }- Una solució simple en AWK:
awk -F, ' BEGIN { print "[" } { if (NR > 1) { printf " {\n" printf " \"Name\": \"%s\",\n", $2 printf " \"Type 1\": \"%s\",\n", $3 printf " \"Type 2\": \"%s\",\n", $4 printf " \"Total\": %d,\n", $5 printf " \"HP\": %d,\n", $6 printf " \"Attack\": %d,\n", $7 printf " \"Defense\": %d,\n", $8 printf " \"Sp. Atk\": %d,\n", $9 printf " \"Sp. Def\": %d,\n", $10 printf " \"Speed\": %d,\n", $11 printf " \"Generation\": %d,\n", $12 printf " \"Legendary\": %s\n", $13 printf " }%s\n", (NR == 800) ? "" : "," } } END { print "]" }' pokemon.csv > pokemon.json- Una solució més complexa en AWK:
awk -F, ' BEGIN { print "[" } { if(NR == 1) { for (i = 2; i <= NF; i++) { headers[i] = $i } } else { if(NR != 2) { print " }," } printf " {\n" for (i = 2; i <= NF; i++) { if ($i ~ /^[0-9]+$/) { printf " \"%s\": %d,\n", headers[i], $i } else { printf " \"%s\": \"%s\",\n", headers[i], $i } } } } END { print " }\n]" }' pokemon.csv > pokemon.json -
Implementeu un script que permeti simular un combat entre dos pokémons. Els pokémons es passen com a variables d'entorn i han d'utilitzar el nom del pokémon a la pokedex. La lògica del combat és comparar els valors de velocitat per saber qui ataca primer. El pokémon que ataca primer és el que té més velocitat. Si els dos pokémons tenen la mateixa velocitat, el primer pokémon que s'ha passat com a variable d'entorn ataca primer. El combat es fa de forma alternada fins que un dels dos pokémons es queda sense punts de vida. El dany es mesura com (Atac - Defensa) multiplicat per un valor aleatori entre 0 i 1. Aquest es resta a la vida del pokémon oponent. La sortida ha de ser semblant a:
Charizard attacks first! Charizard attacks Charmander with 50 damage! Charmander has 20 HP left. Charmander attacks Charizard with 30 damage! Charizard has 70 HP left. Charizard attacks Charmander with 40 damage! Charmander has -10 HP left. Charmander fainted!- Una possible solució combinar AWK i bash:
#!/bin/bash # Get the pokemons from the command line arguments pokemon1=$1 pokemon2=$2 # Function to get stats of a pokemon get_stats() { awk -F, -v pokemon="$1" '$2 == pokemon { print $6, $7, $8, $9, $10, $11 }' pokemon.csv } # Get the stats of the pokemons stats1=$(get_stats $pokemon1) stats2=$(get_stats $pokemon2) # Extract the stats read hp1 attack1 defense1 spatk1 spdef1 speed1 <<< $stats1 read hp2 attack2 defense2 spatk2 spdef2 speed2 <<< $stats2 # Check who attacks first if [ $speed1 -gt $speed2 ]; then attacker=$pokemon1 hp=$hp2 defender=$pokemon2 attack=$attack1 defense=$defense2 else attacker=$pokemon2 defender=$pokemon1 hp=$hp1 attack=$attack2 defense=$defense1 fi echo "$attacker attacks first!" # Start the battle while true; do damage=$((($attack - $defense) * $RANDOM / 32767)) damage=${damage#-} hp=$(($hp - $damage)) echo "$attacker attacks $defender with $damage damage!" if [ $hp -le 0 ]; then echo "$defender has 0 HP left." echo "$defender fainted!" break else echo "$defender has $hp HP left." fi # Swap the attacker and defender tmp=$attacker attacker=$defender defender=$tmp tmp=$hp hp=$hp2 hp2=$tmp tmp=$attack attack=$attack2 attack2=$tmp tmp=$defense defense=$defense2 defense2=$tmp done
Repositori d'exercicis
Aquesta secció conté els exercicis realitzats pels estudiants de l'assignatura d'Administració i Manteniment de Sistemes i Aplicacions (AMSA).
Exercicis
Bàsics
Intermedis
Avançats
Arrancada del sistema
Quan arranquem un ordinador, tenen lloc una sèrie de processos que permeten que el sistema operatiu es carregui i es posi en marxa. Aquests processos són els que es coneixen com a arrancada del sistema. En un sistema linux, la seqüència d'arrancada es pot dividir en les següents fases:
-
Càrrega del BIOS o UEFI. Quan encenem l'ordinador, el primer programa que s'executa està emmagatzemat en una memòria no volàtil (NVRAM). Aquest programa pot ser el BIOS (Basic Input/Output System) en sistemes més antics o l'UEFI (Unified Extensible Firmware Interface) en sistemes més moderns. Aquest firmware és el responsable de gestionar les funcions bàsiques del sistema abans de carregar el sistema operatiu.
-
Test de l'ordinador. El BIOS o l'UEFI realitza un test de l'ordinador per assegurar-se que tots els components funcionen correctament. Aquest test s'anomena POST (Power-On Self Test). Si el test falla, l'ordinador emet una sèrie de senyals acústics o visuals per indicar quin component ha fallat.
-
Selecció del dispositiu d'arrancada. El BIOS o l'UEFI permet triar quin dispositiu volem utilitzar per a carregar el sistema operatiu. Aquest dispositiu pot ser el disc dur, un dispositiu USB, un CD-ROM, etc..
-
Identificació de la partició d'arrancada. El BIOS o UEFI localitza la partició d'arrencada del dispositiu seleccionat. En sistemes amb BIOS, es fa servir el Master Boot Record (MBR), mentre que en sistemes amb UEFI es fa servir la taula de particions GUID (GPT) per identificar la partició correcta (normalment, anomenada EFI). Aquesta partició conté el gestor d'arrencada i altres fitxers necessaris per continuar el procés d'arrencada.
-
Càrrega del gestor d'arrancada. El BIOS o UEFI carrega el gestor d'arrencada. El gestor d'arrancada és un petit programa que permet triar quin sistema operatiu volem carregar. Els gestors d'arrencada més comuns en sistemes Linux són GRUB (Grand Unified Bootloader) o LILO (Linux Loader). Aquests gestors d'arrancada mostren una llista amb els sistemes operatius disponibles i permeten triar-ne un.
-
Càrrega del kernel. En aquesta fase, el gestor d'arrancada descomprimeix el codi del nucli i el carrega a la memòria.
-
Càrrega del sistema de fitxers inicial. El nucli carrega un sistema de fitxers inicial (initramfs o initrd) que conté els mòduls i els programes necessaris per muntar el sistema de fitxers real del sistema operatiu.
-
Sistema d'inicialització. És el primer procés que s'executa en un sistema operatiu en l'espai usuari. En el cas de GNU/Linux, el sistema d'inicialització més comú és el systemd. Una altre gestor d'arrancada, més vell però molt utilitzat és el SysVInit (Init).
-
Execució dels targets o runlevels. El sistema d'inicialització carrega els diferents targets o runlevels, que defineixen l'estat del sistema en un moment determinat. Aquests runlevels poden ser diferents nivells d'arrencada, com arrencada en mode gràfic o mode de recuperació. Cada runlevel pot tenir diferents serveis i daemons activats o desactivats.
-
Execució dels scripts d'arrancada. El sistema d'inicialització executa els scripts d'arrancada definits per a cada runlevel. Aquests scripts són responsables de configurar els serveis i daemons del sistema, com ara la xarxa, els dispositius de maquinari, els sistemes de fitxers, entre altres.
-
Inici de la Sessió d'Usuari. Finalment, el sistema està preparat per a l'usuari. Si el sistema està configurat per a un entorn gràfic, es carrega el gestor de finestres o l'entorn d'escriptori. En sistemes sense entorn gràfic, es presenta una línia de comandes. En aquest punt, l'usuari pot iniciar sessió i començar a utilitzar el sistema.
-
Execució dels scripts d'inici de sessió. Un cop iniciada la sessió, s'executen els scripts d'inici de sessió de l'usuari. Aquests scripts poden configurar variables d'entorn, carregar programes o configurar preferències de l'usuari. Això permet personalitzar l'experiència de l'usuari i preparar l'entorn de treball.
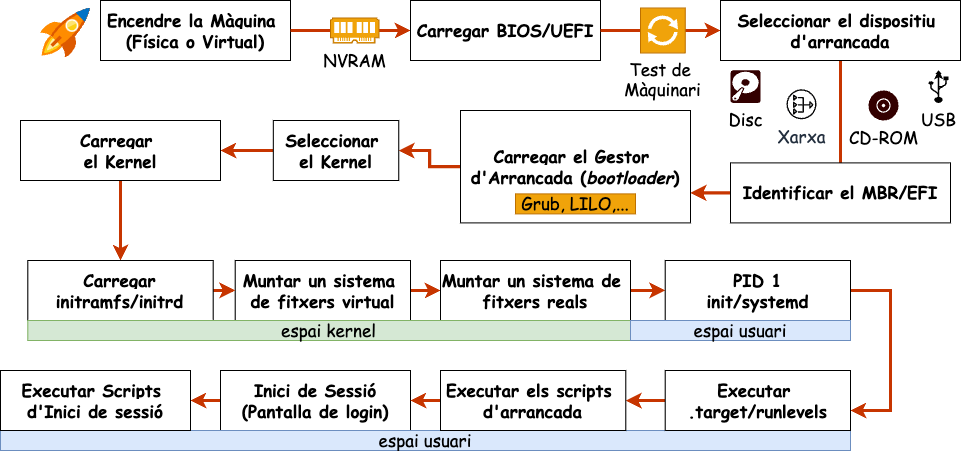
En aquest laboratori veurem totes aquestes fases en una màquina virtual i modificarem els paràmetres per veure com afecten als sistemes.
Objectius
- Entendre com funciona el procés d'arrancada del sistema.
- Conèixer els diferents components implicats en l'arrancada del sistema.
- Apendre a gestionar i optimitzar el procés d'arrancada.
Continguts
Activitats
Realització de les tasques: 50%
S'ha de mostrar en un document amb format lliure les evidències de la realització de les tasques. Aquest document es pot incloure al informe tècnic o es pot lliurar com a document adjunt. En aquest document heu de mostrar les dificultats trobades i com les heu resolt. Us recomano que feu servir eines de captura de pantalla per a mostrar les evidències. Per exemple, podeu incloure una secció anomenada Troubleshooting on mostreu les dificultats trobades i com les heu resolt.
Informe tècnic: 50%
El informe tècnic ha de contenir respostes a les preguntes plantejades a continuació:
-
Investigació d'una unitat del sistema
- Elegeix una unitat del sistema, com ara
ssh.service, i investiga la seva funció i configuració. - Utilitza les comandes
systemctl statusisystemctl catper obtenir més informació sobre la unitat. - Inclou a l'informe els resultats de la teva investigació:
- Descripció de la unitat.
- Documentació associada.
- Dependències i condicions.
- Tipus de servei i comandaments d'inici i parada.
- Temps d'execució i estat actual.
- Elegeix una unitat del sistema, com ara
-
Comparació entre arrencada amb i sense interfície gràfica
- Instal·la la interfície gràfica utilitzant la comanda
taskseli selecciona l'opcióDebian desktop environment. - Compara el temps d'arrencada del sistema amb i sense interfície gràfica utilitzant la comanda
systemd-analyze. - Inclou al informe de la diferència entre arrencar el sistema amb una interfície gràfica i sense interfície gràfica, incloent:
- Temps d'arrencada del kernel i l'espai d'usuari.
- Unitats crítiques i temps d'arrencada.
- Avantatges i desavantatges de cada configuració
- Instal·la la interfície gràfica utilitzant la comanda
-
Dissenyeu un escenari real on un script d'arrancada podria ser útil
- Pensa en un escenari real on un script d'arrancada podria ser útil per configurar l'entorn de l'usuari.
- Crea un script d'arrancada que realitzi una tasca específica en aquest escenari.
- Configura el script d'arrancada perquè s'executi automàticament quan un usuari inicia una sessió de terminal.
- Inclou a l'informe amb els detalls de l'escenari i el script d'arrancada, incloent:
- Descripció de l'escenari i la tasca a realitzar.
- Contingut del script d'arrancada.
- Configuració del script d'arrancada per a l'usuari.
Rúbriques d'avaluació
| Criteris d'avaluació | Excel·lent (5) | Notable(3-4) | Acceptable(1-2) | No Acceptable (0) |
|---|---|---|---|---|
| Contingut | El contingut és molt complet i detallat. S'han cobert tots els aspectes de la tasca. | El contingut és complet i detallat. S'han cobert la majoria dels aspectes de la tasca. | El contingut és incomplet o poc detallat. Falten alguns aspectes de la tasca. | El contingut és molt incomplet o inexistent. |
| Precisió i exactitud | La informació és precisa i exacta. No hi ha errors. | La informació és precisa i exacta. Hi ha pocs errors. | La informació és imprecisa o inexacta. Hi ha errors. | La informació és molt imprecisa o inexacta. Hi ha molts errors. |
| Organització | La informació està ben organitzada i estructurada. És fàcil de seguir. | La informació està organitzada i estructurada. És fàcil de seguir. | La informació està poc organitzada o estructurada. És difícil de seguir. | La informació està molt poc organitzada o estructurada. És molt difícil de seguir. |
| Diagrames i il·lustracions | S'han utilitzat diagrames i il·lustracions de collita pròpia per aclarir la informació. Són molt útils. | S'han utilitzat diagrames i il·lustracions de collita pròpia per aclarir la informació. Són útils. | S'han utilitzat pocs diagrames o il·lustracions de collita pròpia. Són poc útils. | No s'han utilitzat diagrames o il·lustracions de collita pròpia. |
| Plagi | No hi ha evidències de plagi. Tota la informació és original. | Hi ha poques evidències de plagi. La majoria de la informació és original. | Hi ha evidències de plagi. Alguna informació no és original. | Hi ha moltes evidències de plagi. Poca informació és original. |
| Bibliografia | S'ha inclòs una bibliografia completa i detallada. | S'ha inclòs una bibliografia completa. | S'ha inclòs una bibliografia incompleta. | No s'ha inclòs una bibliografia. |
| Estil | L'estil és molt adequat i professional. S'ha utilitzat un llenguatge tècnic precís. | L'estil és adequat i professional. S'ha utilitzat un llenguatge tècnic precís. | L'estil és poc adequat o professional. Hi ha errors en el llenguatge tècnic. | L'estil és molt poc adequat o professional. Hi ha molts errors en el llenguatge tècnic. |
UEFI i dispositius d'arrancada
El Unified Extensible Firmware Interface (UEFI) és un estàndard de firmware dissenyat per reemplaçar els dissenys antics anomenats BIOS. Els principals problemes de les BIOS eren la falta d'estandardització.
ℹ️ UEFI o EFI?
La UEFI i la EFI són pràcticament el mateix. La EFI va ser el primer estàndard, però amb el temps va evolucionar cap a la UEFI actual.
En aquest laboratori, analitzarem el funcionament de la UEFI i com podem utilitzar-la.
Objectius
- Conèixer el funcionament de la UEFI.
- Impacte de la UEFI en l'arrancada del sistema.
- Apendre les funcions bàsiques de la consola UEFI.
- Configurar la UEFI per a diferents finalitats.
Preparació
-
Inicieu una màquina virtual amb el sistema operatiu AlmaLinux anomenada
VM1. Podeu utilitzar la configuració per defecte. -
Inicieu una altra màquina virtual amb el sistema operatiu Debian anomenada
VM2. Podeu utilitzar també la configuració per defecte. -
Afegiu a la màquina virtual
VM1el disc virtual de la màquina virtualVM2o viceversa. Per fer-ho amb VMWare:- Apagueu la màquina virtual.
- Aneu a la configuració de la màquina virtual.
- Aneu a Add.
- Selecciona Hard Disk.
- Selecciona Use an existing disk.
- Selecciona el disc virtual de la màquina virtual que vulgueu afegir.
- Inicieu la màquina virtual.
Un cop iniciada la màquina virtual, no hauríeu de detectar cap canvi. No obstant això, si inicieu sessió a la màquina virtual, podreu veure el disc afegit utilitzant la comanda
lsblk.[root@localhost ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sr0 11:0 1 1.7G 0 rom nvme0n1 259:0 0 20G 0 disk ├─nvme0n1p1 259:1 0 600M 0 part /boot/efi ├─nvme0n1p2 259:2 0 1G 0 part /boot └─nvme0n1p3 259:3 0 18.4G 0 part ├─almalinux-root 253:0 0 16.4G 0 lvm / └─almalinux-swap 253:1 0 2G 0 lvm [SWAP] nvme0n2 259:4 0 20G 0 disk ├─nvme0n2p1 259:5 0 512M 0 part ├─nvme0n2p2 259:6 0 18.5G 0 part └─nvme0n2p3 259:7 0 976M 0 partOn
nvme0n2és el disc afegit que conté la instal·lació de Debian invme0n1és el disc original que conté la instal·lació d'AlmaLinux.
Tasques
- Inciant la consola UEFI
- Observant els Dispositius Disponibles
- Navegant per la Consola UEFI
- Arrancant des d'una Partició EFI
- Automatitzant l'Arrancada
- Creant una Entrada d’Arrancada Personalitzada
Inciant la consola UEFI
Per accedir a la consola UEFI, seguiu aquests passos:
-
Inicieu la màquina virtual
VM1. -
Premeu la tecla ``ESC`durant l'arrencada de la màquina virtual per accedir a Boot Manager.
-
Seleccioneu EFI Internal Shell per accedir a la consola UEFI.

La consola UEFI és una interfície de text que permet interactuar amb el firmware de la màquina. El primer que necessiteu saber es com interactuar amb la consola. Per això, podeu utilitzar la comanda help per obtenir una llista de comandes disponibles.
Observant els Dispositius Disponibles
Un dels usos més comuns de la consola UEFI és la selecció del dispositiu d'arrancada. Per veure quins dispositius estan disponibles, podeu utilitzar la comanda map.
Shell> map
Aquesta comanda us mostrarà una llista de tots els dispositius disponibles i les seves adreces. Això us permetrà identificar quin dispositiu voleu utilitzar per a l’arrancada. En el nostre cas, us retornarà una llista similar a aquesta:
-
FS0: Alias(s):CD0B0A0;;BLK1: PciRoot(OxO)/Pci(0x11,0x0)/Pci(0x3,0x0)/Sata(0x1,0x0,0x0)/CDROM(0x0) -
FS1: Alias(s):HD1b;;BLK3: PciRoot(0x0)/Pci(0x17,0x0)/Pci(0x0,0x0)/NVMe(0x1,00-00-00-00-00-00-00-00)/HD(1,GPT,61942D3C-DD95-47F4-8C57-C22009E9C7BA,0x800,0x12C000) -
FS2: Alias(s):HD2b;;BLK7: PciRoot(0x0)/Pci(0x17,0x0)/Pci(0x0,0x0)/NVMe(0x2,00-00-00-00-00-00-00-00)/HD(1,GPT,8DD9095B-5B0C-45A3-A026-33DE34ED23B5,0x800,0x10000) -
BLK0: Alias(s): PciRoot(0x0)/Pci(0x11,0x0)/Pci(0x3,0x0)/Sata(0x1,0x0,0x0) -
BLK2: Alias(s): PciRoot(0x0)/Pci(0x17,0x0)/Pci(0x0,0x0)/NVMe(0x1,00-00-00-00-00-00-00-00) -
BLK6: Alias(s): PciRoot(0x0)/Pci(0x17,0x0)/Pci(0x0,0x0)/NVMe(0x2,00-00-00-00-00-00-00-00) -
BLK4: Alias(s): PciRoot(0x0)/Pci(0x17,0x0)/Pci(0x0,0x0)/NVMe(0x1,00-00-00-00-00-00-00-00)/HD(2,GPT, 7D330E0D-0E09-440C-A79D-9239BD9F11C0,0x12C800,0x200000) -
BLK5: Alias(s): PciRoot(0x0)/Pci(0x17,0x0)/Pci(0x0,0x0)/NVMe(0x1,00-00-00-00-00-00-00-00)/HD(3,GPT, 94B55114-4795-4748-AD0E-BB068D437691,0x32C800,0x24D3000) -
BLK8: Alias(s): PciRoot(0x0)/Pci(0x17,0x0)/Pci(0x0,0x0)/NVMe(0x2,00-00-00-00-00-00-00-00)/HD(2,GPT, 760F1F2F-BA6F-479C-8D4D-8FA31D9226F6,0x100800,0x251700) -
BLK9: Alias(s): PciRoot(0x0)/Pci(0x17,0x0)/Pci(0x0,0x0)/NVMe(0x2,00-00-00-00-00-00-00-00)/HD(3,GPT, CD375C90-A2BA-4507-9263-55BE97B26672,0x2617800,0x1E8000)
En aquest cas, tenim 3 sistemes de fitxers (FS0, FS1, FS2) i diversos dispositius de bloc (BLK0, BLK2, BLK6, BLK4, BLK5, BLK8, BLK9).
Els sistemes de fitxers representen dispositius que contenen un sistema de fitxers que la UEFI pot llegir. Això inclou dispositius com discos durs, SSDs, i CD-ROMs. Per exemple, FS0 representa un CD-ROM, mentre que FS1 i FS2 representen discos durs.
Els dispositius de bloc representen dispositius de baix nivell que no necessàriament tenen un sistema de fitxers que la UEFI pot llegir. Això inclou dispositius com discos durs, SSDs, i CD-ROMs, així com particions individuals dins d’aquests dispositius.
En els sistemes EFI, hi ha una partició especial anomenada Partició de Sistema EFI (ESP) que conté els fitxers d’arrancada del sistema operatiu. Aquesta partició es pot identificar pel seu tipus de sistema de fitxers EFI. Normalment utilitza un sistema de fitxers basat en FAT32. En aquest cas, els sistemes de fitxers FS1 i FS2 són les particions ESP dels discos durs NVMe1 i NVMe2 respectivament. A més, podem veure que els dos discos durs NVMe1 i NVMe2 tenen una taula de particions GPT i que la primera partició correspon a la partició ESP. Es pot veure el seu UUID, l’adreça d’inici i l’adreça final de la partició.
👁️ Observació
Les particions EFI sempre acostumen ser la primera partició de la taula de particions GPT. Això es deu a que UEFI sempre busca la partició EFI per carregar el gestor d’arrancada.
Els dispositius de bloc representen els discos durs i les seves particions. En aquest cas, tenim dos discos durs NVMe1 i NVMe2 amb les seves particions. Fixeu-vos que podem identificar el disc NVMe1 o NVMe2 amb BLK2 o BLK6 respectivament. A més, podem veure les particions del disc NVMe1 amb BLK4 i BLK5 i les particions del disc NVMe2 amb BLK8 i BLK9. En totes les entrades es pot veure el UUID de la taula de particions GPT, l’adreça d’inici i l’adreça final de la partició.
👁️ Observació
La etiqueta NVMe indica que el disc és un disc NVMe. Si el disc fos un disc SATA, la etiqueta seria SATA. En funció del hardware de la màquina virtual, els discos poden tenir diferents etiquetes.
Navegant per la Consola UEFI
Un cop identificats els dispositius disponibles, podeu utilitzar la consola UEFI per navegar per ells. Per exemple, per accedir a la partició ESP del disc NVMe1, podeu utilitzar la següent comanda:
Shell> fs1:
Això canviarà el directori de treball actual a la partició ESP del disc NVMe1. Si ara voleu accedir a fs2, podeu utilitzar la comanda fs2:.
Shell> fs2:
⚠️ Compte La consola UEFI acostuma a tenir un keymap diferent al vostre. Els caràcters poden no ser els mateixos que els que veieu a la pantalla. Per exemple, la tecla
:pot serño la tecla/pot ser-. Si teniu problemes amb les tecles podeu consultar el keymap de VMWare a la documentació oficial.
Un cop hàgiu accedit a una partició, podeu utilitzar la comanda ls per veure el contingut de la partició.
FS1:\> ls
La comanda ls us mostrarà una llista dels fitxers i directoris del directori actual. En aquest cas, veureu els fitxers i directoris del directori arrel de la partició ESP.
Finalment, podeu utilitzar la comanda cd per canviar de directori.
FS1:\> cd EFI
FS1:\EFI> ls
FS1:\EFI> cd ..
Arrancant des d'una Partició EFI
Per arrancar la màquina virtual VM1 amb el disc NVMe2 seleccionat com a dispositiu d'arrancada (això carregarà el sistema operatiu Debian), seguiu aquests passos:
-
Navegueu a la partició ESP del disc NVMe2.
Shell> fs2: -
Navegueu al directori
EFIi seleccioneu el directori del sistema operatiu Debian.FS2:\> cd EFI FS2:\EFI> cd debian -
Llisteu el contingut del directori per veure els fitxers d'arrancada.
En aquest directori, podeu observar diferents fitxers que acaben amb
.efi. Aquests fitxers són els fitxers d'arrancada del sistema operatiu Debian. El nom ens indica el tipus de firmware que utilitzen. Per exemple,grubaa64.efiés el fitxer d'arrancada del gestor d'arrancada GRUB per a sistemes de 64 bits.ℹ️ Quina és la diferència entre shimx64.efi, grubx64.efi, fbx64, mmx64?
Les principals diferències entre aquests fitxers són el tipus de firmware que utilitzen i la seva funció. El fitxer
shimx64.efiés un fitxer d'arrancada segur que permet carregar altres fitxers d'arrancada segurs. El fitxergrubx64.efiés el fitxer d'arrancada del gestor d'arrancada GRUB. Els fitxersfbx64.efiimmx64.efino són específics de cap sistema operatiu, sinó que són part del firmware UEFI i proporcionen funcionalitats addicionals. -
Seleccioneu el fitxer d'arrancada del grub per a arrancar el sistema operatiu Debian.
FS2:\EFI\debian> grubaa64.efi
Això carregarà el gestor d'arrancada GRUB i us permetrà seleccionar el sistema operatiu Debian per a l'arrancada.
Automatitzant l'Arrancada
👁️ Observació:
Aquest procediment és una mica tedios i ens pot resultar poc eficient si hem d'arrencar el sistema operatiu Debian sovint.
Per automatitzar l'arrancada del sistema operatiu Debian, podeu utilitzar la comanda boot de la consola UEFI. Aquesta comanda us permetrà carregar un fitxer d'arrancada directament sense haver de navegar per la partició ESP.
boot fs2:\EFI\debian\grubaa64.efi
Tot i que aquesta comanda pot ser útil, encara requereix accedir manualment a la consola UEFI i introduir la comanda. Per tant, ara veurem com crear una entrada d'arrancada personalitzada a la taula d'arrancada de la UEFI semblant a la ja existent per a l'arrancada d'AlmaLinux anomenda AlmaLinux.
Creant una Entrada d’Arrancada Personalitzada
La UEFI manté una taula d’arrancada que conté una llista d’entrades d’arrancada. Cada entrada correspon a un sistema operatiu o aplicació que pot ser arrancada per la UEFI. Per exemple, si tenim instal·lats els sistemes operatius AlmaLinux i Debian en la mateixa màquina, cada un tindrà la seva pròpia entrada d’arrancada a la taula d’arrancada de la UEFI.
Per crear una nova entrada d’arrancada per al sistema operatiu Debian, podem utilitzar la comanda bcfg de la consola UEFI. Aquesta comanda proporciona una interfície per gestionar la taula d’arrancada de la UEFI.
-
Reinicieu la màquina virtual i accediu a la consola UEFI.
-
Utilitzeu la comanda bcfg boot add per crear una nova entrada d’arrancada. Per exemple, per afegir una nova entrada amb el nom Debian i el fitxer BOOTAA64.EFI de la partició FS2, utilitzeu la següent comanda:
bcfg boot add 6 fs2:\EFI\debian\grubaa64.efi DebianEn aquesta comanda, 6 és el número de la nova entrada a la UEFI. Aquest número ha de ser únic i no pot ser repetit. Si ja tenim una entrada amb el número 3, haurem de canviar el número per un altre número que no estigui en ús. Per saber quins números estan en ús, podem utilitzar la comanda
bcfg boot dump. -
Un cop creada la nova entrada d’arrancada, podem voler canviar la seva posició a la llista d’arrancada. Per exemple, si volem que la nova entrada sigui la segona opció d’arrancada, podem utilitzar la comanda:
bcfg boot mv 6 1En aquesta comanda, 6 és el número de l’entrada que volem moure, i 1 és la nova posició de l’entrada a la llista d’arrancada.
✏️ Nota:
Els items es numeren de 0 a n-1, on n és el nombre d'entrades.
-
Ara tenim la entrada AlmaLinux i Debian a la UEFI. Podem sortir de la consola UEFI i reiniciar la màquina virtual. Ara, quan accedim a la consola UEFI, veurem dues opcions: AlmaLinux i Debian.
Amb aquesta configuració, podem seleccionar quin sistema operatiu volem arrancar directament des del menú d’arrancada de la UEFI, sense haver d’accedir a la consola UEFI.
GRUB
El GRUB (Grand Unified Bootloader) és un gestor d'arrancada que s'utilitza en la majoria de les distribucions de GNU/Linux. El UEFI és l'encarregat de carregar el GRUB, En aquest laboratori veurem com funciona el GRUB i com podem configurar-lo per a arrancar amb diferents sistemes operatius.
👁️ Observació:
GRUB no és l'únic gestor d'arrancada que es pot utilitzar en un sistema GNU/Linux. Però és el més comú i el que s'utilitza per defecte en la majoria de les distribucions. Altres gestors d'arrancada com el LILO (Linux Loader) o rEFInd també són compatibles amb GNU/Linux.
Preparació
-
Entorn de treball: Màquina virtual amb una distribució GNU/Linux instal·lada pot ser Debian o AlmaLinux. La màquina virtual pot tenir una configuració per defecte. Característiques de la màquina virtual:
- Disc dur virtual de 20 GB.
- 1 CPU.
- 1 GB de memòria RAM.

A més, inicialitzeu com a mínim un usuari root amb contrasenya (pot ser 1234).
✏️ Nota:
En el meu cas he utilitzat una màquina virtual amb la imatge de Debian 12 proporcionada al inici de curs al campus virtual.
Tasques
- Modificació de les opcions del GRUB
- Accés no autoritzat a través del GRUB
- Dual Boot
- Anàlisi del procediment
- Actualitzant el GRUB
Modificació de les opcions del GRUB
Com heu pogut observar, la instal·lació del sistema operatiu Debian 12 ha configurat el GRUB de forma predeterminada.
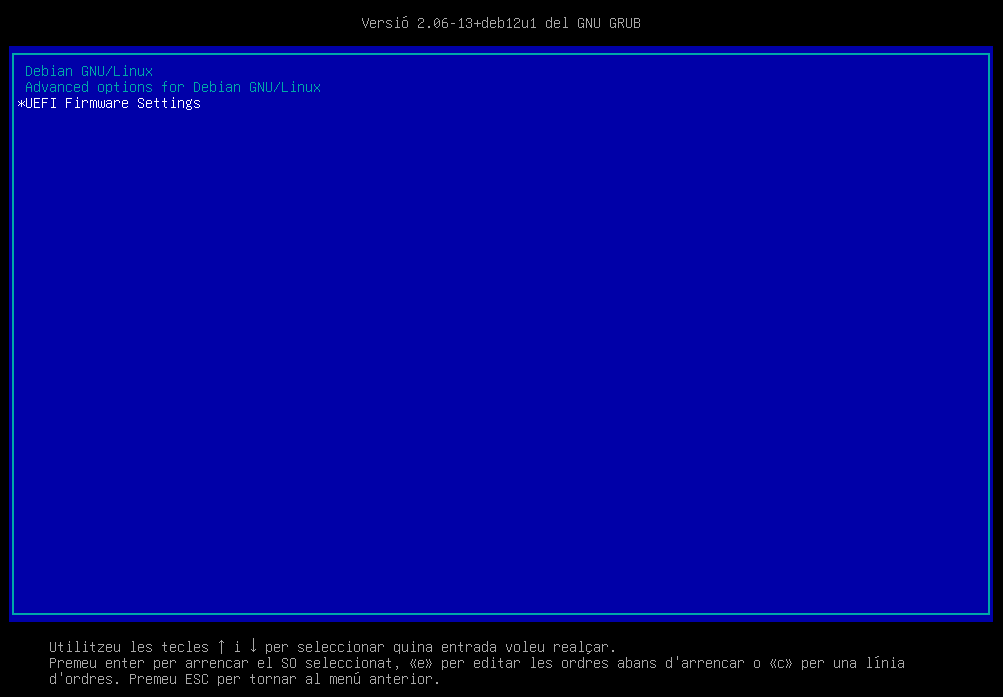
En aquesta pantalla, podeu observar 3 entrades:
-
Debian GNU/Linux. Aquesta és l'entrada per defecte que carrega el sistema operatiu Debian 12.
-
Advanced options for Debian GNU/Linux. Aquesta entrada permet seleccionar una versió específica del kernel per a carregar.
En el nostre cas, podem seleccionar entre la versió 6.1.0-23 i la 6.1.0-18 ambdues amb les opcions
recovery mode.ℹ️ Què és el mode de recuperació?
El mode de recuperació és un mode d'arrancada que carrega el sistema amb un conjunt de paràmetres mínims. Això permet accedir al sistema en un estat més bàsic i realitzar tasques de manteniment o recuperació del sistema.
-
UEFI Firmware Settings. Aquesta entrada permet accedir a la configuració de la UEFI.
Modificació de les opcions del GRUB (temporal)
Seleccioneu l'entrada Debian GNU/Linux i premeu la tecla e per a editar les opcions de l'arrencada de forma temporal, és a dir, aquestes opcions només es mantindran durant l'arrencada actual del sistema.
En aquesta pantalla, podeu observar les opcions de l'arrencada del sistema. Si analitzem la informació tenim:
-
Carreguem els mòduls del kernel:
ℹ️ Per què carreguem aquests mòduls?
Els mòduls del kernel són programes que s'executen en l'espai del nucli del sistema operatiu. Aquests mòduls permeten al sistema operatiu interactuar amb el maquinari de l'ordinador. En aquest cas, carreguem els mòduls necessaris per a interactuar amb el disc dur i el sistema de fitxers.
- load_video: Aquest mòdul s’encarrega de la inicialització del subsistema de vídeo. És necessari per a la correcta visualització de la interfície gràfica durant l’arrancada.
- insmod gzio: Aquest mòdul permet al kernel llegir fitxers comprimits en format gzip. És útil per a carregar imatges del kernel o del sistema d’inicialització que estiguin comprimits.
- insmod part_gpt: Aquest mòdul permet al kernel llegir particions de disc que utilitzen la taula de particions GUID (GPT). GPT és un estàndard modern per a la disposició de la taula de particions en un disc dur.
- insmod ext2: Aquest mòdul permet al kernel llegir i escriure en sistemes de fitxers ext2. Ext2 és un sistema de fitxers comú en Linux, encara que ara s’utilitza menys en favor de ext3 i ext4.
-
Indiquem el dispositiu on es troba el sistema operatiu:
- search --no-floppy --fs-uuid --set=root xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
on
xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxés l'identificador únic del dispositiu on es troba el sistema operatiu. -
Carreguem el kernel del sistema operatiu;
- linux /boot/vmlinuz-6.1.0.23-arm64 root=UUID=xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx ro quiet
on les opcions són:
ro: indica que el sistema s'ha de muntar en mode de només lectura.quiet: indica que el sistema s'ha de carregar sense mostrar missatges.
-
Finalment, carreguem el sistema d'inicialització:
- initrd /boot/initrd.img-6.1.0.23-arm64
ℹ️ Què és el sistema d'inicialització?
El sistema d'inicialització és el primer procés que s'executa en un sistema operatiu. En el cas de GNU/Linux, el sistema d'inicialització més comú és el systemd. Aquest sistema d'inicialització s'encarrega de carregar els serveis i els daemons del sistema operatiu.
Modifiquem les opcions de l'arrencada per mostrar els missatges del sistema durant l'arrencada. Per a fer-ho, eliminem l'opció quiet de la línia linux i premem la tecla ctrl+x o F10 per a iniciar el sistema amb les opcions modificades.
Ara, el sistema mostrarà els missatges durant l'arrencada.
Modificació de les opcions del GRUB (permanent)
Aquestes opcions només es mantindran durant l'arrencada actual del sistema. Per a fer que aquestes opcions es mantinguin de forma permanent, haurem de modificar el fitxer de configuració del GRUB. Aquest fitxer normalment es troba a /etc/default/grub.
-
Accedeix al sistema amb l'usuari root.
-
Fes una còpia de seguretat del fitxer de configuració del GRUB.
cp /etc/default/grub /etc/default/grub.bak -
Edita el fitxer de configuració del GRUB amb un editor de text com
vi.vi /etc/default/grubObservareu un fitxer similar al:

-
Busca la línia que comença amb
GRUB_CMDLINE_LINUX_DEFAULTi modifica-la per a afegir les opcions que vulguis. Per exemple, per a mostrar els missatges del sistema durant l'arrencada, elimina l'opcióquiet.💡 Nota:
Les opcions del GRUB es separen per espais. Per a afegir una nova opció, simplement afegeix-la a la llista separada per un espai.
🔍 Pregunta: Quines altres opcions podries afegir al fitxer de configuració del GRUB?
Algunes opcions comunes que es poden afegir al fitxer de configuració del GRUB són:
GRUB_TIMEOUT: temps d'espera per a seleccionar una entrada del GRUB.GRUB_DISABLE_OS_PROBER: per defecte, en debian es troba activada. Per tant, no detectarà altres sistemes operatius instal·lat en el sistema.
-
Desa els canvis i surt de l'editor de text.
-
Un cop hagis modificat el fitxer de configuració del GRUB, hauràs de regenerar el fitxer de configuració del GRUB amb la comanda següent:
update-grubAquesta comanda regenerarà el fitxer de configuració del GRUB amb les opcions que has definit. Aquest fitxer es troba a
/boot/grub/grub.cfg. Pots veure el contingut d'aquest fitxer amb la comanda següent:less /boot/grub/grub.cfg⚠️ Compte:
No modifiquis manualment el fitxer
/boot/grub/grub.cfg. Aquest fitxer es genera automàticament amb la comandaupdate-grubi qualsevol modificació manual es sobreescriurà en la propera generació del fitxer. -
Reinicia el sistema per a aplicar els canvis.
reboot
Un cop reiniciat el sistema, el GRUB carregarà el sistema amb les opcions que has definit. Ara, el sistema mostrarà els missatges durant totes les arrencades.
Accés no autoritzat a través del GRUB
Assumeix que teniu un servidor instal·lat amb un carregar de sistema GRUB. Un atacant ha conseguit accés físic al vostre servidor i vol modificar la contrasenya de l'usuari root per a poder accedir al sistema amb privilegis d'administrador. Per a fer-ho, l'atacant ha reiniciat el sistema i ha accedit al carregador de sistema GRUB. A continuació assumirem el rol i veurem com podem accedir al sistema operatiu i modificar la contrasenya de l'usuari root a través del carregador de sistema GRUB.
-
Reinicia el sistema i accedeix al carregador de sistema GRUB.
-
Selecciona el sistema operatiu que vols arrancar i prem la tecla
eper a editar les opcions de l'arrencada.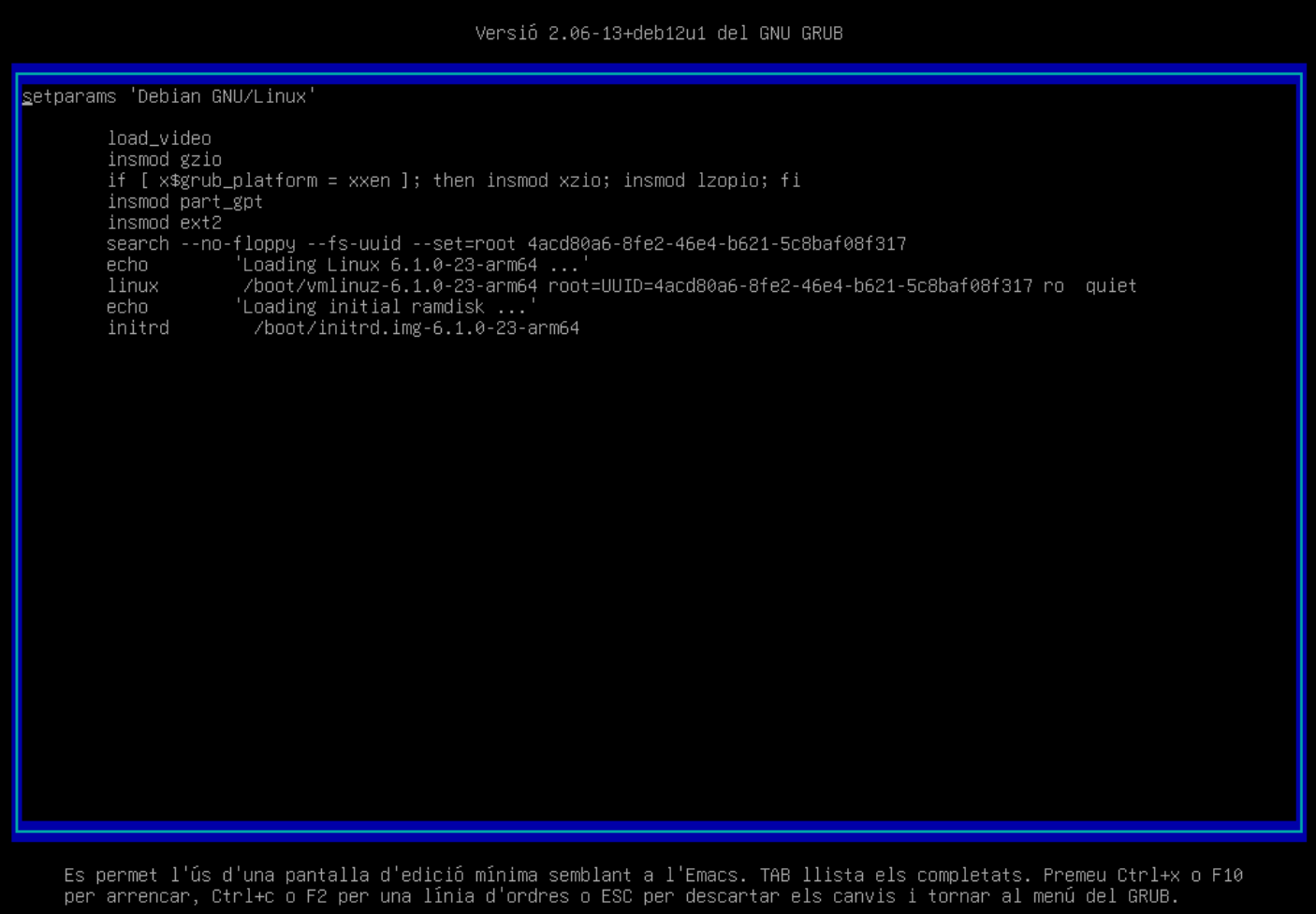
-
Busca la línia que comença amb
linuxi acaba ambroi afegeix-hi la següent opció:init=/bin/bash.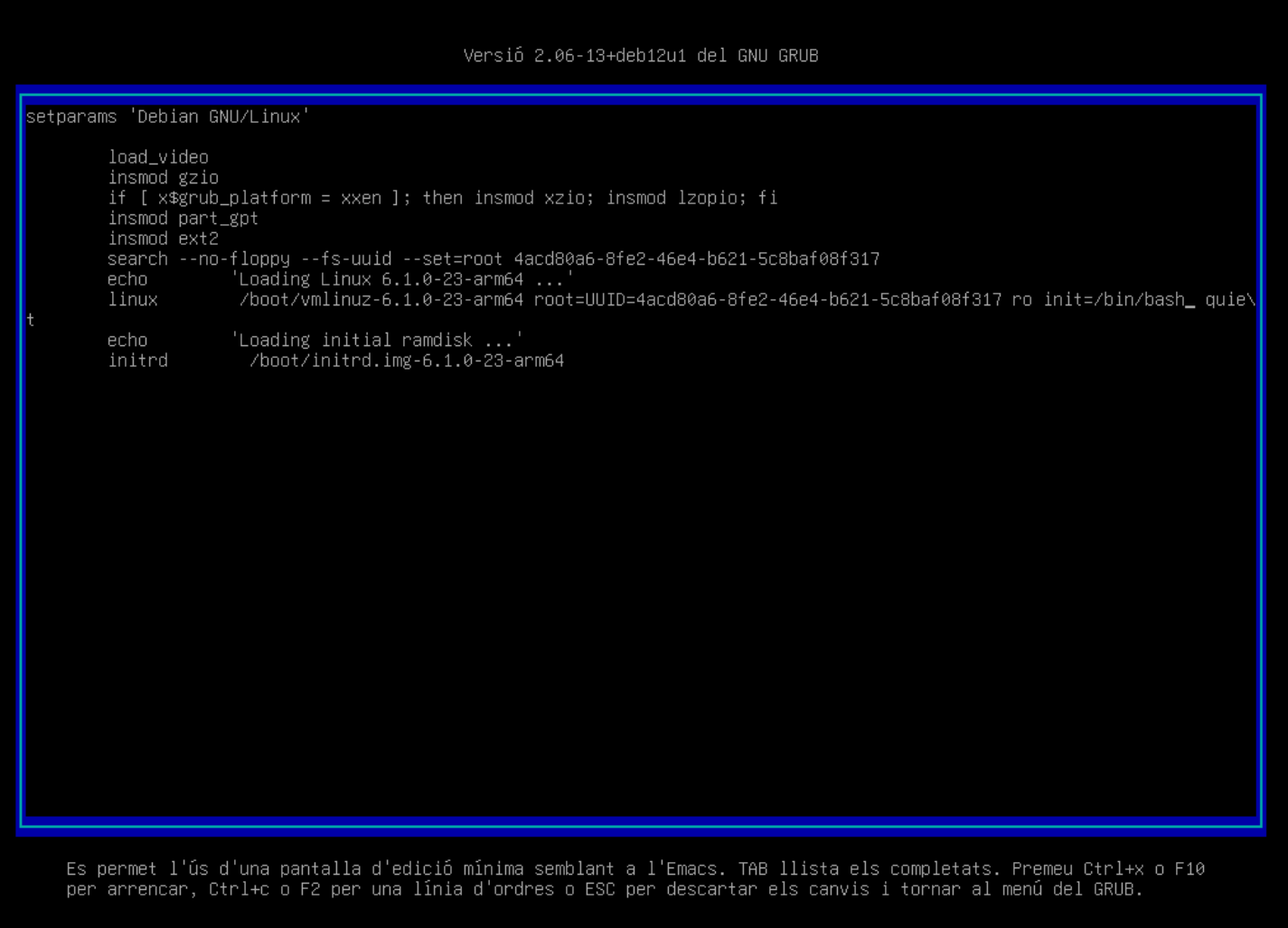
✏️ Nota:
La opció
roindica que el sistema s'ha de muntar en mode de només lectura. Això significa que no es poden modificar els fitxers del sistema. Afegint la opcióinit=/bin/bash, indiquem al sistema que ha d'iniciar el procés d'inicialització amb/bin/bashen lloc del sistema d'inicialització habitual. Això ens permetrà accedir al sistema amb un intèrpret de comandesbashsense haver d'iniciar el sistema completament. -
Prem la tecla
Ctrl + Xper a iniciar el sistema amb les opcions modificades. -
Un cop iniciat el sistema, hauries d'accedir a una consola
bash.
-
Un cop aquí, montarem el sistema de fitxers en mode de lectura i escriptura amb la comanda següent:
mount -o remount,rw / -
Ara que el sistema esta muntat, accedirem al sistema amb una chroot per a poder modificar la contrasenya de l'usuari root. Per a fer-ho, executa la comanda següent:
chroot /ℹ️ Què és una chroot?
Una chroot és un entorn aïllat que permet executar programes en un directori arrel diferent del directori arrel del sistema. Això ens permet accedir al sistema com si estiguéssim dins del directori arrel del sistema, però sense haver d'iniciar el sistema completament. Això és útil per a realitzar tasques de manteniment o recuperació del sistema sense haver d'iniciar el sistema completament.
-
Un cop dins de la chroot, modifica la contrasenya de l'usuari root amb la comanda
passwd:passwd -
Introdueix la nova contrasenya de l'usuari root i confirma-la.
-
Un cop modificada la contrasenya, surt de la chroot amb la comanda
exit:exit -
Reinicia el sistema amb la comanda
reboot:reboot -
Un cop reiniciat el sistema, accedeix amb l'usuari root i la nova contrasenya que has definit.
🔍 Pregunta: Com podriam protegir els nostres servidors d'aquestes situacions?
- La principal manera de protegir els servidors d'aquest tipus d'atacs és assegurar-se que només les persones autoritzades poden accedir físicament al servidor.
- Configurar el GRUB perquè requereixi una contrasenya per a poder editar les opcions de l'arrencada és una bona pràctica. Això dificulta l'accés no autoritzat al sistema a través del GRUB.
👁️ Observació:
Malgrat l'ús d'una contrasenya per a protegir el GRUB, aquesta tècnica no és infal·lible. Un atacant amb accés físic pot montar un usb bootable i iniciar el sistema amb aquest dispositiu. Un cop iniciat el sistema, l'atacant podria montar el sistema de fitxers i modificar la contrasenya de l'usuari root. Ara bé, es podria configurar el BIOS o UEFI per a desactivar l'arrencada des de dispositius externs com els USBs. Això dificultaria l'accés no autoritzat al sistema a través d'aquesta tècnica.
🤔 Reflexió: En les dues situacions, si el disc dur està xifrat, l'atacant no podrà utilitzar aquestes tècniques per a accedir al sistema.
Dual Boot
En aquesta tasca, configurarem el GRUB per a poder arrancar amb dos sistemes operatius diferents. Per a fer-ho, utilitzarem la màquina virtual on ja tenim instal·lat un sistema operatiu GNU/Linux. A continuació, instal·larem un segon sistema operatiu i configurarem el GRUB per a poder arrancar amb els dos sistemes operatius.
-
Muntatge de la iso a la màquina virtual. A continuació es mostra el procediment per VMWare, adapatar-lo al vostre hypervisor.
- Accedeix a la màquina virtual on tens instal·lat un sistema operatiu GNU/Linux.
- Selecciona la màquina virtual i apaga-la.
- Prem el boto en forma d'eina 🔧 per a obrir la configuració de la màquina virtual.

- A la pestanya
CD/DVD (SATA), selecciona la opcióUse ISO image filei selecciona la imatge ISO del sistema operatiu que vols instal·lar.
- Prem la tecla
OKper a tancar la finestra de configuració de la màquina virtual.
-
Arrancada de la màquina virtual amb la iso.
- Inicia la màquina virtual.
- Accedeix a la configuració UEFI.
- Selecciona el CD-ROM com a dispositiu d'arrancada.
- Accedeix al GRUB amb la imatge ISO del sistema operatiu que vols instal·lar. En aquest cas, Almalinux 9.4.
-
Instal·lació del sistema operatiu.
-
Segueix els passos d'instal·lació del sistema operatiu.
- Selecciona Destino de la instalación i prem Personalitzada.
- En aquest punt, el nostre disc virtual de 20 GB, té 4 particions ocupant tot l'espai.
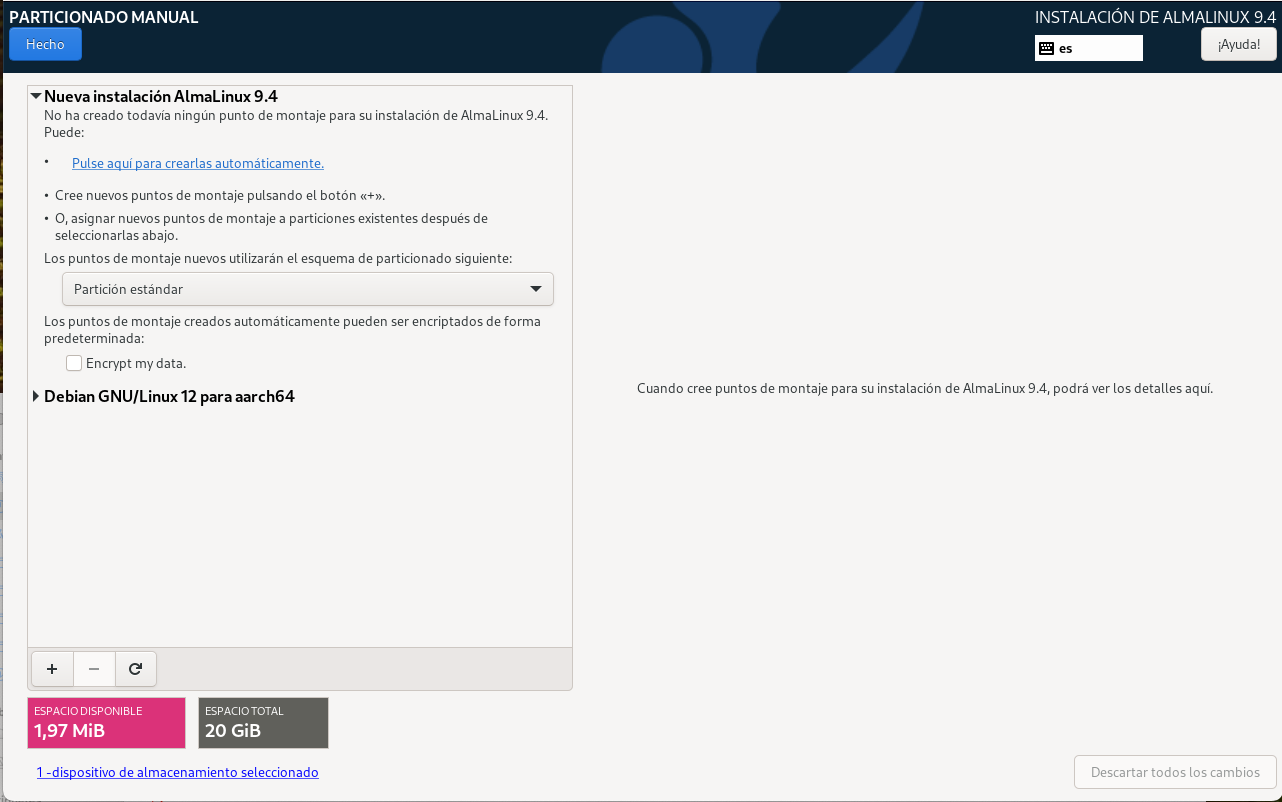
- Per poder instal·lar el nou sistema operatiu haurem de reimensionar la partició (/) per alliberar espai per a la nova partició, en el nostre cas podem alliberar 10 GB. La partició (/) es redueix de 18,54 GB a 8,54 GB. Simplement heu de modificar el valor númeric com mostro a la imatge.
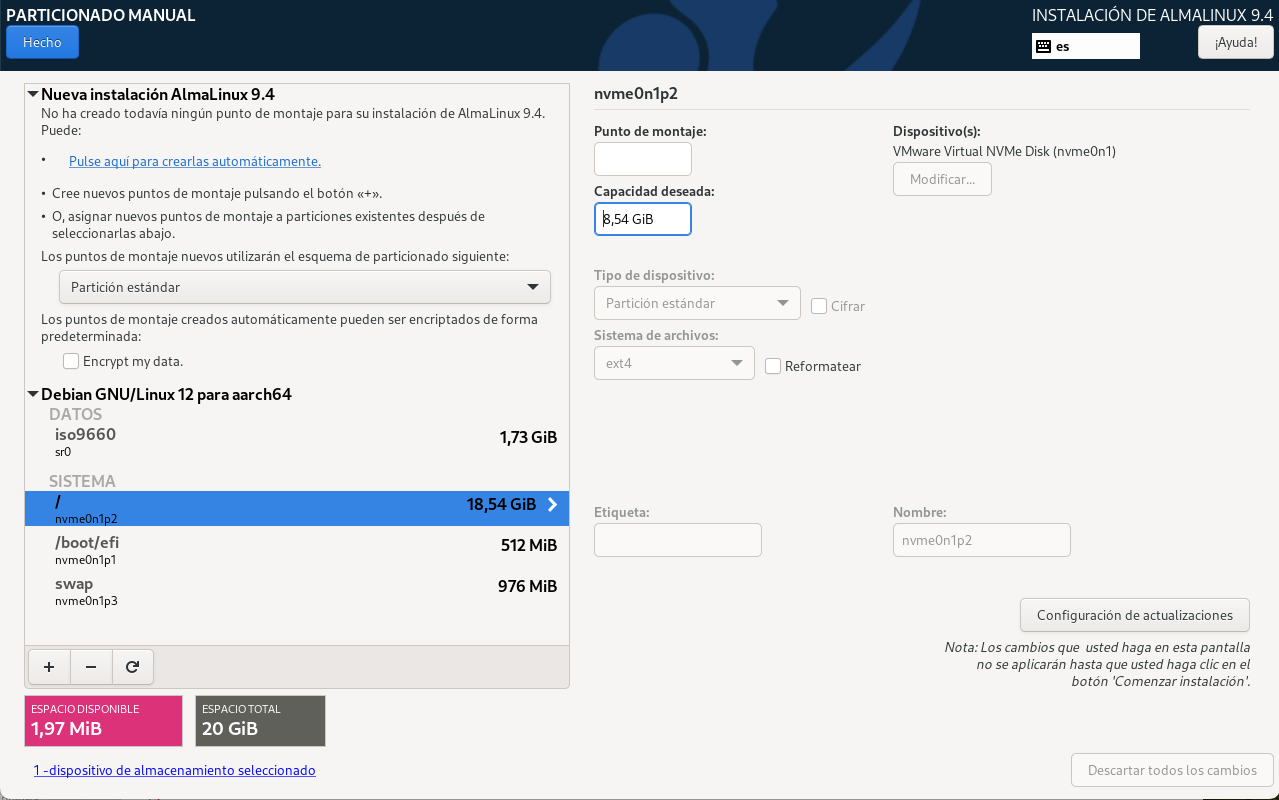
- Seleccioneu Partición estándar i premeu Pulse aqui para crearlas automáticamente.
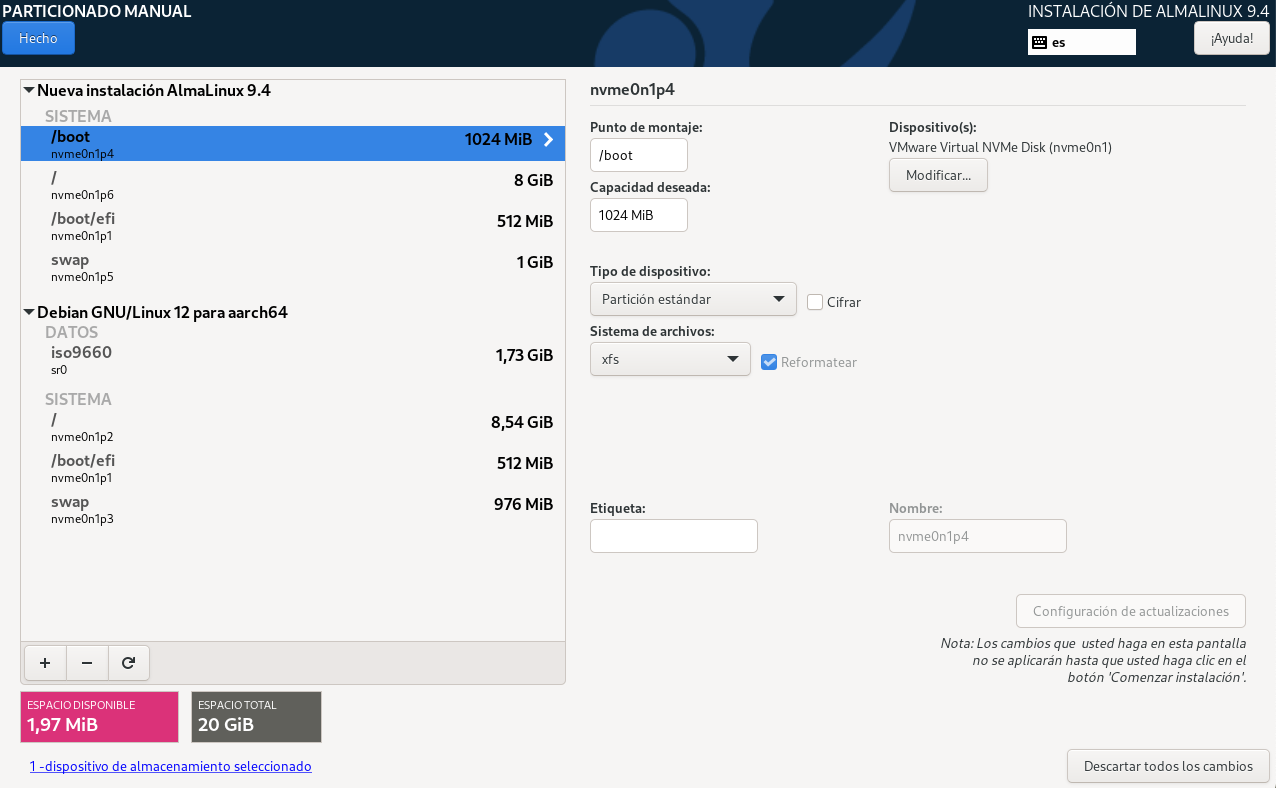
-
Assigna una contrasenya a l'usuari root i finalitza la instal·lació.
-
-
Test de l'arrancada del sistema.
- Reinicia la màquina virtual.
- Accedeix al GRUB i comprova que pots seleccionar el sistema operatiu que vols arrancar.
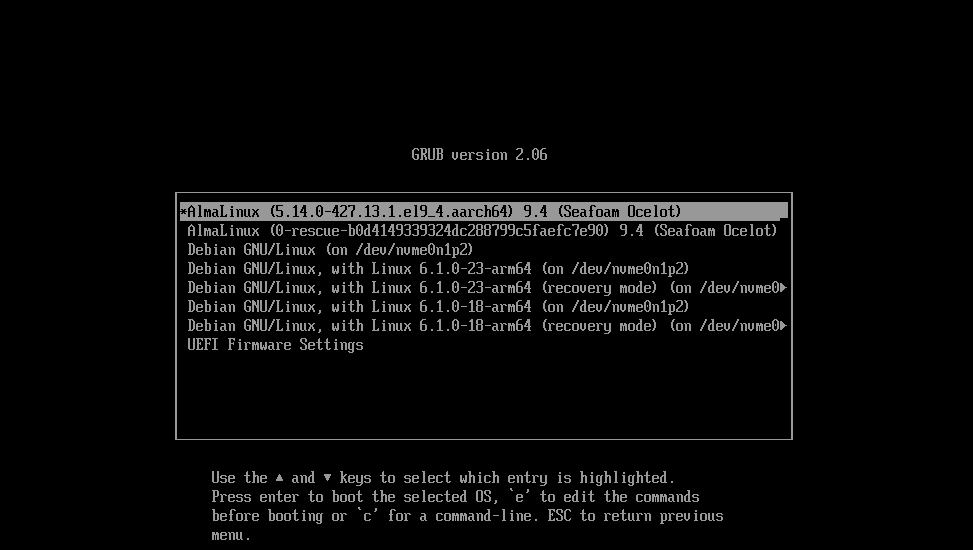
- Selecciona el sistema operatiu que has instal·lat i comprova que pots iniciar-lo correctament.
Anàlisi del procediment
El GRUB és un gestor d’arrancada que es configura automàticament durant la instal·lació d’un sistema operatiu. Quan instal·les un nou sistema operatiu, l’instal·lador detecta altres sistemes operatius presents en el mateix disc dur i crea entrades per a cada sistema operatiu en el fitxer de configuració del GRUB. Aquestes entrades permeten seleccionar quin sistema operatiu volem carregar durant l’arrancada del sistema.
A més, durant la instal·lació d’un nou sistema operatiu, es crea una nova entrada a la UEFI per a poder iniciar aquest nou sistema operatiu. Aquesta entrada s’ha creat amb la informació del nou GRUB, de manera que aquest conté les entrades dels dos sistemes operatius.
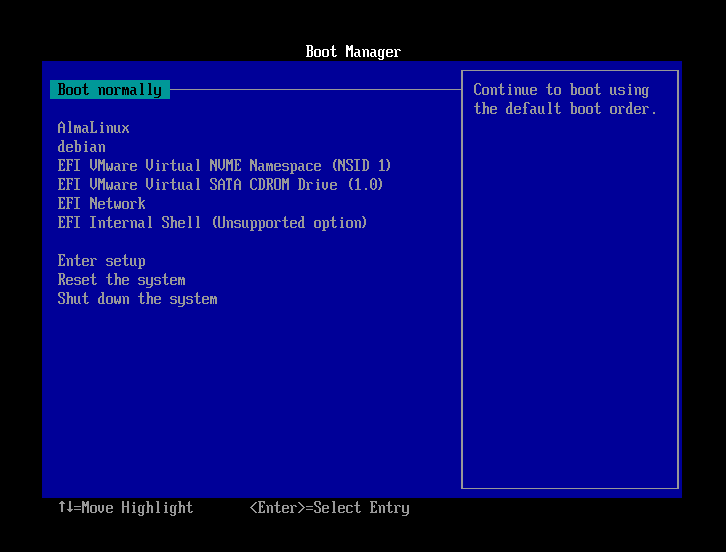
Si accediu a l’entrada inicial de la UEFI (debian), veureu que el GRUB únicament conté el sistema operatiu que teníem instal·lat inicialment. En canvi, si accediu a l’entrada nova de la UEFI (almalinux), veureu que el GRUB conté els dos sistemes operatius.
👁️ Observació:
Quan instal·les un sistema operatiu Windows després d’un sistema operatiu GNU/Linux, el GRUB es sobreescriu pel carregador d’arrancada de Windows. Això significa que no podràs accedir al sistema operatiu GNU/Linux des del GRUB. Per poder accedir al sistema operatiu GNU/Linux, hauràs de restaurar el GRUB. Aquesta restauració es pot realitzar mitjançant una unitat d’arrancada en viu (live boot) i utilitzant eines com ara
boot-repair.
Si compareu el grub de debian amb el d'almalinux, veure que estan organitzats de manera diferent. Això és degut a que cada distribució GNU/Linux té la seva pròpia configuració del GRUB. A més, cada distribució GNU/Linux pot utilitzar diferents versions del GRUB, amb diferents opcions i configuracions.
Actualitzant el GRUB
Actualitzant el GRUB de debian per a mostrar l'entrada d'almalinux
-
Accedeix a la màquina virtual on tens instal·lat el teu Debian.
-
Accedeix a la consola del sistema operatiu.
-
Edita el fitxer de configuració del GRUB de debian amb un editor de text com
vi.vi /etc/default/grub -
Descomenta la línia
GRUB_DISABLE_OS_PROBERi assigna-li el valorfalse.GRUB_DISABLE_OS_PROBER=false -
Desa els canvis i tanca l’editor de text.
-
Actualitza el fitxer de configuració del GRUB amb la comanda següent:
update-grub -
Reinicia el sistema amb la comanda següent:
reboot -
Accedeix al GRUB de debian a través de la UEFI i comprova que ara pots seleccionar l’entrada d’almalinux.
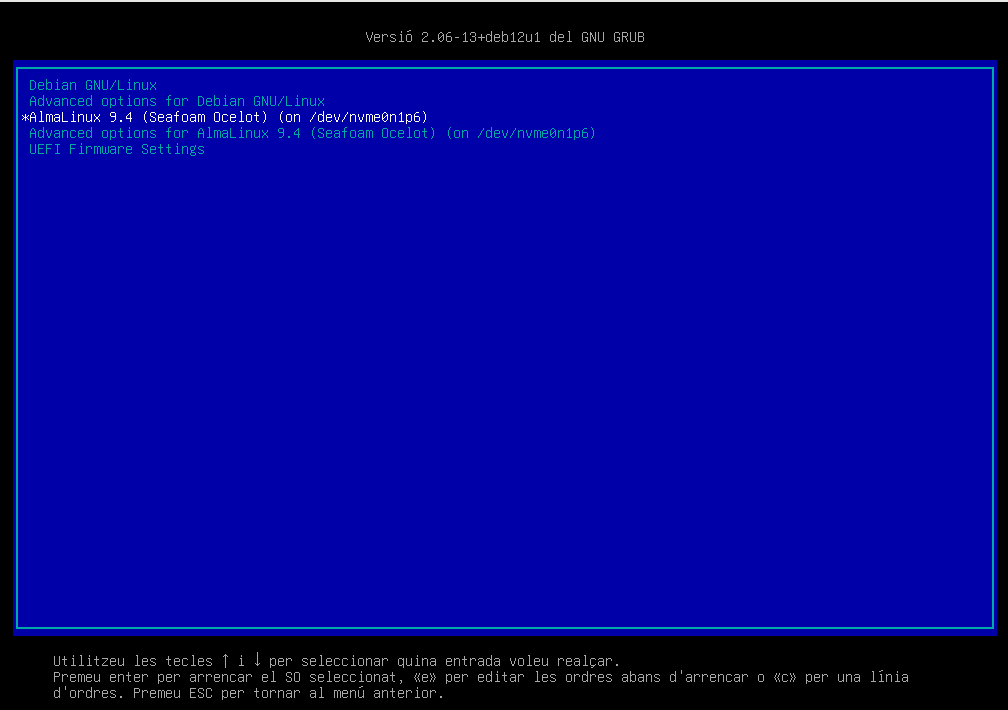
🤔 Reflexió: Quin GRUB és millor?
Indiferent. Cada distribució GNU/Linux configura el GRUB de manera diferent per a adaptar-lo a les seves necessitats i requeriments. Això significa que cada distribució GNU/Linux pot tenir una configuració del GRUB diferent, amb diferents opcions i configuracions. La millor configuració del GRUB és aquella que millor s’adapta a les necessitats del teu sistema.
initramfs
La initramfs (intial RAM filesystem) és un sistema de fitxers temporal que es munta a la arrel del sistema de fitxers (rootfs) durant el procés d'arrencada del sistema. La initramfs s'utilitza per realitzar tasques d'inicialització del sistema abans que el sistema de fitxers arrel real estigui disponible. Per exemple, la initramfs pot ser utilitzada per carregar mòduls del nucli, muntar dispositius de bloc, o realitzar tasques de configuració de xarxa.
Quin és el funcionament de la initramfs?
La initramfs és un arxiu comprimit que conté un sistema de fitxers mínim necessari per inicialitzar el sistema. Aquest arxiu es descomprimeix a la memòria RAM durant l'arrencada i s'utilitza com el sistema de fitxers arrel temporal. La initramfs inclou scripts i binaris essencials que permeten al sistema realitzar tasques crítiques abans que el sistema de fitxers arrel real estigui disponible.
Hi ha diverses situacions en les quals un administrador de sistemes podria necessitar modificar la initramfs:
-
Inclusió de mòduls del nucli addicionals: Si el sistema requereix mòduls del nucli que no estan inclosos en la initramfs per defecte, com controladors de xarxa, controladors d'emmagatzematge, o sistemes de fitxers específics (per exemple, Btrfs o ZFS), serà necessari modificar la initramfs per incloure aquests mòduls.
-
Configuració de dispositius d'emmagatzematge complexos: Si el sistema utilitza configuracions d'emmagatzematge complexes, com RAID o LVM, pot ser necessari incloure scripts i binaris addicionals en la initramfs per assegurar que aquests dispositius siguin correctament inicialitzats i muntats.
-
Configuració de xarxa: En alguns casos, pot ser necessari incloure scripts de configuració de xarxa en la initramfs per assegurar que el sistema tingui accés a la xarxa durant el procés d'arrencada. Això pot ser útil en entorns on la xarxa és essencial per l'arrencada del sistema.
-
Solucionar problemes d'arrencada: Si el sistema experimenta problemes d'arrencada, modificar la initramfs pot ser una solució per incloure scripts de diagnòstic o correccions temporals que permetin al sistema arrencar correctament.
En aquest laboratori, explorarem com podem examinar i modificar la initramfs en un sistema Linux basat en Debian. Per a més informació sobre la initramfs, podeu consultar la documentació oficial de Debian a Debian Wiki - Initramfs.
Objectius
- Entendre què és la initramfs i com funciona.
- Aprendre a examinar el contingut de la initramfs.
- Aprendre a modificar la initramfs per incloure mòduls del nucli addicionals.
Preparació
-
Entorn de treball: Màquina virtual amb una distribució GNU/Linux instal·lada pot ser Debian o AlmaLinux. La màquina virtual pot tenir una configuració per defecte. Característiques de la màquina virtual:
- Disc dur virtual de 20 GB.
- 1 CPU.
- 1 GB de memòria RAM.
A més, inicialitzeu com a mínim un usuari root amb contrasenya (pot ser 1234).
En el meu cas he utilitzat una màquina virtual amb la imatge de Debian 12 proporcionada al inici de curs al campus virtual.
Tasques
- Examinar el contingut de la initramfs
- Carregar un mòdul del nucli addicional a la initramfs
- Personalitzar la initramfs
Examinant la initramfs
-
Inicia la màquina virtual: Inicia la màquina virtual i inicia sessió amb l'usuari root.
-
Examina el contingut de la initramfs: Utilitza la comanda
lsinitramfsper examinar el contingut de la initramfs. Aquesta comanda mostrarà el contingut de la initramfs i els scripts i binaris que s'executen durant el procés d'arrencada.lsinitramfs /boot/initrd.img-$(uname -r)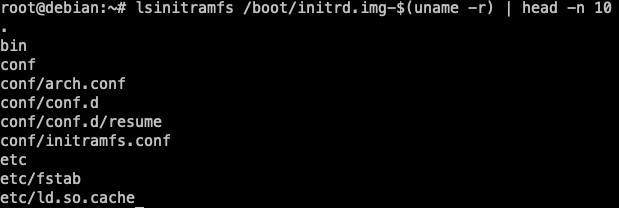
En la figura anterior, he limitat la sortida amb la comanda
headper mostrar només les 10 primeres línies de la sortida. La sortida completa mostrarà tot el contingut de la initramfs.Si analitzeu la sortida completa al vostre servidor, podreu veure que la initramfs conté diversos scripts i binaris que s'utilitzen durant el procés d'arrencada. Aquests scripts i binaris són responsables de realitzar tasques com muntar dispositius de bloc, carregar mòduls del nucli, i configurar la xarxa.
💡 Nota: La sortida de la comanda
lsinitramfspot ser molt extensa, ja que la initramfs conté molts scripts i binaris necessaris per l'arrencada del sistema. Si voleu veure la sortida completa, podeu redirigir-la a un fitxer o utilitzar la comandalessper navegar-hi. -
Cerca si el modul
ext4està present a la initramfs:lsinitramfs /boot/initrd.img-$(uname -r) | grep ext4En aquest cas, hauria de veure que el mòdul
ext4està present a la initramfs. Aquest mòdul és necessari per muntar sistemes de fitxers ext4 durant el procés d'arrencada.
Carregant un mòdul addicional
-
Carrega el mòdul del nucli: En aquest pas, carregarem un mòdul del nucli addicional a la initramfs actual. En aquest cas, carregarem el mòdul
nls_utf8, que és un mòdul de suport per a la codificació de caràcters UTF-8. El primer pas és comprovar si el mòdul ja està carregat:lsmod | grep nls_utf8Si la comanda no retorna cap sortida, significa que el mòdul
nls_utf8no està carregat actualment al sistema. -
Comprovar si el modul esta carregat a la initramfs: Abans de carregar el mòdul a la initramfs, comprovem si ja està present:
lsinitramfs /boot/initrd.img-$(uname -r) | grep nls_utf8Si la comanda no retorna cap sortida, significa que el mòdul
nls_utf8no està present a la initramfs actual. -
Cerca la ubicació del mòdul del nucli: Utilitza la comanda
modinfoper cercar la ubicació del mòdulnls_utf8.modinfo nls_utf8Aquesta comanda mostrarà informació detallada sobre el mòdul
nls_utf8, incloent la ubicació del fitxer del mòdul. En aquest cas, el fitxer del mòdul es troba a/lib/modules/$(uname -r)/kernel/fs/nls/nls_utf8.ko. -
Carrega el mòdul a la initramfs: Utilitza la comanda
echoper afegir el mòdulnls_utf8a la llista de mòduls que s'inclouran a la initramfs durant el procés de generació.echo nls_utf8 >> /etc/initramfs-tools/modules -
Regenera la initramfs: Utilitza la comanda
update-initramfsper regenerar la initramfs amb el mòdulnls_utf8inclòs.update-initramfs -uAquesta comanda regenerarà la initramfs amb el mòdul
nls_utf8inclòs. Si tot ha anat bé, no hauria de veure cap error durant el procés de generació. -
Reinicia el sistema: Reinicia el sistema per aplicar els canvis.
reboot -
Comprova si el mòdul s'ha carregat: Després de reiniciar el sistema, comprova si el mòdul
nls_utf8s'ha carregat correctament.lsmod | grep nls_utf8 lsinitramfs /boot/initrd.img-$(uname -r) | grep nls_utf8Si la comanda
lsmodretorna el mòdulnls_utf8, significa que el mòdul s'ha carregat correctament al sistema. Si la comandalsinitramfsretorna el mòdulnls_utf8, significa que el mòdul s'ha inclòs correctament a la initramfs.
Personalitzar la initramfs
En aquesta secció, personalitzarem la initramfs afegint un missatge personalitzat que es mostrarà durant el procés d'inici. Això ens permetrà veure com podem modificar la initramfs per incloure scripts i binaris addicionals que es poden executar durant l'arrencada del sistema.
Nota:
Realitzeu les accions següents com a superusuari
su -.
-
Crea un nou directori per construir la initramfs personalitzada:
mkdir /tmp/initramfs cd /tmp/initramfsAixò crea un espai de treball temporal on es construirà la nova imatge de la initramfs.
-
Extreu la imatge actual de la initramfs:
unmkinitramfs /boot/initrd.img-$(uname -r) .ℹ️ Nota:
unmkinitramfsés una eina que permet descomprimir la imatge de la initramfs a un directori de treball. Això permet modificar els fitxers continguts en la initramfs.
Compte!: Es possible que al descomprimir la imatge us generi dos carpetes
mainistable. En aquest cas, heu de treballar amb la carpetamain. Cerqueu dins demainla carpetascriptsi dins d'aquesta la carpetainit-top. Aquesta és la carpeta on s'executen els scripts durant l'arrencada de la initramfs. -
Crea un nou fitxer de script amb un missatge personalitzat:
echo 'echo "Hola, Initramfs!"' > scripts/init-top/custom_message.sh # Afegeix una pausa per veure el missatge echo '/usr/bin/sleep 10' >> scripts/init-top/custom_message.sh # Atorga permisos d'execució al script chmod +x scripts/init-top/custom_message.sh -
Actualitza el manifest de la initramfs:
# Nota: order no existeix, és ORDER amb majúscules echo 'scripts/init-top/custom_message.sh' >> scripts/init-top/ORDERAixò afegeix el nou script al manifest de la initramfs, assegurant-se que s'executi durant el procés d'inici.
-
Crea una nova imatge de la initramfs amb el script personalitzat:
Realitzeu una de les següents opcions:
- Nova imatge de la initramfs (nom acaba en custom):
find . | cpio -o -H newc | gzip > /boot/initrd.img-$(uname -r)-custom- Sobreescriure la imatge original:
find . | cpio -o -H newc | gzip > /boot/initrd.img-$(uname -r)ℹ️ Nota:
Aquest pas utilitza
cpioper empaquetar tots els fitxers del directori de treball en un sol arxiu, igzipper comprimir-lo. La nova imatge es guarda a/bootamb un nom personalitzat. Si voleu sobreescriure la imatge original, podeu utilitzar el nominitrd.img-$(uname -r). Si feu anar custom, al grub també cal indicar-ho. -
Actualitza la configuració de GRUB per utilitzar la nova imatge de la initramfs:
Com editarem la initramfs de forma temporal, no actualitzarem la configuració de GRUB de forma permanent. Per tant, no ens calen aquests passos.
update-initramfs -u -k $(uname -r) update-grubℹ️ Nota:
Per fer l'experiment no actualizarem el grub de forma permanent. Simplement, editarem la configuració de GRUB durant l'arrencada per utilitzar la nova imatge de la initramfs.
-
Reinicia el sistema: Reinicia el sistema per aplicar els canvis.
reboot -
GRUB: A l'arrencada, accedeix a la configuració de GRUB i modifica la línia de comandament per utilitzar la nova imatge de la initramfs. Recorda prement la tecla
eper editar la configuració de GRUB.# Elimina les opcions `quiet` i `splash` per veure el missatge personalitzat # Afegeix custom al final de la línia de comandament de la initramfs initrd /boot/initrd.img-$(uname -r)-custom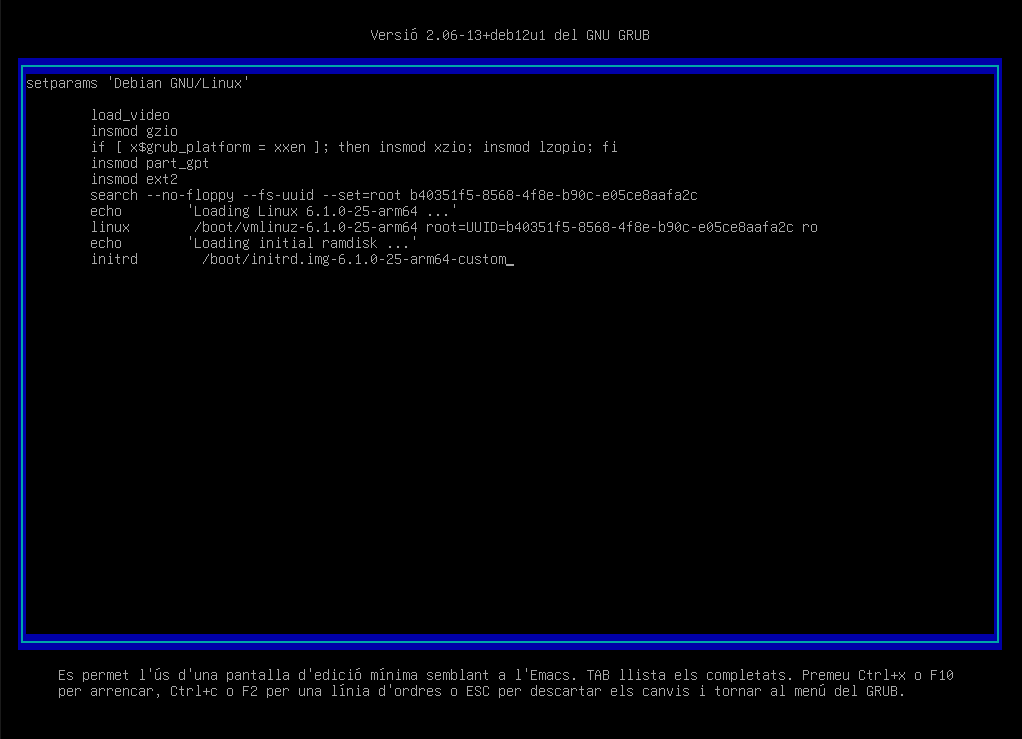
-
Comprova el missatge personalitzat durant l'arrencada: Després de reiniciar el sistema, observa el missatge personalitzat que s'ha afegit a la initramfs durant el procés d'inici.
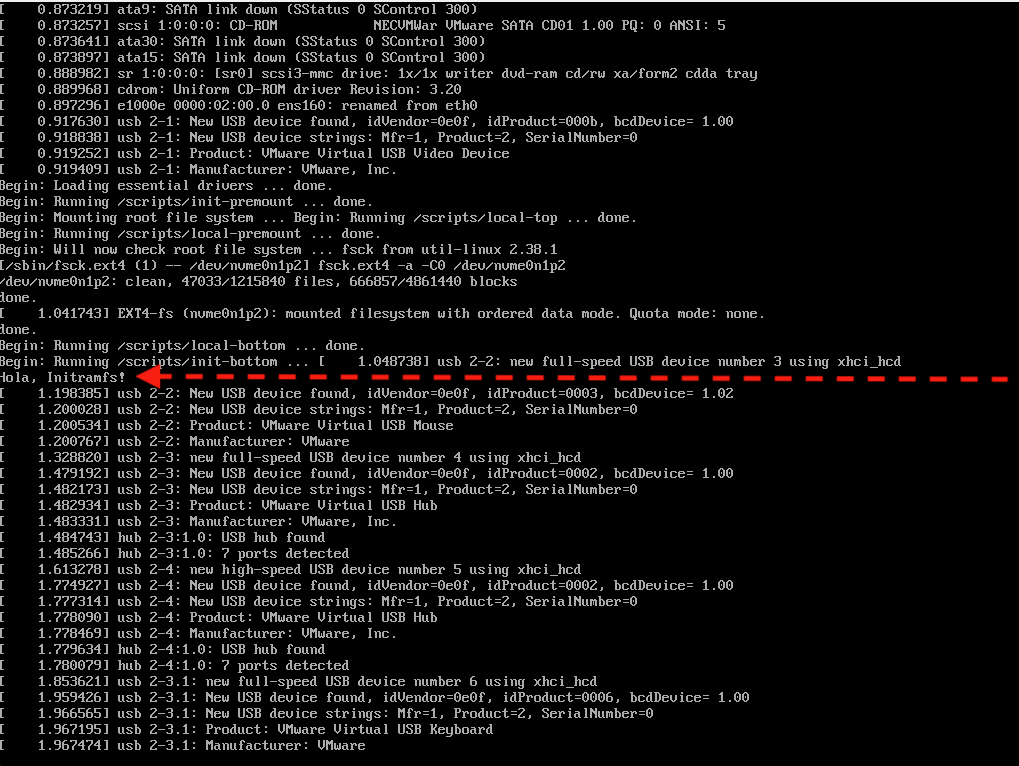
Activitat opcional
- Quin seria el procediment si volem modificar de forma permanent la initramfs de la primera entrada de GRUB? Documenteu el procediment. Aquesta activitat comptarà únicament a la primera persona que faci un PR amb la resposta correcta. No compte a HandsOn, això es part de la millora dels continguts (un dels punts extres de la nota final).
Inici del sistema i Dimonis de gestió de serveis
Un cop el kernel ha estat carregat i ha completat el seu procés d’inicialització, crea un conjunt de processos espontanis en l’espai d’usuari. El primer d'aquests processos és el procés init, que és el pare de tots els altres processos en el sistema. El procés init és responsable de la inicialització del sistema i de la gestió de la resta de serveis. Tradicionalment, el procés init era conegut com a SysVinit, però amb el temps han sorgit alternatives com systemd.
🧐 El canvi de SysVinit a Systemd...
En moltes distribucions Linux es va fer per millorar l’eficiència i la gestió dels serveis del sistema. SysVinit utilitza scripts seqüencials per iniciar serveis, cosa que pot ser lenta i menys flexible. En canvi, Systemd permet una arrencada paral·lela, reduint significativament el temps d’inici del sistema. A més, Systemd ofereix una gestió més avançada dels processos amb funcionalitats com els cgroups, que permeten controlar els recursos utilitzats per cada servei. Ara bé, aquest canvi també ha generat controvèrsia, ja que molts usuaris prefereixen el sistema més senzill i transparent de SysVinit.
En aquest laboratori, explorarem el procés d'arrencada del sistema amb systemd i com crear i gestionar serveis amb aquesta eina. També veurem com utilitzar journalctl per analitzar els registres del sistema i com personalitzar el procés d'arrencada amb scripts i serveis personalitzats.
Objectius
- Comprendre el procés d'arrencada del sistema amb systemd.
- Crear i gestionar serveis amb systemd.
- Utilitzar journalctl per analitzar els registres del sistema.
- Personalitzar el procés d'arrencada amb scripts i serveis personalitzats.
Preparació de l'entorn
Per a aquest laboratori, necessitarem un sistema Linux amb systemd instal·lat. Aquest laboratori es pot realitzar en qualsevol distribució Linux moderna que utilitzi systemd com a gestor d'inicialització. En aquest laboratori, utilitzarem una màquina virtual amb Debian 12. A més, assegureu-vos de no instal·lar la interfície gràfica, i seleccionar el servidor SSH durant la instal·lació.
Tasques
- Analitzar el procés d'arrencada amb systemd
- Crear i gestionar serveis amb systemd
- Execució de serveis programats amb systemd
- Anàlisi de registres del sistema amb journalctl
- Afegir informació d'inici al sistema
Analitzant el procés d'arrancada
La comanda systemd ens permet gestionar els serveis del sistema i controlar el procés d'arrencada. Podeu comprovar les seves possibilitats amb la comanda man systemd. Una de les funcionalitats més útils de systemd és la capacitat de generar informació detallada sobre el procés d'arrencada del sistema.
El primer pas per analitzar el procés d'arrencada amb systemd és utilitzar la comanda systemd-analyze per obtenir informació sobre el temps que ha trigat el sistema a arrencar. Aquesta comanda mostrarà informació sobre el temps que ha trigat el sistema a arrencar, incloent el temps que ha trigat el kernel i l'espai d'usuari.
Startup finished in 899ms (kernel) + 2.074s (userspace) = 2.973s
graphical.target reached after 2.068s in userspace.
| Kernel | Espai d'usuari | Total |
|---|---|---|
| 899ms | 2.074s | 2.973s |
En aquest cas, els primers 899ms s'utilitzen per carregar les funcions del kernel com ara els controladors de dispositius i el sistema de fitxers. Els següents 2.074s s'utilitzen per carregar l'espai d'usuari, com ara els serveis i els processos del sistema. En total, el sistema ha trigat 2.973s a arrencar.
Ara que tenim aquesta informació, podem utilitzar la comanda systemd-analyze blame per obtenir informació detallada sobre el temps que ha trigat cada unitat a carregar durant el procés d'arrencada. Aquesta opció ens llistarà les unitats ordenades per temps d'arrencada, de major a menor.
| Temps | Unitat |
|---|---|
| 1.876s | systemd-random-seed.service |
| 784ms | dbus.service |
| 782ms | e2scrub_reap.service |
| 778ms | systemd-logind.service |
| ... | ... |
| 4ms | systemd-update-utmp-runlevel.service |
Amb aquesta informació, podem identificar les unitats que poden estar retardant el procés d'arrencada i optimitzar-les si cal. Per obtenir més informació sobre una unitat específica, podeu utilitzar la comanda systemctl status seguida del nom de la unitat. Per exemple, si volem informació sobre la unitat systemd-random-seed.service, podem executar:
systemctl status systemd-random-seed.service

Aquesta informació ens mostrarà:
- L'estat actual de la unitat (inactiu, actiu, desactivat, error o recarregant).
- La linia Loaded ens indica la ruta al fitxer on es desa la configuració de la unitat. En aquest cas,
/lib/systemd/system/systemd-random-seed.service. A més ens indica static que vol dir que la unitat no es pot desactivar. Altres unitats ens poden indicar error, masked, not-found, enable o disabled - La entrada al manual de la unitat, si n'hi ha.
- Finalment, ens mostra informació sobre el procés: PID, estat del procés i temps que ha estat en execució (això en el exemple) també pot mostrar la memòria, el cgroup, o el nombre de tasques associades.
Si volem saber exactament què fa aquest servei, podem consultar el manual amb la comanda man systemd-random-seed.service.

En el manual d'aquesta comanda us explicarà de forma detallada què aquest servei carrega una llavor aleatòria al espai del nucli quan arranca i la desa quan s'apaga. Aquesta llavor es guarda a /var/lib/systemd/random-seed. Per defecte, no s’assigna entropia quan s’escriu la llavor al nucli, però això es pot canviar amb $SYSTEMD_RANDOM_SEED_CREDIT. El servei s’executa després de muntar el sistema de fitxers /var/, per la qual cosa és recomanable utilitzar un carregador d’arrencada que passi una llavor inicial al nucli, com systemd-boot.
👁️ Observació:
Amb aquesta informació podem identificar quina és la funció de cada servei i decidir si pel nostre sistema és necessari o no. En aquest cas, el servei
systemd-random-seed.serviceés necessari per a la generació de nombres aleatoris, per tant, no és recomanable desactivar-lo.
Si volem informació sobre la unitat systemd-random-seed.service, podem utilitzar la comanda systemctl cat systemd-random-seed.service per veure la configuració de la unitat.
# /lib/systemd/system/systemd-random-seed.service
# SPDX-License-Identifier: LGPL-2.1-or-later
#
# This file is part of systemd.
#
# systemd is free software; you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published by
# the Free Software Foundation; either version 2.1 of the License, or
# (at your option) any later version.
[Unit]
Description=Load/Save Random Seed
Documentation=man:systemd-random-seed.service(8) man:random(4)
DefaultDependencies=no
RequiresMountsFor=/var/lib/systemd/random-seed
Conflicts=shutdown.target
After=systemd-remount-fs.service
Before=first-boot-complete.target shutdown.target
Wants=first-boot-complete.target
ConditionVirtualization=!container
ConditionPathExists=!/etc/initrd-release
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStart=/lib/systemd/systemd-random-seed load
ExecStop=/lib/systemd/systemd-random-seed save
# This service waits until the kernel's entropy pool is initialized, and may be
# used as ordering barrier for service that require an initialized entropy
# pool. Since initialization can take a while on entropy-starved systems, let's
# increase the timeout substantially here.
TimeoutSec=10min
Aquesta informació ens mostra la configuració de la unitat, incloent la descripció, la documentació, les dependències, les condicions, el tipus de servei, els comandaments d'inici i parada, i altres opcions de configuració. El servei té una dependència de muntatge per a /var/lib/systemd/random-seed, i s'executa després de systemd-remount-fs.service i abans de first-boot-complete.target i shutdown.target. A més, ens indica que és un servei de tipus oneshot, que s'executa una sola vegada i roman actiu després de la sortida. Els comandaments d'inici i parada són /lib/systemd/systemd-random-seed load i /lib/systemd/systemd-random-seed save, respectivament.
💡 Nota::
Si ovserveu el paramètre TimeoutSec=10min aquesta unitat pot trigar fins a 10 minuts a carregar. Si el sistema està en un entorn amb poca entropia, aquesta unitat pot trigar més temps a carregar.
Per exemple, editarem la unitat systemd-random-seed.service per activar la entropia al sistema.Per editar la unitat podeu utilitzar qualsevol editor de text ( i.e vi) o bé la comanda systemctl edit systemd-random-seed.service que obrirà un editor de text per afegir la línia. Un cop obert l'editor heu d'afegir la lína a la secció [Service] i desar el fitxer. Recordeu que per fer aquesta acció necessitareu permisos d'administrador. Per tant, su - per canviar a l'usuari root i després fer la comanda.
Environment=SYSTEMD_RANDOM_SEED_CREDIT=4096
Compte! Si feu anar el
systemctl editaquest crearà un fitxer de configuració a/etc/systemd/system/systemd-random-seed.service.d/override.confque sobreescriurà la configuració de la unitat original. Per afegir la configuració còpieu la configuració original i afegiu la líniaEnvironment=SYSTEMD_RANDOM_SEED_CREDIT=4096a la secció[Service].
Estem assignant un crèdit de 4096 a la llavor aleatòria. Això augmentarà la quantitat d'entropia que es passa al nucli quan s'escriu la llavor. Un crèdit més alt pot augmentar la seguretat del sistema, però també pot augmentar el temps d'arrencada en sistemes amb poca entropia.
Un cop hàgim fet els canvis, guardarem el fitxer i sortirem de l'editor. Després, podem fer un reboot per aplicar els canvis. Quan el sistema s'hagi reiniciat, podem tornar a utilitzar la comanda systemd-analyze per comprovar si els canvis han tingut algun impacte en el temps d'arrencada del sistema.
| Inicial | Després de canviar la entropia | Diferència |
|---|---|---|
| 2.973s | 3.008s | +0.035s |
En el meu cas, el temps d'arrencada ha augmentat lleugerament després de fer aquest canvi. Això és normal, ja que hem augmentat la quantitat d'entropia que es passa al nucli.
Una altra opció interesant que ens ofereix systemd és la comanda systemd-analyze critical-chain. Aquesta comanda ens permet veure la cadena crítica de les unitats de temps del sistema. Això ens mostra quines unitats són les més crítiques per al temps d'arrencada del sistema. Per analizar la sortida, heu de mirar el temps després del caràcter @ per veure quant temps ha trigat la unitat a activar-se o iniciar-se, i el temps després del caràcter + per veure quant temps ha trigat la unitat a iniciar-se. A més, aquesta comanda només mostra el temps que les unitats han passat a l'estat activant-se, i no cobreix les unitats que mai han passat per l'estat activant-se (com les unitats de dispositius que passen directament de inactiu a actiu). Tot i això, és una eina útil per identificar les unitats que poden estar retardant el procés d'arrencada.
graphical.target @2.076s
└─multi-user.target @2.075s
└─ssh.service @1.497s +578ms
└─network.target @1.494s
└─networking.service @1.225s +268ms
└─apparmor.service @1.158s +63ms
└─local-fs.target @1.158s
└─run-credentials-systemd\x2dtmpfiles\x2dsetup.service.mount @1.171s
└─local-fs-pre.target @242ms
└─systemd-tmpfiles-setup-dev.service @224ms +17ms
└─systemd-sysusers.service @192ms +20ms
└─systemd-remount-fs.service @131ms +54ms
└─systemd-journald.socket @114ms
└─-.mount @86ms
└─-.slice @86ms
En aquest cas, podem veure que la unitat ssh.service és la més crítica per al temps d'arrencada del sistema, ja que ha trigat 578ms a iniciar-se. A més, podem veure les dependències de totes les unitats que s'han carregat durant el procés d'arrencada. Començant pel graphical.target i seguint per les unitats multi-user.target, aquestes dos unitats ens asseguren que el sistema ha arrencat en mode gràfic i multiusuari. A partir d'aquest moment es carreguen la resta de serveis.
Un altra opció interessant és utilitzar la comanda systemd-analyze plot per generar un gràfic del procés d'arrencada del sistema. Aquesta comanda generarà un fitxer SVG amb el gràfic del procés d'arrencada, que podeu visualitzar amb un navegador web o un visor d'imatges.
-
Si volem analitzar tots les unitats:
systemd-analyze plot > boot_system.svg -
Si volem analitzar les unitats de la instancia de l'usuari:
systemd-analyze --user plot > boot_user.svg -
Si volem les unitats de l'arrencada del sistema:
systemd-analyze --system plot > boot_system.svg
⚠️ Compte: Com puc visualtizar una imatge SVG en un debian sense interfície gràfica?
Per visualitzar una imatge SVG en un sistema sense interfície gràfica, podeu descarregar el fitxer SVG a la vostra màquina local i visualitzar-lo amb un visor d'imatges o un navegador web. Per exemple, podeu utilitzar la comanda
scpper descarregar el fitxer SVG a la vostra màquina local:scp user@remote:/path/to/boot.svg /path/to/local/boot.svg
⚠️ Compte: Debian no permet conexions remotes com a root per defecte. Abans de fer-ho, com debian per defecte no permet l'execució de
scpcom a root, caldrà fer-ho com a usuari normal i després copiar el fitxer a la carpeta desitjada.mv boot.svg /tmp chown user:user /tmp/boot.svg

Per a més informació sobre les opcions de la comanda systemd-analyze, podeu consultar el manual amb la comanda man systemd-analyze.
Per acabar, podem comentar que així com systemctl status unitat ens mostra la informació d'una unitat. També podem consultar la informació de totes les unitats amb:
systemctl status: Mostra informació sobre l'estat actual del sistema o d'una unitat específica acompanyada de les dades més recents del registre del diari.
systemctl list-units: Mostra una llista de totes les unitats carregades al sistema, incloent les unitats actives, inactives i fallades.

Totes aquestes comandes són molt complexes i tenen moltes opcions, per tant us recomano que consulteu el manual de cada comanda per obtenir més informació sobre com utilitzar-les i quines opcions podeu elegir.
Creant i Gestionant serveis
En aquesta secció, crearem un servei systemd per realitzar una còpia de seguretat del sistema a l'arrencada. Aquest servei s'executarà automàticament quan el sistema s'arrenqui i realitzarà una còpia de seguretat del sistema a una ubicació específica. Aquest servei pot ser interessant en situacions on l'ús pot comportar la pèrdua de dades o la corrupció del sistema.
-
Crea un script de còpia de seguretat: Crea un script de còpia de seguretat a
/usr/local/bin/backup.sh amb el següent contingut:#!/bin/bash # Còpia de seguretat del sistema tar -czf /backup/system_backup_$(date +%Y%m%d).tar.gz /etc /varAquest script realitzarà una còpia de seguretat dels directoris
/etci/vara la ubicació/backupamb el nomsystem_backup_YYYYMMDD.tar.gz, onYYYYMMDDés la data actual. -
Crea un fitxer de servei systemd: Crea un fitxer de servei systemd a
/etc/systemd/system/backup.serviceamb el següent contingut:[Unit] Description=System Backup Service After=network.target [Service] Type=oneshot ExecStart=/usr/local/bin/backup.sh [Install] WantedBy=multi-user.targetAquest fitxer de servei defineix un servei
backupque s'executarà un cop s'hagi carregat el sistema de fitxers. El servei executarà l'script de còpia de seguretatbackup.shal directori/usr/local/bin. El servei s'instal·larà a la unitatmulti-user.target, de manera que s'executarà quan el sistema hagi carregat tots els serveis necessaris. -
Inicia el servei: Inicia el servei
backupamb la comandasystemctl start backup.systemctl start backup -
Comprova l'estat del servei: Comprova l'estat del servei
backupamb la comandasystemctl status backup.systemctl status backup -
Habilita el servei: Habilita el servei
backupperquè s'executi a l'arrencada amb la comandasystemctl enable backup.systemctl enable backup -
Reinicia el sistema: Reinicia el sistema per aplicar els canvis.
reboot -
Comprova si el servei s'ha executat: Després de reiniciar el sistema, comprova si el servei
backups'ha executat correctament.ls /backup
Ara el sistema arranca de forma més lenta ja que s'executa el servei de còpia de seguretat. Podeu utilitzat les comandes systemd-analyze i systemd-analyze blame per comparar els temps d'arrencada abans i després de la creació del servei.
En el meu cas, el temps d'arrencada ha augmentat lleugerament després de crear el servei de còpia de seguretat:
| Inicial | Després de crear el servei | Diferència |
|---|---|---|
| 2.973s | 10.380s | +7.407s |
👁️ Observació:
Noteu que l'augment es produeix en l'espai d'usuari, ja que el servei de còpia de seguretat s'executa després de carregar les funcions del kernel. Això és normal, ja que el servei de còpia de seguretat pot trigar una estona a completar-se, especialment si els directoris
/etci/varsón grans.
Serveis programats
Un altra funcionalitat interessant de systemd és la possibilitat de programar la execució de serveis amb systemd.timer. Aquesta funcionalitat permet programar la execució de serveis en un moment concret o de forma periòdica. Això pot ser útil per realitzar tasques de manteniment automàticament, com ara còpies de seguretat, actualitzacions de sistema, etc.
Anem a veure com podem programar l'actualització del sistema amb un servei apt-update i un temporitzador apt-update.timer cada dia a les 00:00.
-
Crea un fitxer de servei
apt-update.service: Crea un fitxer de serveiapt-update.servicea/etc/systemd/system/apt-update.serviceamb el següent contingut:[Unit] Description=Update the package list [Service] Type=oneshot ExecStart=/usr/bin/apt updateAquest fitxer de servei executa la comanda
apt updateper actualitzar la llista de paquets del sistema. -
Crea un fitxer de temporitzador
apt-update.timer: Crea un fitxer de temporitzadorapt-update.timera/etc/systemd/system/apt-update.timeramb el següent contingut:[Unit] Description=Run apt-update daily at 00:00 [Timer] OnCalendar=daily [Install] WantedBy=timers.targetAquest fitxer de temporitzador programa l'execució del servei
apt-update.servicecada dia a les 00:00. -
Inicia el temporitzador: Inicia el temporitzador
apt-update.timeramb la comandasystemctl start apt-update.timer.systemctl start apt-update.timer -
Habilita el temporitzador: Habilita el temporitzador
apt-update.timerperquè s'executi a l'arrencada amb la comandasystemctl enable apt-update.timer.systemctl enable apt-update.timer💡 Nota:
Podeu utilitzar
systemctl enable --now unitatper iniciar i habilitar una unitat al mateix temps. -
Comprova l'estat del temporitzador: Comprova l'estat del temporitzador
apt-update.timeramb la comandasystemctl status apt-update.timer.
Una vegada configurat el temporitzador, el sistema executarà el servei apt-update.service cada dia a les 00:00 per actualitzar la llista de paquets del sistema.

Anàlisi de logs
Un altre eina útil que ens ofereix systemd és journalctl, que ens permet analitzar els registres del sistema. Aquesta eina ens permet veure els registres del sistema en temps real, buscar registres específics, filtrar registres per unitat, i molt més.
Crearem un servei amb bash i awk que monitoritzi l'estat del sistema i registri la informació en un fitxer de registre. A continuació, utilitzarem journalctl per analitzar els registres del sistema i buscar la informació del servei.
-
Crea un script de monitoratge:
#!/bin/bash # Monitor the system state echo "Date: $(date)" echo "Load: $(uptime | awk '{print $10}')" echo "Memory: $(free -m | awk 'NR==2{print $3}')" echo "Disk: $(df -h / | awk 'NR==2{print $5}')" echo "Processes: $(ps aux | wc -l)" -
Crea un fitxer de servei
system-monitor.service: En aquest cas, crearem un fitxer de serveisystem-monitor.servicea/etc/systemd/system/system-monitor.serviceamb el següent contingut:[Unit] Description=System Monitor Service [Service] Type=simple ExecStart=/usr/local/bin/system-monitor.sh [Install] WantedBy=multi-user.target -
Inicia el servei: Inicia el servei
system-monitoramb la comandasystemctl start system-monitor.systemctl start system-monitor -
Comprova l'estat del servei: Comprova l'estat del servei
system-monitoramb la comandasystemctl status system-monitor.systemctl status system-monitor
Ups! Sembla que hi ha un error en el servei. Podem veure que el servei ha fallat a l'iniciar-se. La mateixa comanda ens indica la causa de l'error:
Permission denied. Això significa que el script no té permisos d'execució. Per solucionar aquest problema, podem canviar els permisos del script perquè sigui executable amb la comandachmod +x /usr/local/bin/system-monitor.sh.systemctl restart system-monitor
-
Un altra forma d'accedir a la informació del servei és utilitzar la comanda
journalctlamb l'opció-useguida del nom de la unitat. Per exemple, per veure els registres del serveisystem-monitor, podem utilitzar la comanda:journalctl -u system-monitorAquesta comanda ens mostrarà tots els registres associats amb el servei
system-monitor, incloent els missatges de registre, les entrades de diari i altres informacions rellevants.👁️ Observació:
Tot i que
journalctlsembla que ens mostra la mateixa informació quesystemctl status,journalctlens permet accedir a tots els registres del sistema, no només als registres de les unitats. Això ens permet analitzar els registres del sistema de forma més detallada i buscar informació específica. A més, no sempre podem veure tota la informació d'una unitat ambsystemctl status, ja que aquesta comanda només ens mostra les dades més recents del registre del diari.
💡 Nota:
journalctlés una eina molt potent que ens permet analitzar els registres del sistema de forma detallada. Podeu utilitzar opcions com-fper veure els registres en temps real,-nper limitar el nombre de línies mostrades,-rper mostrar els registres en ordre invers,-pper filtrar els registres per prioritat, i moltes altres opcions. Podeu consultar el manual dejournalctlamb la comandaman journalctlper obtenir més informació sobre com utilitzar aquesta eina. Durant les vostres sessions administrant el sistema,journalctlserà una eina molt útil per analitzar els registres del sistema i poder identificar problemes o errors.
Afegint informació d'inici
Els scripts d'arrancada en sistemes Unix i Linux són fitxers que s'executen automàticament quan un usuari inicia una sessió de terminal. Aquests scripts configuren l'entorn de l'usuari, definint variables d'entorn, carregant funcions i configuracions personalitzades, i executant comandes específiques.
Breument, tal com vam veure al curs de sistemes operatius, els scripts d'arrancada més comuns en sistemes Unix i Linux són:
/etc/profile: Script d'arrancada global per a tots els usuaris del sistema./etc/profile.d/: Directori que conté scripts d'arrancada addicionals.~/.bash_profile: Script d'arrancada específic de l'usuari per a la shell bash.~/.bash_login: Un altre script d'arrancada específic de l'usuari per a la shell bash.~/.profile: Script d'arrancada específic de l'usuari per a la shell sh i altres shells compatibles.~/.bashrc: Script d'arrancada específic de l'usuari per a la shell bash./root/.profile: Script d'arrancada específic de l'usuari root per a la shell sh i altres shells compatibles.
Aquests scripts s'executen en un ordre específic quan un usuari inicia una sessió de terminal. A continuació, veurem una descripció de cada script d'arrancada i el seu ús, així com l'ordre d'execució dels scripts d'arrancada. Per veure l'ordre d'execució dels scripts d'arrancada, podeu consultar el manual de bash amb la comanda man bash i buscar la secció INVOCATION.
Anem a veure com podem mostrar informació sobre el servidor després de l'arrencada i el login de l'usuari. Aquesta informació pot ser útil per als administradors de sistemes per mostrar informació rellevant sobre el sistema, com ara la càrrega del sistema, l'ús de la CPU, la memòria disponible, la addresa IP i el nombre d'usuaris connectats.
-
Crea un script d'informació del sistema: Crea un script d'informació del sistema a
/usr/local/bin/system-info.shamb el següent contingut:#!/bin/bash # Informació del sistema echo "System Information" echo "------------------" echo "Hostname: $(hostname)" echo "IP Address: $(hostname -I | awk '{print $1}')" echo "Uptime: $(uptime | awk '{print $3 " " $4}')" echo "Load Average: $(uptime | awk '{print $10 " " $11 " " $12}')" echo "Memory Usage: $(free -h | grep Mem | awk '{print $3 "/" $2}')" echo "Disk Usage: $(df -h / | grep /dev | awk '{print $3 "/" $2}')" echo "Users: $(who | wc -l)"Aquest script mostra informació rellevant sobre el sistema, com ara el nom de l'amfitrió, la addresa IP, el temps d'activitat, la càrrega del sistema, l'ús de la memòria, l'ús del disc i el nombre d'usuaris connectats.
-
Atorga permisos d'execució al script:
chmod +x /usr/local/bin/system-info.sh -
Crea un script d'informació del sistema: Crea un script d'informació del sistema a
/etc/profile.d/system-info.shamb el següent contingut:# Informació del sistema /usr/local/bin/system-info.shSi posem l'script a
/etc/profile.d/aquest s'executarà automàticament quan un usuari inicia una sessió de terminal. Això permet mostrar informació rellevant sobre el sistema després de l'arrencada i el login de l'usuari. -
Atorga permisos d'execució al script:
chmod +x /etc/profile.d/system-info.sh -
Reinicia el sistema: Reinicia el sistema per aplicar els canvis.
reboot
Un cop el sistema s'hagi reiniciat, podeu iniciar una sessió de terminal i veure la informació del sistema després de l'arrencada i el login de l'usuari. Aquesta informació us pot ajudar a monitoritzar l'estat del sistema i identificar problemes o errors.
-
Inici de sessió amb un usuari normal:
-
Inici de sessió com a usuari root:
Si únicament voleu mostrar la informació del sistema quan s'inicia la sessió de l'usuari root, podeu afegir el script system-info.sh al fitxer /root/.profile en lloc de /etc/profile.d/system-info.sh. Això farà que la informació del sistema es mostri només quan s'inicia la sessió de l'usuari root.
ℹ️ Diferencia entre .bashrc i .bash_profile?
El fitxer
.bashrcs'executa cada vegada que s'inicia una sessió de terminal, mentre que el fitxer.bash_profiles'executa només quan s'inicia una sessió de terminal interactiva. Això significa que el fitxer.bashrcs'executarà cada vegada que s'obri una nova finestra de terminal, mentre que el fitxer.bash_profiles'executarà només quan s'inicia una sessió de terminal interactiva. Per tant, si voleu mostrar la informació del sistema només quan s'inicia la sessió de l'usuari, podeu afegir el script al fitxer.bash_profileen lloc de.bashrc.
Sistema de Fitxers
En aquest laboratori apendrem a gestionar els sistemes de fitxers tradicionals en un servidor Linux; com ext4, i xfs. A més, aprendrem a realitzar tasques comunes com la creació de particions, el muntatge de sistemes de fitxers, la comprovació de la integritat dels fitxers, la realització de còpies de seguretat i la recuperació de dades en cas de corrupció. També analitzarem sistemes de fitxers temporals i un sistema de fitxers avançat com ZFS.
Objectius
Els objectius d'aquest laboratori són:
- Comprendre els conceptes bàsics dels sistemes de fitxers.
- Crear i gestionar particions en un servidor Linux.
- Muntar i desmuntar sistemes de fitxers.
- Comprovar la integritat dels fitxers en un sistema de fitxers.
Tasques
- Muntatge d'un disc extern per fer un backup
- Migració de dades a altres particions
- Simulació d'una corrupció a la partició
/homei recuperació - Sistemes de fitxers temporals
- Explorant un sistema de fitxers avançat:
zfs
Muntatge d'un disc extern per fer un backup
En aquest laboratori simularem que volem muntar un disc dur extern en el nostre servidor per a realitzar còpies de seguretat de les nostres dades. Crearem una partició en el disc dur i la formatejarem amb el sistema de fitxers ext4.
-
Connecta el disc dur extern a la màquina virtual.
-
Utilitza la comanda
lsblkper a identificar el disc dur extern.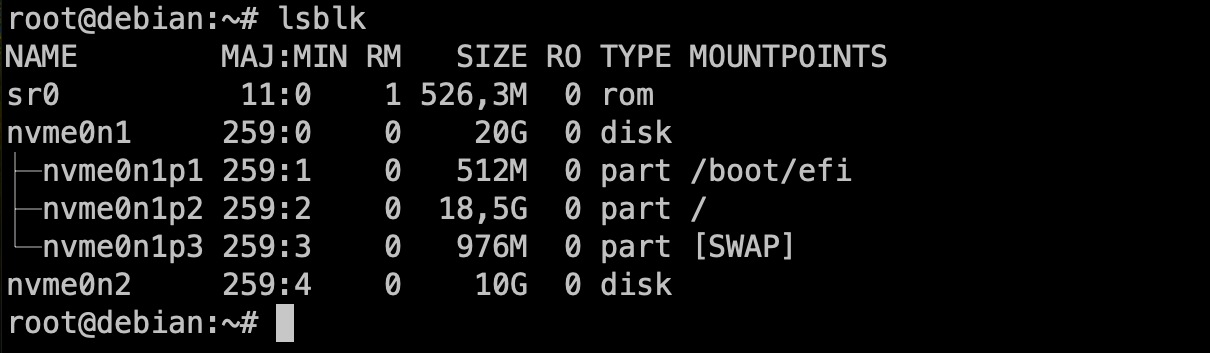
👁️ Observació:
En aquest cas, el disc dur extern s'identifica com a
/dev/nvme0n2. La etiquetanvmeindica que el disc dur és un disc dur SSD NVMe. Aquesta etiqueta pot variar en funció del tipus de disc dur que tingueu connectat com arasdaper a disc dur SATA ovdaper a disc dur virtual. -
Utilitza la comanda
fdiskper a crear una nova partició en el disc dur extern.fdisk /dev/nvme0n2
La comanda ens mostrarà un missatge d'avís indicant que no hi ha cap taula de particions en el disc dur. Això és normal ja que el disc dur és nou i no té cap partició creada.
-
Crearem una nova taula de particions en el disc dur extern. Aquesta taula serà de tipus
msdos.Command (m for help): o
💫 Recordatori:
Hi ha dos tipus de taula de particions:
msdosigpt. La taulamsdosés més antiga i té limitacions en el nombre de particions que es poden crear. La taulagptés més nova i permet crear més particions. Per tant, és recomanable utilitzar la taulagpta no se que esteu treballant en un servidor antic.
👁️ Observació:
Com únicament volem fer una sola partició, la elecció de la taula de particions no afectarà en aquest cas.
-
Crearem una nova partició primària en el disc dur extern.
Command (m for help): n Select (default p): Partition number (1-4): 1 First sector (2048-20971519, default 2048): Last sector, +/-sectors or +/-size{K,M,G,T,P} (2048-20971519, default 20971519):En aquest cas, crearem una partició primària que ocuparà tot el disc dur. Per tant, acceptarem els valors per defecte. Podeu veure el procés a la següent imatge.
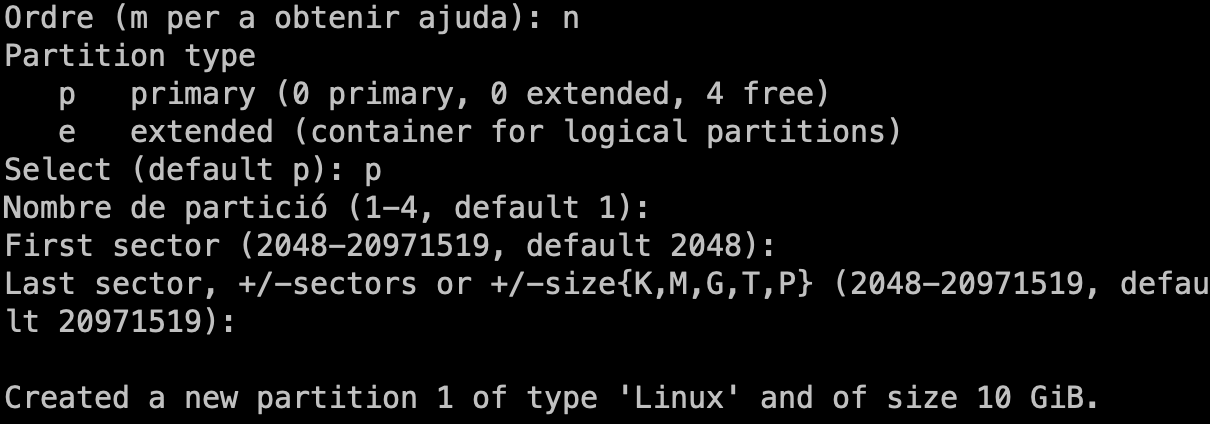
Per a finalitzar la creació de la partició, premeu la tecla
wper a guardar els canvis.
-
Comprova que la partició s'ha creat correctament.
lsblk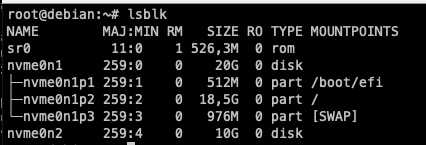
Com podeu veure, la partició s'ha creat correctament i s'identifica com a
/dev/nvme0n2p1. -
Formateja la partició amb el sistema de fitxers
ext4.mkfs.ext4 /dev/nvme0n2p1
👁️ Observació:
La sortida de la comanda ens mostra el nombre d'inodes, blocs i tamany de blocs del sistema de fitxers creat i també l'identificador UUID del sistema de fitxers. Aquest identificador és únic per a cada sistema de fitxers i ens permet identificar-lo de forma unívoca.
Podeu utilitzar la comanda
blkidper a veure l'identificador UUID del sistema de fitxers en qualsevol moment.blkid /dev/nvme0n2p1
També podeu utilitzar la comanda
tune2fsper a canviar l'etiqueta del sistema de fitxers.tune2fs -L "Backup" /dev/nvme0n2p1Per a comprovar que l'etiqueta s'ha canviat correctament, podeu utilitzar la comanda
lsblk.lsblk -o LABEL,UUID,FSTYPE,SIZE,MOUNTPOINT
💡 Nota:
L'etiqueta del sistema de fitxers ens permet identificar-lo de forma més fàcil i intuïtiva. A més, ens permet identificar el contingut del sistema de fitxers sense haver de muntar-lo.
👁️ Observació:
La comanda
lsblkté moltes opcions per a mostrar informació dels discs i les particions. Podeu consultar la documentació de la comanda per a veure totes les opcions disponibles (lsblk -h). L'argument-oens permet seleccionar les columnes que volem mostrar. En aquest cas, hem seleccionat les columnesLABEL,UUID,FSTYPE,SIZEiMOUNTPOINT. -
Monta la partició en un directori del sistema de fitxers.
mount /dev/nvme0n2p1 /mnt -
Comprova que la partició s'ha muntat correctament o podeu fer amb
lsblkodf.df -h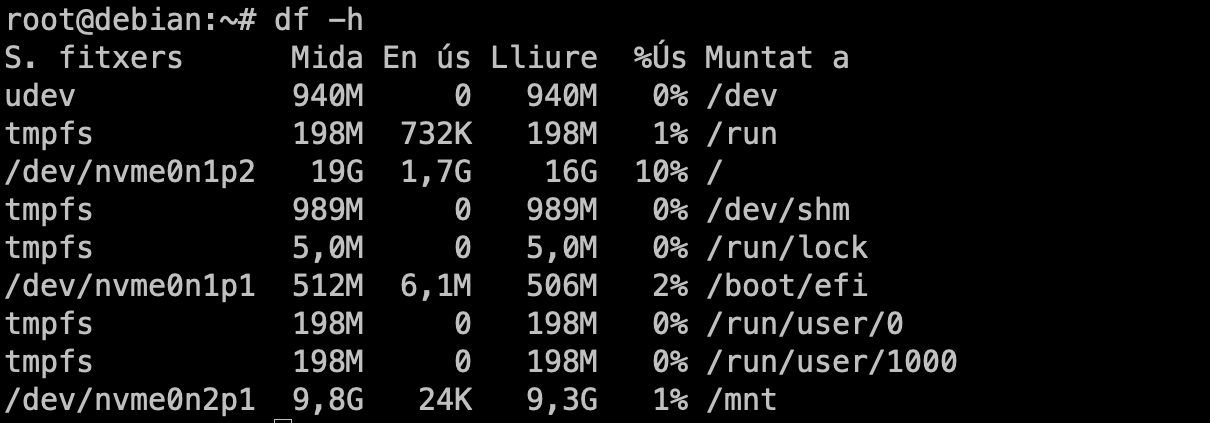
En el meu cas, he utilitzat la comanda
dfper a comprovar que la partició s'ha muntat correctament. L'argument-hens permet mostrar les dades en un format llegible per a humans. -
Còpiem totes les dades del directori
/homea la nova partició.cp -r /home/* /mnt -
Comparem les dades del directori
/homeamb les dades de la partició.diff -r /home /mnt
👁️ Observació:
En aquest cas, la comanda
diffens mostrarà un missatge indicant que no hi ha cap diferència entre els dos directoris. Ara bé, en el meu cas es mostra el directori lost+found que únicament es troba al disc dur secundari (és a dir amnt). Aquest directori és creat pel sistema de fitxersext4i s'utilitza per a emmagatzemar els inodes dels fitxers que no estan associats a cap directori. Per tant, la seva presència és normal i com no hi ha cap altra diferència, podem assegurar que la còpia s'ha realitzat correctament. -
Desmunta la partició per a poder treure el disc dur extern.
umount /mnt
Migració de directoris a particions diferents
En aquest laboratori assumirem que volem reorganitzar els directoris del nostre sistema de fitxers per a millorar el rendiment i la seguretat del sistema. Crearem 3 noves particions en el disc dur i migrarem els directoris /var, /tmp i /opt en aquestes noves particions.
-
Utilitzarem el mateix disc dur que en l'escenari anterior.
Com que ja tenim dades el que farem serà destruir totes les dades per a començar de nou. Per fer-ho, una forma senzilla és sobreescriure les dades amb zeros. Podem sobreescriure els 10GB del disc dur amb zeros amb la comanda
dd.dd if=/dev/zero of=/dev/nvme0n2 bs=1M count=10000💡 Nota:
La comanda
ddens permet copiar dades d'un lloc a un altre. En aquest cas, estem copiant zeros (/dev/zero) al disc dur (/dev/nvme0n2) amb un tamany de 1MB (bs=1M) i tantes vegades com indiquem (count=10000). Això sobreescriurà les dades del disc dur amb zeros i eliminarà totes les dades existents. -
Utilitzarem la comanda
fdiskper a crear tres noves particions en el disc dur.- La primera partició serà per a
/varamb el sistema de fitxersext4, etiquetavarmida 4GB. - La segona partició serà per a
/tmpamb el sistema de fitxersxfs, sense etiqueta i mida 2GB. - La tercera partició serà per a
/optamb el sistema de fitxersext4, etiquetaoptmida 3GB.
-
Crearem les noves particions en el disc dur. Podeu utilzar una pipeline per a automatitzar la creació de les particions.
echo -e "n\np\n\n\n+4G\nn\np\n\n\n+2G\nn\np\n\n\n+3G\nw" | fdisk /dev/nvme0n2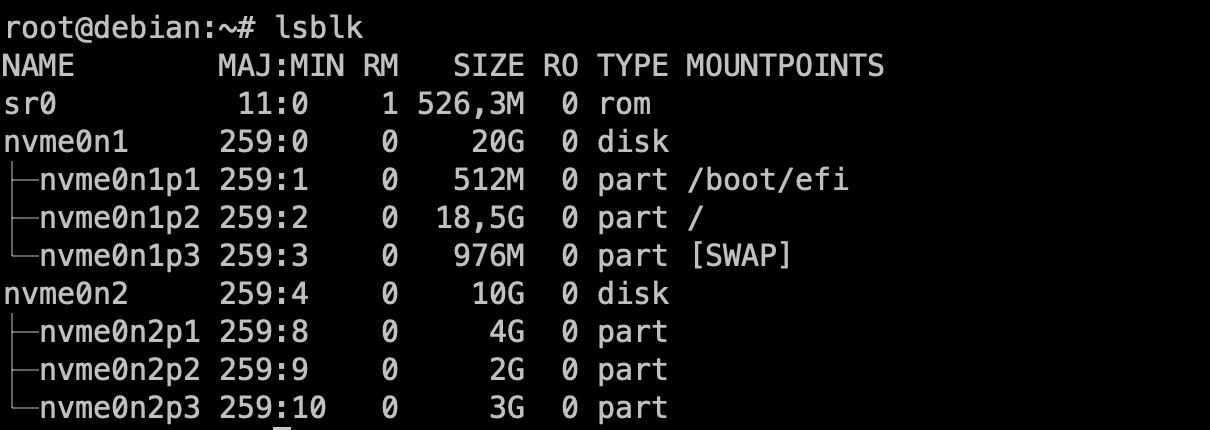
-
Formateja les particions amb els sistemes de fitxers corresponents i assigna les etiquetes.
mkfs.ext4 /dev/nvme0n2p1 tune2fs -L "var" /dev/nvme0n2p1 mkfs.xfs /dev/nvme0n2p2 mkfs.ext4 /dev/nvme0n2p3 tune2fs -L "opt" /dev/nvme0n2p3💡 Nota:
El sistema de fitxers xfs no esta instal·lat per defecte a debian, per tant, haurem d'instal·lar-lo abans de poder utilitzar-lo (
apt install xfsprogs).
- La primera partició serà per a
-
Monta les particions en directoris del sistema de fitxers. Montarem les particions a
/mntper a poder migrar els directoris.mkdir /mnt/var mount /dev/nvme0n2p1 /mnt/var mkdir /mnt/opt mount /dev/nvme0n2p3 /mnt/opt
💡 Nota: Com que la partició
/tmpés temporal, no la muntarem ja que no necessitem migrar cap dada. -
Migrarem els directoris
/var,/tmpi/opta les noves particions. Per fer-ho podem utilitzar la comandacporsync. En aquest cas utilitzarem rsync per a poder mostrar el progrés de la còpia. Normalment, la einarsyncno ve instal·lada per defecte en la majoria de distribucions, per tant, haurem d'instal·lar-la abans de poder utilitzar-la (apt install rsync).rsync -av /var /mnt cp -ax /opt /mnt🚀 Suggeriment:
Us recomano utilitzar la comanda
rsyncper a migrar els directoris ja que ens permet mostrar el progrés de la còpia i també ens permet reprendre la còpia en cas que es talli la connexió o hi hagi un error. A més, també ens permet excloure directoris o fitxers que no volem migrar i ens permet fer còpies incrementals. Podeu consultar la documentació de la comanda per a veure totes les opcions disponibles (man rsync). -
Comprovem que les dades s'han migrat correctament.
diff -r /var /mnt/var diff -r /opt /mnt/opt -
Montarem les particions en els directoris corresponents del sistema de fitxers.
umount /mnt/var mount /dev/nvme0n2p1 /var umount /mnt/opt mount /dev/nvme0n2p3 /opt mount /dev/nvme0n2p2 /tmpAra ja teniu els directoris
/var,/tmpi/optmuntats en les noves particions. Podem fer servir la comandadfper a comprovar que les particions s'han muntat correctament.
-
Ara reinicieu el sistema:
reboot💡 Nota:
Un cop reinicieu el sistema, els directoris
/var,/tmpi/optno estaran muntats en les noves particions. Podeu comprovar-ho amb la comandadf. Això és normal ja que hem muntat les particions manualment i no hem el fitxer/etc/fstabper a que es muntin automàticament en l'arrencada del sistema. -
Modifica el fitxer
/etc/fstabper a que les particions es muntin automàticament en l'arrencada del sistema.echo "/dev/nvme0n2p1 /var ext4 defaults 0 0" >> /etc/fstab echo "/dev/nvme0n2p2 /tmp xfs defaults 0 0" >> /etc/fstab echo "/dev/nvme0n2p3 /opt ext4 defaults 0 0" >> /etc/fstab💡 Nota:
El fitxer
/etc/fstabconté la informació de les particions que es muntaran automàticament en l'arrencada del sistema. Cada línia del fitxer conté la informació d'una partició. Els camps de cada línia són: dispositiu, punt de muntatge, sistema de fitxers, opcions, freqüència de comprovació i ordre de comprovació. Podeu consultar la documentació del fitxer per a més informació (man fstab). -
Comprova que les particions es muntin automàticament en l'arrencada del sistema.
rebootUn cop reinicieu el sistema, les particions
/var,/tmpi/opts'hauran muntat automàticament en els directoris corresponents. Podeu comprovar-ho amb la comandadf.
En aquest punt podriam optimitzar la configuració particions per a millorar el rendiment del sistema.
-
Utiltizarem els UUIDs en lloc dels dispositius per a muntar les particions. Això ens permetrà identificar les particions de forma unívoca i evitar problemes en cas que els dispositius canviïn d'identificador. Per fer-ho podem utilitzar la comanda
sedper actualitzar el fitxer/etc/fstab.sed -i "s|/dev/nvme0n2p1|UUID=$(blkid -s UUID -o value /dev/nvme0n2p1)|" /etc/fstab sed -i "s|/dev/nvme0n2p2|UUID=$(blkid -s UUID -o value /dev/nvme0n2p2)|" /etc/fstab sed -i "s|/dev/nvme0n2p3|UUID=$(blkid -s UUID -o value /dev/nvme0n2p3)|" /etc/fstab🔍 Pregunta: En quins casos poden canviar els dispositius o tenir duplicats?
Els dispositius poden canviar d'identificador en cas que es connectin més dispositius al sistema o es canvii l'ordre de connexió dels dispositius. Això pot provocar que les particions es muntin en llocs diferents dels esperats. Per a evitar aquest problema, és recomanable utilitzar els UUIDs en lloc dels dispositius per a muntar les particions.
-
Utilitzarem opcions més específiques per protegir la partició
/tmpper a evitar que s’executin programes des de la partició. Utilitzant les opcions nodev, nosuid, i noexec:-
Edita el fitxer
/etc/fstabi afegeix les opcionsnodev,nosuid, inoexeca la partició/tmp.ℹ️ Què fan les opcions
nodev,nosuid, inoexec?La opció nodev evita que es puguin executar dispositius en la partició. La opció nosuid evita que es puguin executar programes amb permisos de superusuari en la partició. La opció noexec evita que es puguin executar fitxers binaris des de la partició.
-
Comprova les opcions després d'editar el fitxer
/etc/fstab.mount | grep /tmp
-
Per aplicar les opcions de muntatge a la partició
/tmp, farem unrebootdel sistema.
-
Testem les opcions de muntatge de la partició
/tmp:-
Prova d'executar un programa des de la partició
/tmpcom a usuari no privilegiat.echo "echo 'Hello, World'" > /tmp/hello.sh chmod +x /tmp/hello.sh /tmp/hello.sh bash /tmp/hello.sh
-
Prova de fer el mateix com a usuari privilegiat.
su - /tmp/hello.sh bash /tmp/hello.sh
👁️ Observació:
Observeu que la opció
noexecimpedeix la execució dels binaris però no ens protegeix contra l'execució de scripts de bash. -
Prova d'accedir a un dispositiu creat a
/tmp:-
Inicialitza un dispositiu a
/tmputilitzant la comandamknod.mknod /tmp/dispositiu c 1 3⚠️ Compte:
La comanda
mknodúnica i exclusivament la poden fer els usuaris amb permisos de superusuari. Per tant, feu servir la comandasuper a canviar a l'usuarirootabans de fer servir la comandamknod. -
Per accedir al dispositiu, utilitza la comanda
cat.cat /tmp/dispositiu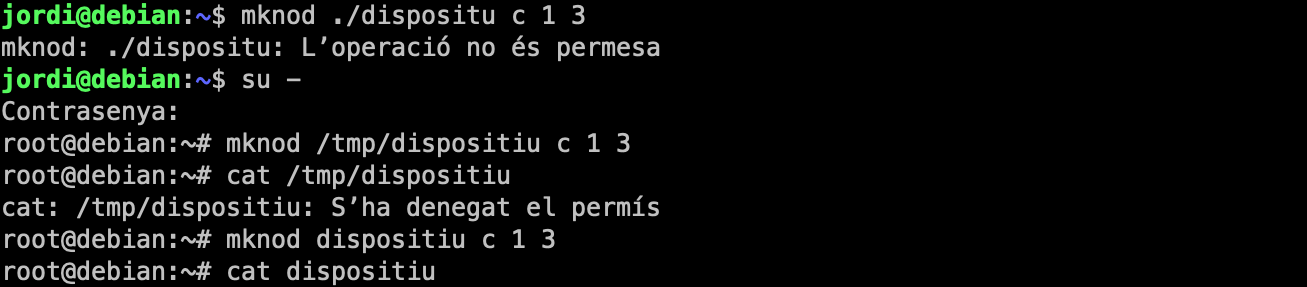
👁️ Observació:
Fixeu-vos que quan intento accedir a un dispositiu al directori actual, no hi ha cap problema. Però quan intento accedir al dispositiu creat a
/tmp, rebre un missatge d'error indicant que no es pot accedir al dispositiu. Això és degut a la opciónodevque impedeix l'accés a dispositius en la partició. -
-
Per veure, les implicacions de la opció
nosuid, podem realitzar el següent experiment:Per fer-ho, crearem un executable amb c que ens indicarà l'identificador de l'usuari real i l'identificador de l'usuari efectiu. On l'usuari real és l'usuari que ha iniciat la sessió i l'usuari efectiu és l'usuari que executa el programa. Si un programa té el bit
suidactivat, l'usuari efectiu serà l'usuari propietari del programa i no l'usuari que l'ha executat.#include <stdio.h> #include <sys/types.h> #include <unistd.h> int main() { printf("Effective user ID: %d\n", geteuid()); printf("Real user ID: %d\n", getuid()); return 0; }Compilem el programa amb la comanda
gcc.gcc -o /tmp/suid /tmp/suid.c💡 Nota:
El paquet
gccno ve instal·lat per defecte en una instal·lació mínima de Debian, per tant, haurem d'instal·lar-lo abans de poder utilitzar-lo (apt install build-essential).-
Desactiva la opció
nosuidi també la opciónoexecper a la partició/tmp. Per fer-ho, utilitza l'usuarirootper a editar el fitxer/etc/fstab. -
Remunta la partició
/tmp. -
Prova d'executar el programa com a usuari no privilegiat.
/tmp/suid -
Activa la opció
nosuidi torna a provar d'executar el programa./tmp/suid
La següent imatge representa la seqüència de comandes per a provar la opció
nosuid: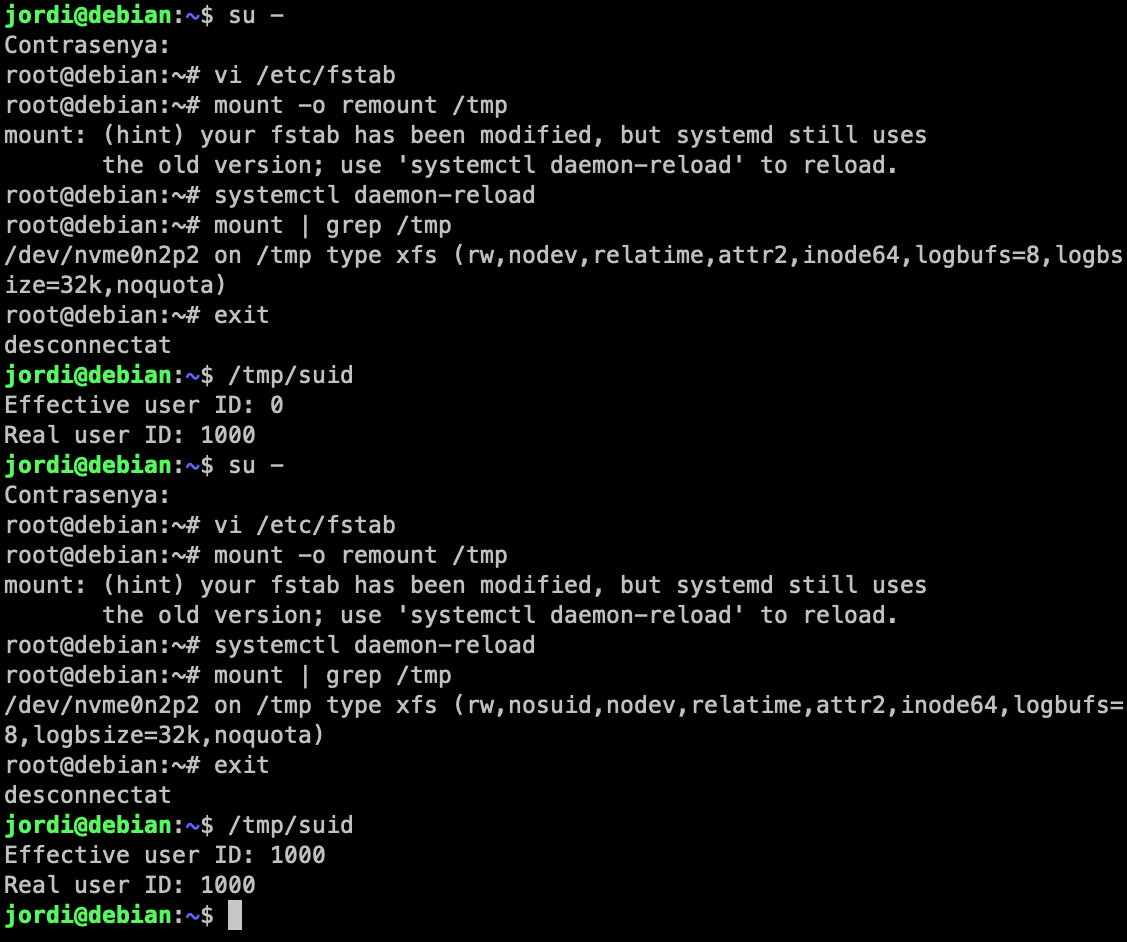
👁️ Observació:
Fixeu-vos que quan la opció
nosuidestà activada, no es pot executar el programa amb permisos de superusuari. Això és important per a evitar que els usuaris no privilegiats puguin executar programes amb permisos de superusuari. Aquesta opció pot permetre escalar privilegis i comprometre la seguretat del sistema. -
-
-
🔍 Pregunta: Per què és important tenir els directoris
/var,/tmpi/opten particions diferents?La raó principal per a tenir els directoris
/var,/tmpi/opten particions diferents és per a millorar el rendiment i la seguretat del sistema. El directori/varconté dades variables com ara logs, bases de dades, correu electrònic, etc. Si aquest directori es queda sense espai, el sistema podria fallar. El mateix raonament s'aplica al directori/tmpi/opt. Per això, és important tenir-los en particions separades per a evitar que el sistema falli. A més, tenir els directoris/var,/tmpi/opten particions separades també millora la seguretat del sistema ja que si una partició falla, les altres particions seguiran funcionant.
Anem a fer una simulació de com respon el sistema en cas de no tenir els directoris /var, /tmp i /opt en particions separades. Per a això, simularem que el directori /opt es va omplint fins a ocupar tot l'espai disponible en la partició principal del sistema.
-
Desmuntem la partició
/optper a poder continuar amb l'exercici.umount /opt -
Creeu un fitxer de 20GB al directori
/opt:dd if=/dev/urandom of=/opt/fitxer bs=1M count=20480 -
Comprova l'estat del sistema.
df -h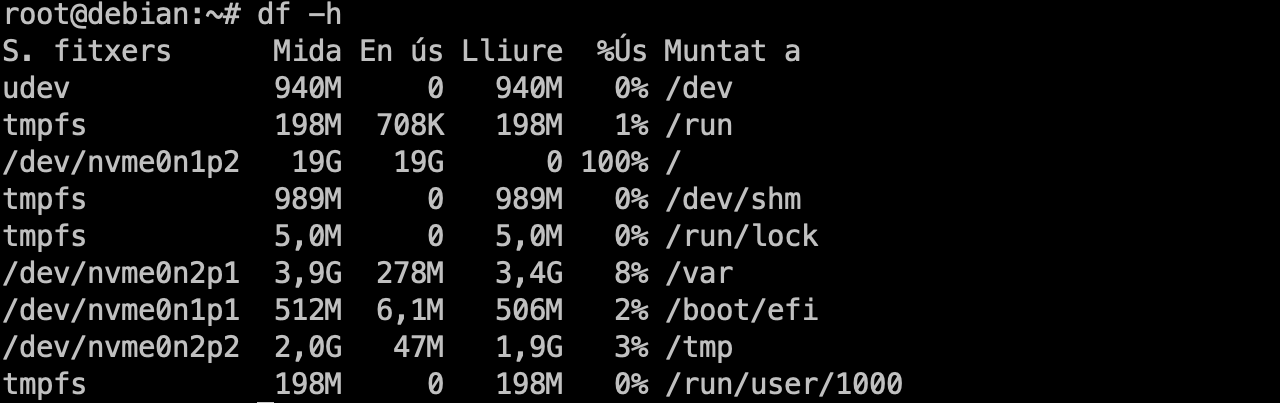
-
Intenta instal·lar un paquet amb
apti comprova que el sistema falla.apt install htop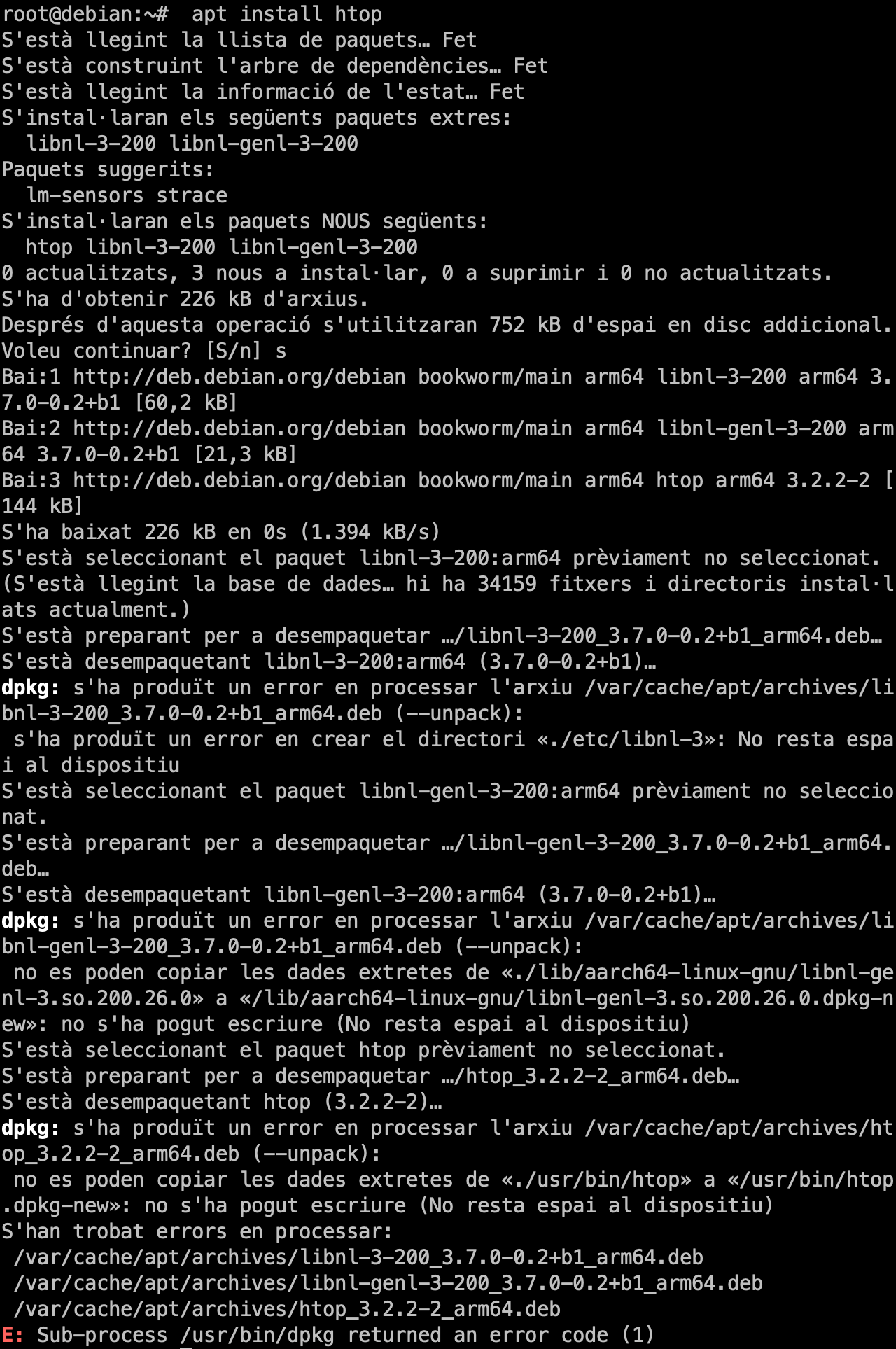
Com podeu veure, el sistema fallarà ja que no té espai suficient per a instal·lar el paquet. Això és un problema greu ja que el sistema no podrà funcionar correctament fins que no alliberem espai en la partició principal.
-
Elimina el fitxer que has creat per a poder continuar amb la resta de l'exercici.
rm /opt/fitxer -
Munteu la partició
/opti torneu a crear el fitxer per a omplir el directori.mount /dev/nvme0n2p3 /opt dd if=/dev/urandom of=/opt/fitxer bs=1M count=20480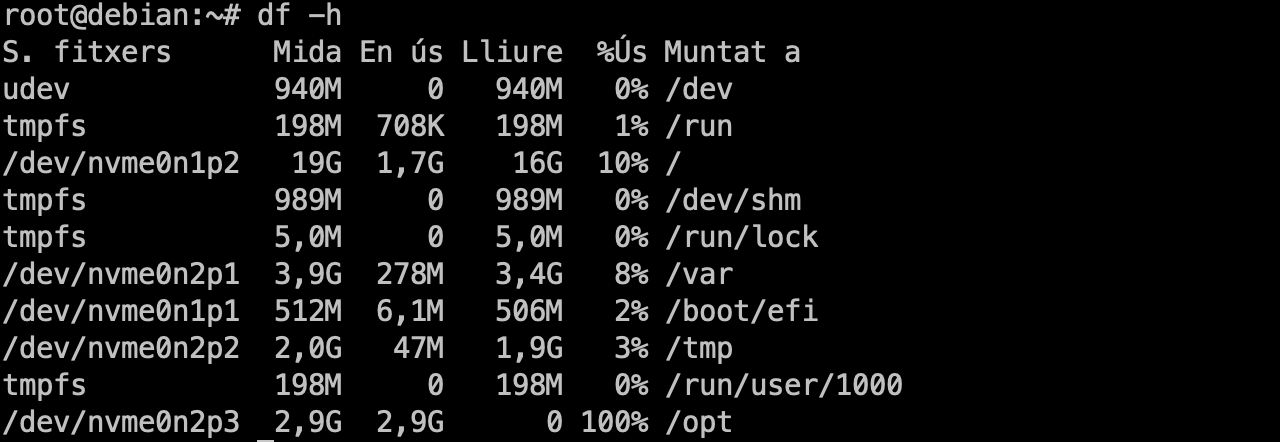
-
Ara únicament teniu la partició
/optplena; però el sistema pot continuar fent tasques:apt install htop
Simulant una corrupció a /home
En aquest escenari simularem que hem patit una corrupció a la partició /home i quines eines podem utiltzar per intentar recuperar les dades.
Preparació de l'escenari
El primer pas que farem serà migrar el directori /home a una partició diferent per a poder simular la corrupció. A continuació, simularem la corrupció i finalment recuperarem les dades.
-
Crearem una nova partició en el disc dur extern. Recorda que ja tenim 3 particions creades en aquest disc dur, per tant, la nova partició serà la quarta. Aquesta partició la farem de 600M de mida i la formatejarem amb el sistema de fitxers
xfs.echo -e "n\np\n4\n\n+600M\nw" | fdisk /dev/nvme0n2 mkfs.xfs /dev/nvme0n2p4 -
Crearem un directori on muntarem la nova partició.
mkdir /mnt/home -
Muntarem la nova partició en el directori
/mnt/home.mount /dev/nvme0n2p4 /mnt/home -
Copiarem totes les dades del directori
/homea la nova partició.rsync -a /home/ /mnt/ -
Desmontarem la partició.
umount /mnt/home -
Modificarem el fitxer
/etc/fstabper a que la partició es munti automàticament en l'arrencada del sistema.echo "/dev/nvme0n2p4 /home xfs defaults,nodev 0 0" >> /etc/fstab -
Comprovarem que la partició es munta automàticament en l'arrencada del sistema.
reboot
Simulant la corrupció
Un cop hem migrat el directori /home a una partició diferent, si tot ha anat bé, hauriau de tenir el següent resultat:
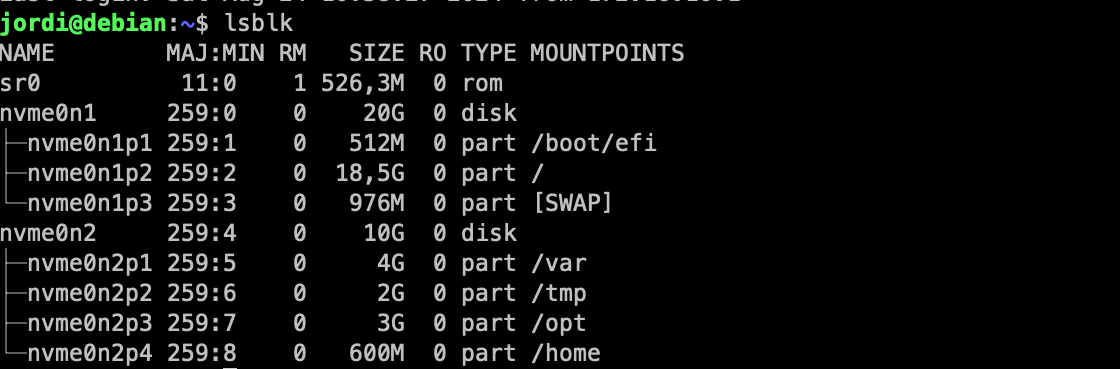
Ara podem crear fitxers i directoris al directori /home del vostre usuari normal, en el meu cas jordi.
mkdir codi
mkdir dades
touch dades/pokemon.csv
touch codi/main.c
touch codi/Makefile
touch codi/README.md
touch .vim
Per a simular una corrupció editarem alguns valors de la partició /home amb un editor hexadecimal.
-
Desmuntem la partició
/home.umount /homeCompte!: Si esteu connectats per SSH, no podreu desmuntar la partició
/homeja que el vostre usuari està utilitzant aquesta partició. En la primera sessió. Per tant, haure de fer-ho a la consola de la màquina virtual.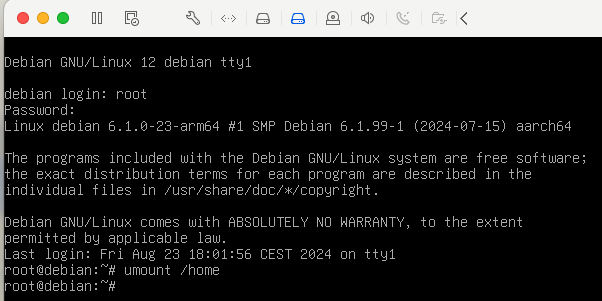
-
Obrirem la partició
/homeamb un editor hexadecimal. Podeu instal·lar l'editor hexadecimalhexeditamb la comandaapt install hexedit.hexedit /dev/nvme0n2p4 -
Modifiqueu bits a l'atzar i deseu els canvis. Per fer-ho escriviu damunt dels valors hexadecimals altres valors. Un cop fet guardeu amb Ctrl + X i Y.
Fixeu-vos en els primers valors resaltats en negreta són els que he modificat.
-
Ara intentarem muntar la partició
/homeper a comprovar que ha estat corrompuda.mount /homeSi la partició
/homes'ha corromput, hauríeu de veure un missatge d'error com aquest:
-
Els diferents sistemes de fitxers tenen eines per a comprovar la integritat dels fitxers. Per exemple, el sistema de fitxers
xfsté l'einaxfs_ncheckque permet comprovar la integritat dels fitxers.xfs_ncheck /dev/nvme0n2p4 -
Per a reparar la partició
/homeutilitzarem l'einaxfs_repair.xfs_repair /dev/nvme0n2p4 -
Un cop reparada la partició
/home, la muntarem de nou.mount /home -
Comprovarem que la partició
/homes'ha muntat correctament i conté els fitxers que havíem creat.ls /home
Sistemes de fitxers temporals
En aquest laboratori, compararem el rendiment dels sistemes de fitxers ext4, xfs i tmpfs en un entorn de còmput científic. Els sistemes de fitxers temporals, com tmpfs, poden millorar significativament el rendiment d’operacions d’entrada/sortida intensives.
Context
Assumeix l'administració d'un servidor de còmput científic que necessita realitzar moltes operacions d'entrada/sortida. En aquest escenari, el rendiment del sistema de fitxers pot ser crític per a l'eficiència del sistema. En aquest laboratori volem corrobarar la següent hipòtesi: els sistemes de fitxers temporals, com tmpfs, poden millorar significativament el rendiment d'operacions d'entrada/sortida intensives per aquest tipus de càrregues de treball.
Objectius
- Comprendre el rendiment dels sistemes de fitxers ext4, xfs i tmpfs.
- Comparar el rendiment dels sistemes de fitxers ext4, xfs i tmpfs en un entorn de còmput científic.
- Optimitzar el rendiment del sistema de fitxers utilitzant un sistema de fitxers temporal.
Preparació de l'entorn
- Creeu un nova màquina virtual amb Debian 12. Podeu utiltizar una configuració per defecte amb 2GB de RAM i 20GB d'espai en el disc principal. En cas, de tenir problemes de RAM durant l'execució de l'experiment, podeu augmentar la RAM a 4GB. Aquests problemes poden causar que el kernel mati el procés per falta de memòria (OOM Killer).
- Creeu un disc secundari de 20GB per crear els sistemes de fitxers ext4, xfs i tmpfs.
- Particioneu el disc secundari amb 3 particions: ext4, xfs i tmpfs cada una amb 5GB d'espai.
- Munteu les particions a les rutes
/mnt/ext4,/mnt/xfsi/mnt/tmpfsrespectivament.
Per crear el sistema de fitxers temporal tmpfs, podeu utilitzar la comanda següent:
mount -t tmpfs -o size=5G tmpfs /mnt/tmpfs
Per veure el sistema de fitxers muntat, podeu utilitzar la comanda següent:
df -h
Preparació de l'experiment
Per simular el nostre experiment, crearem un script de Python que generi un fitxer gran i realitzi moltes operacions d'escriptura aleatòria. Aquest script pot ser executat en un servidor de còmput per provar el rendiment del sistema de fitxers. Com a parametres d'entrada podem especificar la ruta del fitxer, la mida del fitxer, el nombre d'operacions d'escriptura aleatòria i la mida del bloc d'escriptura.
import os
import random
import time
import argparse
def create_large_file(file_path, size_in_mb):
with open(file_path, 'wb') as f:
f.write(os.urandom(size_in_mb * 1024 * 1024))
def random_write(file_path, num_operations, block_size):
with open(file_path, 'r+b') as f:
for _ in range(num_operations):
offset = random.randint(0, os.path.getsize(file_path) - block_size)
f.seek(offset)
f.write(os.urandom(block_size))
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Simulació de càlcul intensiu d'entrada/sortida")
parser.add_argument('--file_path', type=str, default="/mnt/tmpfs/large_file.bin", help="Camí del fitxer a crear")
parser.add_argument('--log_file', type=str, default="/mnt/tmpfs/experiment_log.txt", help="Camí del fitxer de registre")
parser.add_argument('--size_in_mb', type=int, default=1024, help="Mida del fitxer en MB")
parser.add_argument('--num_operations', type=int, default=10000, help="Nombre d'operacions d'escriptura aleatòria")
parser.add_argument('--block_size', type=int, default=4096, help="Mida del bloc en bytes")
args = parser.parse_args()
start_time = time.time()
create_large_file(args.file_path, args.size_in_mb)
random_write(args.file_path, args.num_operations, args.block_size)
end_time = time.time()
total_time = end_time - start_time
log_message = f"Experiment completat en {total_time} segons"
print(log_message)
Execució de l'experiment
Un cop analitzat el codi, podem executar l'experiment per comparar el rendiment dels sistemes de fitxers ext4, xfs i tmpfs.
-
Executem l'experiment amb el sistema de fitxers ext4:
python3 simulate_io_intensive.py --file_path /mnt/ext4/large_file.bin --size_in_mb 1024 --num_operations 10000 --block_size 4096 -
Executem l'experiment amb el sistema de fitxers xfs:
python3 simulate_io_intensive.py --file_path /mnt/xfs/large_file.bin --size_in_mb 1024 --num_operations 10000 --block_size 4096 -
Executem l'experiment amb el sistema de fitxers tmpfs:
python3 simulate_io_intensive.py --file_path /mnt/tmpfs/large_file.bin --size_in_mb 1024 --num_operations 10000 --block_size 4096
Ara realitzarem l'experiment 10 vegades per obtenir una mitjana del temps d'execució per a cada sistema de fitxers.
- Sistema de fitxers: ext4
for i in {1..10}
do
python3 simulate_io_intensive.py --file_path /mnt/ext4/large_file.bin --size_in_mb 1024 --num_operations 10000 --block_size 4096
done
| Temps d'execució (s) | Iteració |
|---|---|
| 3.04 | 1 |
| 2.58 | 2 |
| 2.62 | 3 |
| 3.28 | 4 |
| 2.68 | 5 |
| 2.98 | 6 |
| 2.66 | 7 |
| 3.34 | 8 |
| 2.79 | 9 |
| 2.83 | 10 |
| Mitjana | 2.88 |
- Sistema de fitxers: xfs
for i in {1..10}
do
python3 simulate_io_intensive.py --file_path /mnt/xfs/large_file.bin --size_in_mb 1024 --num_operations 10000 --block_size 4096
done
| Temps d'execució (s) | Iteració |
|---|---|
| 2.34 | 1 |
| 2.42 | 2 |
| 2.41 | 3 |
| 2.41 | 4 |
| 2.40 | 5 |
| 2.39 | 6 |
| 2.41 | 7 |
| 2.44 | 8 |
| 2.49 | 9 |
| 2.46 | 10 |
| Mitjana | 2.42 |
- Sistema de fitxers: tmpfs
for i in {1..10}
do
python3 simulate_io_intensive.py --file_path /mnt/tmpfs/large_file.bin --size_in_mb 1024 --num_operations 10000 --block_size 4096
done
| Temps d'execució (s) | Iteració |
|---|---|
| 2.33 | 1 |
| 2.29 | 2 |
| 2.28 | 3 |
| 2.29 | 4 |
| 2.32 | 5 |
| 2.32 | 6 |
| 2.30 | 7 |
| 2.33 | 8 |
| 2.31 | 9 |
| 2.29 | 10 |
| Mitjana | 2.31 |
Observeu com el sistema de fitxers tmpfs té un rendiment significativament millor que els sistemes de fitxers ext4 i xfs en aquest escenari. Això es deu al fet que tmpfs emmagatzema les dades a la memòria RAM en lloc de l'emmagatzematge en disc, el que permet un accés més ràpid a les dades. Ara bé, cal tenir en compte que les dades emmagatzemades a tmpfs es perden quan el sistema es reinicia.
Explorant d'un sistema de fitxers avançat: zfs
En aquesta secció, explorarem el sistema de fitxers ZFS (Zettabyte File System). ZFS és un sistema de fitxers avançat que ofereix moltes característiques interessants com ara la integritat de les dades, la compressió, la deduplicació, la replicació, la instantània, la clonació, etc. Per fer-ho utilitzarem la màquina virtual amb Almalinux 9.4.
-
Instal·la el repositori EPEL:
dnf install epel-release -y ``` -
Afegeix el repositori ZFS:
dnf install https://zfsonlinux.org/epel/zfs-release-2-3$(rpm --eval "%{dist}").noarch.rpm -y -
Instal·lació dels paquets necessaris:
dnf install kernel-devel -
Actualitzar el sistema:
dnf update -y -
Segons la documentació, veure Getting Started: Per defecte, el paquet zfs-release està configurat per instal·lar paquets de tipus DKMS perquè funcionin amb una àmplia gamma de kernels. Per poder instal·lar els mòduls kABI-tracking, cal canviar el repositori predeterminat de zfs a zfs-kmod.
dnf config-manager --disable zfs dnf config-manager --enable zfs-kmod dnf install zfs -
Reinicieu la màquina virtual:
reboot -
Carregeu el modul zfs al kernel de linux:
modprobe zfs
Creació d'un pool ZFS
Una pool ZFS és un conjunt de dispositius de blocs que es poden utilitzar per emmagatzemar dades. Aquesta pool pot estar formada per un o més dispositius de blocs. Aquests dispositius poden ser discos durs, SSD, dispositius de xarxa, etc. Aquesta pool es pot utilitzar per crear conjunts de dades i sistemes de fitxers ZFS. Utiltizarem el disc /etc/vdb per crear la pool.
-
Creació de la pool:
zpool create -f zfspool /dev/vdb -
Comprovació de la pool:
zpool statuspool: zfspool state: ONLINE scan: none requested config: NAME STATE READ WRITE CKSUM zfspool ONLINE 0 0 0 vdb ONLINE 0 0 0 errors: No known data errors -
Creació d'un sistema de fitxers que anomenarem (dades):
zfs create zfspool/dades -
Comprovació del conjunt de dades:
zfs listNAME USED AVAIL REFER MOUNTPOINT zfspool 135K 352M 25.5K /zfspool zfspool/dades 24K 352M 24K /zfspool/dadesNOTA: Ara mateix tenim muntats dos sistemes de fitxers: zfspool i zfspool/dades. Per defecte, els sistemes de fitxers ZFS es muntaran a /zfspool i /zfspool/dades. Però, podem canviar aquest comportament i muntar els sistemes de fitxers a un altre directori.
-
Anem a canviar el punt de muntatge de zfspool/dades a /mnt/dades:
mkdir /mnt/dadeszfs set mountpoint=/mnt/dades zfspool/dadeszfs listNAME USED AVAIL REFER MOUNTPOINT zfspool 135K 352M 25.5K /zfspool zfspool/dades 24K 352M 24K /mnt/dades -
Ara crearem uns quants fitxers i directoris a /mnt/data:
mkdir /mnt/dades/sergi mkdir /mnt/dades/adria touch /mnt/dades/sergi/a.txt touch /mnt/dades/sergi/a.c mkdir /mnt/dades/adria/config touch /mnt/dades/adria/config/.vim -
ZFS ens permet crear snapshots (instantànies) dels nostres sistemes de fitxers. Aquestes instantànies són còpies de seguretat dels nostres sistemes de fitxers en un moment determinat. Aquestes instantànies es poden utilitzar per restaurar els nostres sistemes de fitxers en cas de fallada o error. Crearem una instantània del nostre sistema de fitxers zfspool/dades:
zfs snapshot zfspool/dades@snap1 -
Ara eliminarem el directori /mnt/dades/adria/config:
rm -rf /mnt/dades/adria/config -
Podem utilitzar la comanda zfs rollback per restaurar el nostre sistema de fitxers a l'estat de l'instantània:
zfs rollback zfspool/dades@snap1 -
Comprovem que el directori /mnt/dades/adria/config ha estat restaurat:
ls -la /mnt/dades/adria/configtotal 2 drwxr-xr-x. 2 root root 3 Oct 3 10:01 . drwxr-xr-x. 3 root root 3 Oct 3 10:01 .. -rw-r--r--. 1 root root 0 Oct 3 10:01 .vim -
Podem utilitzar la comanda zfs clone per crear un clon del nostre sistema de fitxers zfspool/dades:
zfs clone zfspool/dades@snap1 zfspool/dades/clone1OBSERVACIÓ 1: Els clons en ZFS permeten realitzar migracions de dades eficients i segures. Abans d'efectuar canvis en el sistema de producció o transferir dades a un nou sistema, es pot crear un clon de les dades existents per provar la migració sense afectar les dades originals
OBSERVACIÓ 2: Quan es requereix realitzar operacions de processament, anàlisi o transformació de dades, els clons permeten fer-ho sense modificar o posar en perill les dades originals.
zfs listNAME USED AVAIL REFER MOUNTPOINT zfspool 217K 352M 24K /zfspool zfspool/dades 43K 352M 29K /mnt/dades zfspool/dades/clone1 0B 352M 29K /mnt/dades/clone1 -
Per eliminar un clon, utilitzarem la comanda zfs destroy:
zfs destroy zfspool/dades/clone1 -
Per eliminar una instantània, utilitzarem la comanda zfs destroy:
zfs destroy zfspool/dades@snap1 -
Per eliminar un sistema de fitxers, utilitzarem la comanda zfs destroy:
zfs destroy zfspool/dadesNOTA: Si enlloc d'eliminar volem únicament desmuntar, utilitzarem la comanda zfs umount. Per exemple:
zfs umount zfspool/dades. -
Per eliminar una pool, utilitzarem la comanda zpool destroy:
zpool destroy zfspool
Raids
En aquest laboratori aprendrem a configurar i gestionar sistemes RAID en un servidor Linux. Aquesta tecnologia ens permetrà augmentar la disponibilitat i la tolerància a fallades dels nostres sistemes.
Objectius
- Comprendre els conceptes bàsics de RAID.
- Configurar diferents nivells de RAID.
- Comparar el rendiment de diferents nivells de RAID.
Comandes bàsiques
mdadm: Utilitzada per gestionar dispositius RAID.lsblk: Mostra informació sobre els dispositius de bloc.fio: Eina de benchmarking per provar el rendiment dels dispositius de bloc.mount: Utilitzada per muntar sistemes de fitxers.mkfs: Utilitzada per crear sistemes de fitxers.
Continguts
Comparant el rendiment de diferents nivells de RAIDs
En aquest laboratori, compararem el rendiment de diferents nivells de RAID utilitzant l'eina de benchmark fio. En concret, compararem el rendiment del RAID 0 i del RAID 1 en operacions d'escriptura i de lectura. Aquesta anàlisi ens permetrà comprendre les diferències de rendiment entre els dos tipus de RAID i determinar quin tipus de RAID és més adequat per a les nostres necessitats.
Configuració de l'entorn
En aquest laboratori utiltizarem una màquina virtual amb Debian 12 i 4 discos secundaris de 5GB cadascun. Aquests discos secundaris es configuraran en dos nivells de RAID diferents: RAID0 i RAID1.
📝 Nota
Si no voleu utilitzar 4 discs podeu utiltizar 2 disc amb diferents particions per a crear les RAID. El més important és que la RAID0 i la RAID1 tinguin el mateix nombre de discs, capacitat i tipus per poder fer una comparació justa.
Creació de les raids
-
Creació de raid0:
mdadm --create --verbose /dev/md0 --level=0 --raid-devices=2 /dev/nvme0n2 /dev/nvme0n3 -
Creació del sistema de fitxers:
mkfs.ext4 /dev/md0 -
Muntatge del sistema de fitxers:
mkdir /mnt/md0 mount /dev/md0 /mnt/md0 -
Creació de raid1:
mdadm --create --verbose /dev/md1 --level=1 --raid-devices=2 /dev/nvme0n4 /dev/nvme0n5 -
Creació del sistema de fitxers:
mkfs.ext4 /dev/md1 -
Muntatge del sistema de fitxers:
mkdir /mnt/md1 mount /dev/md1 /mnt/md1
Instal·lant l'eina de benchmark fio
La eina fio ens permetrà realitzar diferents experriments per tal de comparar diferents operacions d'entrada/sortida amb diferents configuracions de blocs.
apt install fio -y
Proves de rendiment
-
Test de rendiment del RAID0 en oepracions d'escriptura:
fio --name=write-raid1 --ioengine=libaio --iodepth=32 --rw=write \ --bs=4k --size=500M --numjobs=4 --runtime=120 --time_based \ --ramp_time=15 --group_reporting --filename=/dev/raid1 \ --output-format=json --output=/tmp/write-raid1.json -
Test de rendiment del RAID0 en operacions de lectura:
fio --name=read-raid0 --ioengine=libaio --iodepth=32 --rw=read \ --bs=4k --size=500M --numjobs=4 --runtime=120 --time_based \ --ramp_time=15 --group_reporting --filename=/dev/raid0 \ --output-format=json --output=/tmp/read-raid0.json -
Test de rendiment del RAID1 en operacions d'escriptura:
fio --name=write-raid1 --ioengine=libaio --iodepth=32 --rw=write \ --bs=4k --size=500M --numjobs=4 --runtime=120 --time_based \ --ramp_time=15 --group_reporting --filename=/dev/raid1 \ --output-format=json --output=/tmp/write-raid1.json -
Test de rendiment del RAID1 en operacions de lectura:
fio --name=read-raid1 --ioengine=libaio --iodepth=32 --rw=read \ --bs=4k --size=500M --numjobs=4 --runtime=120 --time_based \ --ramp_time=15 --group_reporting --filename=/dev/raid1 \ --output-format=json --output=/tmp/read-raid1.json
Anàlisi de resultats
Per analitzar els resultats obtinguts, ens centrarem en els següents paràmetres:
- Bandwidth: La velocitat de transferència de dades en bytes per segon.
- IOPS: El nombre d’operacions d’entrada/sortida per segon.
- Latència: El temps que triga el sistema a respondre a una petició d’entrada/sortida.
- Total IO: El nombre total d’operacions d’entrada/sortida.
| Op. | RAID | Bandwidth (GB/s) | IOPS | Latència(µs) | Total IO (GB) |
|---|---|---|---|---|---|
| W | 0 | 10.58 | 2.65e+06 | 48.22 | 317.6 |
| W | 1 | 7.93 | 1.98e+06 | 64.40 | 238.0 |
| R | 0 | 18.76 | 4.69e+06 | 27.16 | 562.98 |
| R | 1 | 18.82 | 4.71e+06 | 27.08 | 564.6 |
La taula mostra un resum dels resultats obtinguts de les proves de rendiment del RAID 0 i del RAID 1. Aquests resultats corroboren les diferències de rendiment entre els dos tipus de RAID. En primer lloc, si ens centrem en el Bandwidth, podem observar un rendiment similar en les operacions de lectura amb unes velocitats de 18.76GB/s i 18.82GB/s respectivament. En canvi, el RAID 0 té un rendiment superior en les operacions d'escriptura amb una velocitat de 10.59GB/s, mentre que el RAID 1 té una velocitat de 7.93GB/s. Això es deu al fet que en el RAID 0 les dades es distribueixen entre els dos discs, mentre que en el RAID 1 les dades s'han de copiar en tots dos discs. En segon lloc, si analitzem les variables de Latency i IOPS observem un rendiment similar en les operacions de lectura, amb una latència de 27.16µs i 27.08µs respectivament. En canvi, en les operacions d'escriptura, el RAID 0 té una latència de 48.22µs i 64.40µs en el RAID 1. Finalment, en termes de Total IO, el RAID 0 té un rendiment superior amb 317.69GB en les operacions d'escriptura, mentre que el RAID 1 té un rendiment de 238.01GB.
🚀 Conclusió:
Aquesta anàlisi demostra que el RAID 0 ofereix un rendiment superior en termes de velocitat d'escriptura, mentre que el RAID 1 proporciona una major seguretat de les dades a costa d'una velocitat d'escriptura més lenta. Per tant, la selecció del tipus de RAID depèn de les necessitats específiques de l'usuari, prioritzant la velocitat o la seguretat de les dades.
Tolerància a fallades
Preparació de l'entorn
En aquest laboratori podeu utilitzar la mateixa màquina virtual que en el laboratori anterior. Ens centrarem en la tolerància a fallades dels sistemes RAID0 i RAID1.
Simulant una fallada en un disc del RAID1
-
Crearem dades en el sistema de fitxers del RAID1.
fallocate -l 100M /mnt/md1/testfile -
Simularem una fallada en un dels discos del RAID1. Utilitzant l'argument
--set-faultydemdadmpodem simular una fallada en un dels discos.mdadm --manage /dev/md1 --set-faulty /dev/nvme0n4 -
Comproveu l'estat del RAID1 amb la comanda
mdadm --detail /dev/md1.📝 Nota
Alternativament, podeu utilitzar la comanda
cat /proc/mdstatper comprovar l'estat dels vostres dispositius RAID. -
Comproveu integritat de les dades:
ls -la /mnt/md1Si tot ha anat bé, les dades haurien de ser accessibles.
Simulant una fallada en un disc del RAID0
-
Crearem dades en el sistema de fitxers del RAID0.
fallocate -l 100M /mnt/md0/testfile -
Utilitzarem la comanda
hexdumpper escriure dades aleatòries al disc i corrompre'l.hexdump -C /dev/nvme0n2 | head -n 10 -
Desmuntarem el sistema de fitxers i el muntarem de nou.
umount /mnt/md0 mount /dev/md0 /mnt/md0 -
El sistema us hauria de mostrar un error semblant a aquest:
mount: /mnt/md0: can't read superblock on /dev/md0. dmesg(1) may have more information after failed mount system call.En aquest cas, el sistema no pot muntar el sistema de fitxers ja que el disc ha estat corromput.
Migració d'un servidor tradicional a un servidor amb RAID
En aquest laboratori aprendrem a migrar un servidor tradicional a un servidor amb RAID.
Notes
📝 Nota 1
Es possible que observeu un missatge com el següent quan realitzeu el laboratori: mount: (hint) your fstab has been modified, but systemd still uses the old version; use 'systemctl daemon-reload' to reload. Podeu ignorar aquest missatge ja que no afecta el funcionament del laboratori. O si voleu podeu executar la comanda
systemctl daemon-reloadper assegurar-vos que el sistema ha recarregat la configuració.
Preparació de l'entorn
Assumirem una màquina virtual amb AlmaLinux on tenim un disc dur principal de 20GB particionat de la següent manera:
/bootde 600MB amb el sistema de fitxersxfs./boot/efide 1024MB amb el sistema de fitxersvfat.swapde 2GB./de 16GB amb el sistema de fitxersxfs.
Instal·leu els paquet següents que necessitarem per aquest laboratori:
-
mdadm: Utilitzada per gestionar dispositius RAID.dnf install mdadm -y -
rsync: Utilitzada per copiar el contingut de les particions.dnf install rsync -y
Disseny de la nova arquitectura
Utiltizarem 2 discs secundaris de 20GB cadascun per crear la següent arquitectura:
- RAID 1 amb
/booti/boot/efi. - RAID 1 amb
swap. - RAID 1 amb
/.
Preparació dels discs
-
Creació de la taula de particions i de les particions als discs secundaris.
-
/boot/efi:echo -e "g\nn\np\n\n\n+600M\nt\n29\nw" | fdisk /dev/nvme0n2 echo -e "g\nn\np\n\n\n+600M\nt\n29\nw" | fdisk /dev/nvme0n3 -
boot:echo -e "n\np\n\n\n+1024M\nt\n2\n29\nw" | fdisk /dev/nvme0n2 echo -e "n\np\n\n\n+1024M\nt\n2\n29\nw" | fdisk /dev/nvme0n3 -
swap:echo -e "n\np\n\n\n+2G\nt\n3\n29\nw" | fdisk /dev/nvme0n2 echo -e "n\np\n\n\n+2G\nt\n3\n29\nw" | fdisk /dev/nvme0n3 -
/:echo -e "n\np\n\n\n+16G\nt\n4\n29\nw" | fdisk /dev/nvme0n2 echo -e "n\np\n\n\n+16G\nt\n4\n29\nw" | fdisk /dev/nvme0n3
-
-
Comproveu que les particions s'han creat correctament amb
lsblk.
RAID 1 amb /boot/efi
-
Creació del RAID 1 amb
/boot/efi.mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 \ --metadata=1.0 /dev/nvme0n2p1 /dev/nvme0n3p1 -
Creació del sistema de fitxers
fat32.mkfs.vfat /dev/md0 -
Crear un punt de muntatge temporal i muntar el sistema de fitxers.
mkdir /tmp/raid1 mount /dev/md0 /tmp/raid1 -
Copiar el contingut de
/boot/efial RAID 1.rsync -avx /boot/efi/ /tmp/raid1 -
Desmuntar la RAID:
umount /tmp/raid1 -
Seleccionar el UUID del RAID 1:
EFI_RAID_UUID=$(blkid -s UUID -o value /dev/md0) -
Actualitzar
/etc/fstabamb el nou UUID.CURRENT_BOOT_UUID=$(blkid -s UUID -o value /dev/nvme0n1p1) sed -i "s|UUID=$CURRENT_BOOT_UUID|UUID=$EFI_RAID_UUID |" /etc/fstab
RAID 1 amb boot
Repetiu els passos anteriors per crear el RAID 1 anomenta (/dev/md1) amb /boot. Utiltizant les particions /dev/nvme0n2p2 i /dev/nvme0n3p2.
-
Creació del RAID 1 amb
/boot.mdadm --create --verbose /dev/md1 --level=1 --raid-devices=2 \ --metadata=1.0 /dev/nvme0n2p2 /dev/nvme0n3p2 -
Creació del sistema de fitxers
xfs.mkfs.xfs /dev/md1 -
Crear un punt de muntatge temporal i muntar el sistema de fitxers.
mkdir /tmp/raid2 mount /dev/md1 /tmp/raid2 -
Copiar el contingut de
/bootal RAID 1.rsync -avx /boot/ /tmp/raid2 -
Desmuntar la RAID:
umount /tmp/raid2 -
Seleccionar el UUID del RAID 1:
BOOT_RAID_UUID=$(blkid -s UUID -o value /dev/md1) -
Actualitzar
/etc/fstabamb el nou UUID.CURRENT_BOOT_UUID=$(blkid -s UUID -o value /dev/nvme0n1p2) sed -i "s|UUID=$CURRENT_BOOT_UUID|UUID=$BOOT_RAID_UUID |" /etc/fstab
RAID 1 amb swap
-
Creació del RAID 1 amb
swap.mdadm --create --verbose /dev/md2 --level=1 --raid-devices=2 \ /dev/nvme0n2p3 /dev/nvme0n3p3 -
Creació del sistema de fitxers
swap.mkswap /dev/md2 -
Activar el sistema de fitxers
swap.swapon /dev/md2 -
Actualitzar
/etc/fstabamb el nou UUID.CURRENT_SWAP_UUID=$(blkid -s UUID -o value /dev/nvme0n1p3) SWAP_RAID_UUID=$(blkid -s UUID -o value /dev/md2) sed -i "s|UUID=$CURRENT_SWAP_UUID|UUID=$SWAP_RAID_UUID |" /etc/fstab -
Compproveu que la partició swap s'ha activat correctament.
swapon --show
RAID 1 amb /
-
Creació del RAID 1 amb
/.mdadm --create --verbose /dev/md3 --level=1 --raid-devices=2 \ /dev/nvme0n2p4 /dev/nvme0n3p4 -
Creació del sistema de fitxers
xfs.mkfs.xfs /dev/md3 -
Crear un punt de muntatge temporal i muntar el sistema de fitxers.
mkdir /tmp/raid3 mount /dev/md3 /tmp/raid3 -
Noms de dispositius RAID persistents.
mkdir -p /etc/mdadm mdadm --detail --scan > /etc/mdadm/mdadm.conf -
Seleccionar el UUID del RAID 1:
ROOT_RAID_UUID=$(blkid -s UUID -o value /dev/md3) -
Actualitzar
/etc/fstabamb el nou UUID.CURRENT_ROOT_UUID=$(blkid -s UUID -o value /dev/nvme0n1p4) sed -i "s|UUID=$CURRENT_ROOT_UUID|UUID=$ROOT_RAID_UUID |" /etc/fstab -
Copiar el contingut de
/al RAID 1.cp -ax / /tmp/raid3
Configuració del GRUB
-
Actualitzar la configuració del GRUB.
vi /etc/default/grubTeniu dos opcions per configurar el GRUB, com els noms dels dispositius no canviaran, ja que els hem fet persistent, podeu utilitzar el nom del dispositiu
/dev/mdXo el UUID del RAID.GRUB_CMDLINE_LINUX="root=/dev/md3 rd.auto ..." GRUB_ENABLE_BLSCFG=false GRUB_CMDLINE_LINUX_DEFAULT=""o bé utilitzant el UUID del RAID.
GRUB_CMDLINE_LINUX="root=UUID=<UUID> rd.auto ..." GRUB_ENABLE_BLSCFG=false GRUB_CMDLINE_LINUX_DEFAULT="" # on <UUID> és el UUID del RAID 1 amb /. # rd.auto: Per carregar automàticament els mòduls RAID. # GRUB_ENABLE_BLSCFG=false: Per desactivar el suport de BLS. # GRUB_CMDLINE_LINUX_DEFAULT="": Per desactivar les opcions per defecte. -
Copiar el GRUB al nou disc.
cp /etc/default/grub /tmp/raid3/etc/default/grub -
Instal·lar el GRUB a cada disc secundari.
efibootmgr --create --disk /dev/nvme0n2 --part 1 --label "almalinux-mirror-01" --loader "\EFI\almalinux\grubaa64.efi" efibootmgr --create --disk /dev/nvme0n3 --part 1 --label "almalinux-mirror-02" --loader "\EFI\almalinux\grubaa64.efi" -
Actualitzar la configuració del GRUB.
grub2-mkconfig -o /boot/efi/EFI/almalinux/grub.cfg -
Actualitzarem la
initramfsper incloure els mòduls RAID.dracut -f -
Reiniciar el sistema.
reboot
Nota: Aquesta configuració no és del tot correcta, i veureu que el raid de la partició del sistema
/no es munta i es segueix utilitzant la partició original. Tot i això, si en el grub indiquemroot=/dev/md3ird.auto, el sistema arrenca correctament. Per tant, deures investigar com fer que el sistema munti el raid de la partició/correctament.
Logical Volume Manager (LVM)
En aquest laboratori aprendràs a configurar i gestionar un sistema de fitxers basat en LVM (Logical Volume Manager) en un servidor Linux. Aquesta tecnologia permet una gestió flexible de l'espai de disc, permetent redimensionar, afegir i eliminar particions sense necessitat de reiniciar el sistema.
Contextualització
Imagineu que sou l'administrador d'un servidor Linux que allotja una aplicació web. Les característiques del servidor les anirem detallant al llarg de les tasques. La vostra tasca és analitzar el sistema actual que utilitza particions tradicionals i valorar la possibilitat de migrar a LVM. A més a més, haureu d'intentar optimitzar el sistema.
Objectius
Els objectius d'aquest laboratori són:
- Comprendre els conceptes bàsics de LVM.
- Analitzar els diferents modes de funcionament de LVM.
- Realitzar una migració completa a LVM.
- Implementar operacions avançades amb LVM, com ara snapshots i thin provisioning.
- Revisar les metadadades en LVM i el seu impacte.
Tasques
- Anàlisi dels modes striped i linear
- Desplegament d'una web amb LVM
- Gestió de fallades
- Snapshots
- Mirroring
Rúbriques d'avaluació
Realització de les tasques: 50%
S'ha de mostrar en un document amb format lliure les evidències de la realització de les tasques. Aquest document es pot incloure al informe tècnic o es pot lliurar com a document adjunt.
Informe tècnic: 50%
S'ha de lliure un informe tècnic que agrupi tots els requeriments i la situació inicial del servidor. A més a més, heu de fer una proposta de canvis i justificar-los. L'informe ha de respondre de forma directa o indirecta, les preguntes d'analisi de les diferents tasques.
| Criteris d'avaluació | Excel·lent (5) | Notable(3-4) | Acceptable(1-2) | No Acceptable (0) |
|---|---|---|---|---|
| Contingut | El contingut és molt complet i detallat. S'han cobert tots els aspectes de la tasca. | El contingut és complet i detallat. S'han cobert la majoria dels aspectes de la tasca. | El contingut és incomplet o poc detallat. Falten alguns aspectes de la tasca. | El contingut és molt incomplet o inexistent. |
| Precisió i exactitud | La informació és precisa i exacta. No hi ha errors. | La informació és precisa i exacta. Hi ha pocs errors. | La informació és imprecisa o inexacta. Hi ha errors. | La informació és molt imprecisa o inexacta. Hi ha molts errors. |
| Organització | La informació està ben organitzada i estructurada. És fàcil de seguir. | La informació està organitzada i estructurada. És fàcil de seguir. | La informació està poc organitzada o estructurada. És difícil de seguir. | La informació està molt poc organitzada o estructurada. És molt difícil de seguir. |
| Diagrames i il·lustracions | S'han utilitzat diagrames i il·lustracions de collita pròpia per aclarir la informació. Són molt útils. | S'han utilitzat diagrames i il·lustracions de collita pròpia per aclarir la informació. Són útils. | S'han utilitzat pocs diagrames o il·lustracions de collita pròpia. Són poc útils. | No s'han utilitzat diagrames o il·lustracions de collita pròpia. |
| Plagi | No hi ha evidències de plagi. Tota la informació és original. | Hi ha poques evidències de plagi. La majoria de la informació és original. | Hi ha evidències de plagi. Alguna informació no és original. | Hi ha moltes evidències de plagi. Poca informació és original. |
| Bibliografia | S'ha inclòs una bibliografia completa i detallada. | S'ha inclòs una bibliografia completa. | S'ha inclòs una bibliografia incompleta. | No s'ha inclòs una bibliografia. |
| Estil | L'estil és molt adequat i professional. S'ha utilitzat un llenguatge tècnic precís. | L'estil és adequat i professional. S'ha utilitzat un llenguatge tècnic precís. | L'estil és poc adequat o professional. Hi ha errors en el llenguatge tècnic. | L'estil és molt poc adequat o professional. Hi ha molts errors en el llenguatge tècnic. |
Anàlisi dels modes striped i linear
Abans de procedir amb la migració completa, realitzeu una prova amb un disc dur utilitzant un volum lògic en mode striped i un altre en mode linear. L’objectiu és comparar el rendiment de cada mode i analitzar quin dels dos ens convé més per a la nostra configuració.
Objectius
- Pràctica les comandes bàsiques de LVM.
- Observar les diferències entre els modes striped i linear en LVM.
- Apendre a fer analisis de rendiment d'operació d'entrada/sortida amb
fio.
Preparació
-
Inicialitzeu una nova màquina virtual amb un disc dur de 20 GB i instal·leu AlmaLinux. Podeu fer servir el sistema de particions tradicionals per defecte. Podeu seguir el procediment descrit a les diapositives de classe.
-
Adjunteu dos disc dur addicionals de 10 GB a la màquina virtual. Aquests discs dur s’utilitzaràn per a crear els volums lògics en mode striped i linear i comparar-ne el rendiment.
-
Assegureu-vos que l'estat inicial del sistema és correcte. Utiltizeu la comanda
lsblkper comprovar que teniu aquest estat inicial:NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT nvme0n1 259:0 0 20G 0 disk ├─nvme0n1p1 259:1 0 600MB 0 part /boot/efi ├─nvme0n1p2 259:2 0 1G 0 part /boot ├─nvme0n1p3 259:3 0 2G 0 part [SWAP] └─nvme0n1p4 259:4 0 16.4G 0 part / nvme0n2 259:5 0 10G 0 disk nvme0n3 259:6 0 10G 0 diskNota: El nom del dispositiu pot variar segons les vostres opcions de virtualització.
Tasques
-
Inicialitzeu els disc dur secundaris amb
pvcreate, modifiqueu l'etiqueta dels discs en funció del vostre sistema de virtualització. En cas de dubte, podeu utilitzar la comandalsblkper identificar-los.pvcreate /dev/nvme0n2 /dev/nvme0n3 -
Creeu un grup de volums anomenat
vg0amb el discs secundaris.vgcreate vg0 /dev/nvme0n2 /dev/nvme0n3 -
Creeu 2 volums lògics, un en mode striped i un altre en mode linear.
-
Mode striped: Utilitzeu la comanda
lvcreateper crear un volum lògic en mode striped amb 2 extends i un tamany de 5GB.lvcreate -L 5G -n lv_striped -i 2 vg0 -
Mode linear: Utilitzeu la comanda
lvcreateper crear un volum lògic en mode linear amb un tamany de 5GB.lvcreate -L 5G -n lv_linear vg0
-
-
Visualització de volums lògics: Ara comprovarem les característiques dels volums lògics creats. Per fer-ho, utilitzeu la comanda
lvsi personalitzeu la seva sortida per mostrar només el nom del volum lògic, el tipus de volum lògic, el tamany, el nombre de stripes, el rang de segments i el tamany del segment. A més, filtreu la llista per mostrar només els volums lògics que pertanyen al grup de volumsvg0.lvs -o lv_name,lv_attr,lv_size,stripes,seg_le_ranges,seg_size_pe -S vg_name=vg0 -
Formateu els volums lògics amb el sistema de fitxers
ext4.-
Volum lògic en mode striped:
mkfs.ext4 /dev/vg0/lv_striped -
Volum lògic en mode linear:
mkfs.ext4 /dev/vg0/lv_linear
-
-
Munteu els volums lògics en els directoris
/mnt/stripedi/mnt/linear.-
Volum lògic en mode striped:
mkdir /mnt/striped mount /dev/vg0/lv_striped /mnt/striped -
Volum lògic en mode linear:
mkdir /mnt/linear mount /dev/vg0/lv_linear /mnt/linear
-
-
Avaluació del rendiment d’escriptura: Utilitzeu el programa
ddper escriure un arxiu de 1GB en cada volum lògic i avaluar el rendiment de les operacions d’escriptura.dd if=/dev/zero of=/mnt/striped/file bs=1M count=1024# 1024+0 records in # 1024+0 records out # 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.369798 s, 2.9 GB/sdd if=/dev/zero of=/mnt/linear/file bs=1M count=1024# 1024+0 records in # 1024+0 records out # 1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.558201 s, 1.9 GB/sEn els resultats obtinguts es pot veure que el volum lògic en mode striped té un rendiment superior al volum lògic en mode linear. En el mode striped, les dades es distribueixen entre tots els discs disponibles, permetent que les operacions d’escriptura es realitzin en paral·lel. En canvi, en el mode linear, les dades es guarden seqüencialment en un disc fins que s’omple, i llavors comencen a guardar-se en el següent disc. Això significa que les operacions d’escriptura només es poden realitzar en un disc a la vegada. En el nostre cas, com que tenim dos discs el seu rendiment és el doble que en mode linear.
Podem observar aquest comportament amb l'eina
iostat. Per fer-ho obriu 2 terminals:# Terminal 1 iostat -hx /dev/nvme0n2 /dev/nvme0n3 1# Terminal 2 dd if=/dev/zero of=/mnt/striped/file bs=1M count=1024Nota: Per instal·lar
iostatexecuteudnf install sysstat -y.Observareu la columna (w/s) on s'indica el nombre d'operacions d'escriptura per segon. En cada disc tenim 476 operacions d'escriptura per segon, durant la realització del
dd.avg-cpu: %user %nice %system %iowait %steal %idle 0.0% 0.0% 22.2% 0.0% 0.0% 77.8% r/s rkB/s rrqm/s %rrqm r_await rareq-sz Device 0.00 0.0k 0.00 0.0% 0.00 0.0k nvme0n2 0.00 0.0k 0.00 0.0% 0.00 0.0k nvme0n3 w/s wkB/s wrqm/s %wrqm w_await wareq-sz Device 467.00 460.0M 6899.00 93.7% 0.80 1008.7k nvme0n2 467.00 460.0M 6901.00 93.7% 0.78 1008.7k nvme0n3 d/s dkB/s drqm/s %drqm d_await dareq-sz Device 0.00 0.0k 0.00 0.0% 0.00 0.0k nvme0n2 0.00 0.0k 0.00 0.0% 0.00 0.0k nvme0n3
Anàlis del rendiment
En aquest apartat, es demana elaborar un informe tècnic que respongui a les següents preguntes:
-
En aquest apartat es demana que analitzeu diferents workloads i analitzeu el rendiment de cada volum lògic durant les operacions de lectura i escriptura. Per fer-ho, utilitzarem l'eina
fioper simular diferents càrregues de treball. Per instal·larfioexecuteudnf install fio -y. Un cop instal·lat, creareu una carpeta per guardar els workloads;mkdir /tmp/workloads.-
Workload 1:
echo " [global] direct=1 ioengine=libaio bs=4k iodepth=16 runtime=60 size=5g filename=testfile [read-seq] rw=read stonewall" > /tmp/workloads/read-seq-4k.fio -
Workload 2:
echo " [global] direct=1 ioengine=libaio bs=128k iodepth=16 runtime=60 size=5g filename=testfile [read-random] rw=randread stonewall" > /tmp/workloads/read-rand-128k.fioPer executar el workload:
# Linear fio /tmp/workloads/read-seq.fio --filename=/mnt/linear/testfile fio /tmp/workloads/read-rand.fio --filename=/mnt/linear/testfile # Striped fio /tmp/workloads/read-seq.fio --filename=/mnt/striped/testfile fio /tmp/workloads/read-rand.fio --filename=/mnt/striped/testfileCentreu-vos en els valors IOPS, BW i temps de finalització del workload. Analitzeu els resultats de forma argumentada. Comentant l'impacte de la mida del bloc bs i operacions de lectura seqüencial i aleatòria. Es recomanable, generar el workload 3 i 4 amb la resta de opcions per veure els efectes.
-
-
Assumint els workloads anteriors dissenyeu un experiment utiltizant per generar una gràfica que mostri el rendiment del volum striped configurat amb diferents valors
stripsize(64K, 128K, 256K, 512K, 1M i 2M).
Neteja
Un cop finalitzat el laboratori, eliminarem tots els recursos creats:
-
Eliminar les dades crades:
rm -rf /mnt/striped /mnt/linear -
Desmontar els volums lògics:
umount /mnt/striped /mnt/linear -
Eliminar els volums lògics:
lvremove /dev/vg0/lv_striped /dev/vg0/lv_linear -
Eliminar el grup de volums:
vgremove vg0 -
Eliminar els volums físics:
pvremove /dev/nvme0n2 /dev/nvme0n3 -
Elimineu la màquina virtual i tots els recursos associats.
Desplegament d'una web amb LVM
En aquesta part de laboratori, ens centrarem en el desplegament d'una aplicació web amb LVM. Utilitzarem LVM per a gestionar tots els fitxers necessaris per al funcionament de la web, com ara el codi font, les dades, els logs i la informació dels processos i sockets utilitzat en el seu desplegament. La nostra web proporcionarà accés a informació sobre indicadors socials, econòmics i demogràfics de diferents regions del món, presentada a través d’un mapa interactiu.
- El codi font és un projecte fet amb Django que es desplegarà en el directori
/opt/webapp/source. - Les dades són documents, fotos, i htmls amb informació precomputada que és els usuaris de la web podran visualitzar i descarregar. Aquestes dades es guardaran en el directori
/opt/webapp/datai també es guarden els logs de la web. - La informació dels processos i del socket es guarda a
/opt/webapp/run.
Objectius
- Compendre com utilitzar LVM per a gestionar els volums lògics.
- Aprendre a gestionar els components de LVM com ara els volums físics, els grups de volums i els volums lògics.
- Simular un cas real d'ús de LVM en un servidor web.
Preparació
-
Inicialitzeu una nova màquina virtual amb un disc dur de 20 GB i instal·leu AlmaLinux. Utilitzeu l'instal·lador per configurar el sistema amb lvm, podeu utilitzar la configuració per defecte, o bé personalitzar-la segons les vostres necessitats. Podeu utilitzar la màquina virtual de l'apartat anterior o no.
-
Adjunteu dos disc dur addicionals de 20 GB a la màquina virtual.
-
Assegureu-vos que l'estat inicial del sistema és correcte. Utiltizeu la comanda
lsblkper comprovar que teniu aquest estat inicial:NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT nvme0n1 259:0 0 20G 0 disk ├─nvme0n1p1 259:1 0 600MB 0 part /boot/efi ├─nvme0n1p2 259:2 0 1G 0 part /boot ├─nvme0n1p3 259:3 0 2G 0 part [SWAP] └─nvme0n1p4 259:4 0 16.4G 0 part / nvme0n2 259:5 0 20G 0 disk nvme0n3 259:6 0 20G 0 disk- Nota 1: El nom del dispositiu pot variar segons les vostres opcions de virtualització.
- Nota 2: En aquest cas, s'ha creat una MV nova amb 2 discos durs de 20GB cadascun.
Tasques
Configuració dels volums lògics
-
Creeu els volums físics amb
pvcreate:pvcreate /dev/nvme0n2 /dev/nvme0n3 -
Analitzeu els volums físics amb
pvdisplay:pvdisplaySi observeu la sortida de la comanda:
"/dev/nvme0n2" is a new physical volume of "20.00 GiB" --- NEW Physical volume --- PV Name /dev/nvme0n2 VG Name PV Size 20.00 GiB Allocatable NO PE Size 0 Total PE 0 Free PE 0 Allocated PE 0 PV UUID D27Ox6-pKi4-1OsC-sUPE-og9f-Auvp-LB1wL1 "/dev/nvme0n3" is a new physical volume of "20.00 GiB" --- NEW Physical volume --- PV Name /dev/nvme0n3 VG Name PV Size 20.00 GiB Allocatable NO PE Size 0 Total PE 0 Free PE 0 Allocated PE 0 PV UUID Arr5nq-3c89-mcw9-shxM-L27z-w2FW-fxjCD6Podeu veure com s'han creat dos volums físics de 20GB cadascun. De moment, com que no s'ha creat cap grup de volums, el camp
Allocatableestà aNO. -
Creeu un grup de volums anomenat
vg_webappamb els discs secundaris:vgcreate vg_webapp /dev/nvme0n2 /dev/nvme0n3 -
Analitzeu l'estat amb
vgdisplayipvdisplay:--- Physical volume --- PV Name /dev/nvme0n2 VG Name vg_webapp PV Size 20.00 GiB / not usable 4.00 MiB Allocatable yes PE Size 4.00 MiB Total PE 5119 Free PE 5119 Allocated PE 0 PV UUID D27Ox6-pKi4-1OsC-sUPE-og9f-Auvp-LB1wL1 --- Physical volume --- PV Name /dev/nvme0n3 VG Name vg_webapp PV Size 20.00 GiB / not usable 4.00 MiB Allocatable yes PE Size 4.00 MiB Total PE 5119 Free PE 5119 Allocated PE 0 PV UUID Arr5nq-3c89-mcw9-shxM-L27z-w2FW-fxjCD6Amb el volum físic creat, ara el camp
Allocatableestà aYES. A més a més, podem observar com la mida dels extents és de 4MiB i el nombre total d'extents és de 5119. Aquest valors surt de dividir la mida del volum físic entre la mida de l'extens \( \frac{20 * 1024 MiB}{4 MiB} \). A més a més, observem que tots els extents estan lliures.Ara, si analitzem el grup de volums:
--- Volume group --- VG Name vg_webapp System ID Format lvm2 Metadata Areas 2 Metadata Sequence No 1 VG Access read/write VG Status resizable MAX LV 0 Cur LV 0 Open LV 0 Max PV 0 Cur PV 2 Act PV 2 VG Size 39.99 GiB PE Size 4.00 MiB Total PE 10238 Alloc PE / Size 0 / 0 Free PE / Size 10238 / 39.99 GiB VG UUID NAyZgb-ceve-Fsfa-YrLX-l9eg-rg4W-2Ur02HPodem veure com el grup de volums
vg_webappté un total de 39.99 GiB i tots els extents estan lliures. A més a més, observem que tenim permisos de lectura i escriptura i que el grup de volums és resizable. -
Creeu els volums lògics necessaris per a la configuració del nostre servei web:
-
Guardar el codi font de la web:
lvcreate -L 1G -n lv_sources vg_webapp -
Guardar les dades estatístiques de la web:
lvcreate -L 10G -n lv_data vg_webapp -
Guardar la informació de run-time de la web:
lvcreate -L 1G -n lv_run vg_webapp
-
-
Analitzeu un altre cop l'estat amb les comandes
vgdisplayilvdisplay:--- Volume group --- VG Name vg_webapp System ID Format lvm2 Metadata Areas 2 Metadata Sequence No 4 VG Access read/write VG Status resizable MAX LV 0 Cur LV 3 Open LV 0 Max PV 0 Cur PV 2 Act PV 2 VG Size 39.99 GiB PE Size 4.00 MiB Total PE 10238 Alloc PE / Size 3072 / 12.00 GiB Free PE / Size 7166 / 27.99 GiB VG UUID NAyZgb-ceve-Fsfa-YrLX-l9eg-rg4W-2Ur02HLa principal diferència és que ara tenim 3 volums lògics creats i que s'han reservat 3072 extents per a 12 GiB. Aquestes 12 GiB corresponen a la suma dels tres volums lògics (1GB + 10GB + 1GB). Cada volum lògic té un total de 1024 extents. Per tant, el total de extents reservats és de 3072.
Un altre punt interesant són els atributs Metadata Areas i Metadata Sequence No. Metadata Areas ens indica el nombre de discos on es guarda la informació de LVM. En aquest cas, tenim 2 discos. Metadata Sequence No ens indica el nombre de vegades que s'ha modificat el grup de volums. Abans de crear els volums lògics, el grup de volums tenia un Metadata Sequence No de 1 i Metadata Areas de 2. Després de crear els volums lògics, el Metadata Sequence No ha canviat a 4 i el Metadata Areas segueix sent 2.
--- Logical volume --- LV Path /dev/vg_webapp/lv_sources LV Name lv_sources VG Name vg_webapp LV UUID WmJB46-zWcR-xPt3-cD8K-fxeT-KFya-WGEa6e LV Write Access read/write LV Creation host, time localhost.localdomain, 2024-07-12 14:09:53 +0200 LV Status available # open 0 LV Size 1.00 GiB Current LE 256 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 253:2 --- Logical volume --- LV Path /dev/vg_webapp/lv_data LV Name lv_data VG Name vg_webapp LV UUID VfILMu-Pd5N-P0Pt-MLd0-Edur-qIdv-hZcaYs LV Write Access read/write LV Creation host, time localhost.localdomain, 2024-07-12 14:10:13 +0200 LV Status available # open 0 LV Size 10.00 GiB Current LE 2560 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 253:3 --- Logical volume --- LV Path /dev/vg_webapp/lv_run LV Name lv_run VG Name vg_webapp LV UUID BJAdkW-nUGT-zT9f-5wIV-Ya6R-Cr4n-aYX394 LV Write Access read/write LV Creation host, time localhost.localdomain, 2024-07-12 14:10:22 +0200 LV Status available # open 0 LV Size 1.00 GiB Current LE 256 Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 253:4Podem veure com cada volum lògic té un tamany de 1 GiB, 10 GiB i 1 GiB respectivament. A més a més, cada volum lògic té un total de 256 extents. Això és degut a que la mida de l'extens és de 4 MiB i el tamany de cada volum lògic és de 1 GiB. Per tant, el nombre d'extents necessaris per a cada volum lògic és de \( \frac{1024}{4} = 256 \) i en el cas del volum lògic de 10 GiB és de \( \frac{10240}{4} = 2560 \) extents.
Un altre punt interessant és el Block device. Aquesta informació ens indica el dispositiu de bloc associat a cada volum lògic. En aquest cas, tenim els dispositius de bloc 253:2, 253:3 i 253:4 per als volums lògics lv_sources, lv_data i lv_run respectivament.
-
Formateu els volums lògics amb el sistema de fitxers:
-
Volum lògic de la web:
mkfs.xfs /dev/vg_webapp/lv_sources -
Volum lògic de les dades:
mkfs.ext4 /dev/vg_webapp/lv_data -
Volum lògic de run-time:
mkfs.xfs /dev/vg_webapp/lv_run
-
-
Munteu els volums lògics en els directoris corresponents:
-
Crearem un directori a
/optper muntar el volum lògic de la web:mkdir /opt/webapp -
Volum lògic de la web:
mkdir /opt/webapp/sources mount /dev/vg_webapp/lv_sources /opt/webapp/sources -
Volum lògic de les dades:
mkdir /opt/webapp/data mount /dev/vg_webapp/lv_data /opt/webapp/data -
Volum lògic de run-time:
mkdir /opt/webapp/run mount /dev/vg_webapp/lv_run /opt/webapp/run
Recordeu: Els volums es muntaran de forma temporal al servidor. Per a muntar-los de forma permanent, heu d'afegir les entrades corresponents al fitxer
/etc/fstab. -
-
Analitzeu l'estat del servidor:
[root@localhost ~]# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sr0 11:0 1 1.7G 0 rom nvme0n1 259:0 0 20G 0 disk ├─nvme0n1p1 259:1 0 600M 0 part /boot/efi ├─nvme0n1p2 259:2 0 1G 0 part /boot └─nvme0n1p3 259:3 0 18.4G 0 part ├─almalinux-root 253:0 0 16.4G 0 lvm / └─almalinux-swap 253:1 0 2G 0 lvm [SWAP] nvme0n2 259:4 0 20G 0 disk ├─vg_webapp-lv_sources 253:2 0 1G 0 lvm /opt/webapp/sources ├─vg_webapp-lv_data 253:3 0 10G 0 lvm /opt/webapp/data └─vg_webapp-lv_run 253:4 0 1G 0 lvm /opt/webapp/run nvme0n3 259:5 0 20G 0 diskPodem veure com s'han muntat els volums lògics en els directoris corresponents. El volum lògic de la web s'ha muntat a
/opt/webapp/sources, el volum lògic de les dades s'ha muntat a/opt/webapp/datai el volum lògic de run-time s'ha muntat a/opt/webapp/run. A més a més, com estem utiltizant un LVM lineal, podem veure com únicament utilitzem un disc dur per a guardar les dades. Ja que encara no hem superat la seva capacitat.
Actualització dels volums lògics
En aquest punt, ens hem adonat que les dades de la web són superior a 10GB. Però tenim 28GB disponibles al nostre volum lògic de dades. Per tant, volem augmentar el tamany del volum lògic de les dades a 20GB. Ho podeu veure amb la comanda vgs:
VG #PV #LV #SN Attr VSize VFree
almalinux 1 2 0 wz--n- 18.41g 0
vg_webapp 2 3 0 wz--n- 39.99g 27.99g
-
Augmenteu el tamany del volum lògic de les dades a 20GB.
lvextend -L +10G /dev/vg_webapp/lv_data -
Redimensioneu el sistema de fitxers:
resize2fs /dev/vg_webapp/lv_dataNota: Aquest pas es essecnial, ja que si no redimensionem el sistema de fitxers, el sistema operatiu no podrà accedir a l'espai addicional i no podrà utilitzar-lo. Per a
xfsutilitzariam la comandaxfs_growfs. -
Analitzeu l'estat del servidor:
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sr0 11:0 1 1.7G 0 rom nvme0n1 259:0 0 20G 0 disk ├─nvme0n1p1 259:1 0 600M 0 part /boot/efi ├─nvme0n1p2 259:2 0 1G 0 part /boot └─nvme0n1p3 259:3 0 18.4G 0 part ├─almalinux-root 253:0 0 16.4G 0 lvm / └─almalinux-swap 253:1 0 2G 0 lvm [SWAP] nvme0n2 259:4 0 20G 0 disk ├─vg_webapp-lv_sources 253:2 0 1G 0 lvm /opt/webapp/sources ├─vg_webapp-lv_data 253:3 0 20G 0 lvm /opt/webapp/data └─vg_webapp-lv_run 253:4 0 1G 0 lvm /opt/webapp/run nvme0n3 259:5 0 20G 0 disk └─vg_webapp-lv_data 253:3 0 20G 0 lvm /opt/webapp/dataObserveu com ara el volum lògic de les dades té un tamany de 20GB i el disc dur
nvme0n2no té sufiticient espai per a guardar les dades. Per tant, es necessita utilitzar part del disc durnvme0n3invme0n2per gestionar la partició de les dades.
Després d'un temps, utilitzant la web, ens hem adonat que la partició lv_runesta sobredimensionada i únicament s'utilitza un 10% del seu espai. Per tant, volem reduir el tamany de la partició lv_run a 500MB. Alliberant així 500MB per a altres particions.
-
Reduïu el tamany del volum lògic de run-time a 500MB:
lvreduce -L 500M /dev/vg_webapp/lv_runObserveu que LVM no us permetrà realitzar aquesta acció. El sistema de fitxers
xfsté una mida de 1GB i no permet reduir el tamany del volum lògic.File system xfs found on vg_webapp/lv_run mounted at /opt/webapp/run. File system size (1.00 GiB) is larger than the requested size (500.00 MiB). File system reduce is required and not supported (xfs). -
Redimensioneu el sistema de fitxers
xfsa 500MB:El principal problema és que el sistema de fitxers
xfsno permet reduir el tamany. La manera de dur a terme aquesta reducció seria: a. Muntar un disc dur addicional, b. Copiar les dades a aquest disc dur, c. Desmuntar el volum lògic, d. Eliminar el volum lògic, e. Crear un nou volum lògic de 500MB, f. Formateu el volum lògic amb el sistema de fitxersxfs, g. Munteu el volum lògic en el directori corresponent i h. Copiar les dades al nou volum lògic.Com en aquest cas no tenim dades, podem fer el següent:
-
Desmuntar el volum lògic:
umount /opt/webapp/run -
Eliminar el volum lògic:
lvremove /dev/vg_webapp/lv_run -
Crear un nou volum lògic de 500MB:
lvcreate -L 500M -n lv_run vg_webappEn aquest punt, el sistema detectarà que hi ha un sistema de fitxers
xfsal volum lògic i us preguntarà si voleu eliminar-lo. Respongueuyper a eliminar el sistema de fitxersxfs. Això és deu a quelvremoveno elimina el sistema de fitxers, únicament el volum lògic.WARNING: xfs signature detected on /dev/vg_webapp/lv_run at offset 0. Wipe it? [y/n]: y Wiping xfs signature on /dev/vg_webapp/lv_run. Logical volume "lv_run" created. -
Formateu el volum lògic amb el sistema de fitxers
xfs:mkfs.xfs -f /dev/vg_webapp/lv_run -
Munteu el volum lògic en el directori corresponent:
mount /dev/vg_webapp/lv_run /opt/webapp/run -
Nota 1: Aquest pas sempre és mes complex. Per tant, la meva recomanació és intentar assignar espai a la baixa, ja que incrementar l'espai és més fàcil que reduir-lo.
-
Nota 2: Altres sistemes de fitxers com
ext4permeten reduir el tamany del volum lògic sense problemes, simplificant així aquest procés.
-
-
Analitzeu l'estat del servidor amb
lvs:LV VG Attr LSize root almalinux -wi-ao---- 16.41g swap almalinux -wi-ao---- 2.00g lv_data vg_webapp -wi-ao---- 20.00g lv_run vg_webapp -wi-ao---- 500.00m lv_sources vg_webapp -wi-ao---- 1.00gPodem observar com s'ha reduït el tamany del volum lògic de run a 500MB.
Anàlisi del sistema
Es demana que analitzeu la següent aplicació web i indiqueu si la configuració de lvm és òptima. Justifiqueu la vostra resposta. La aplicació web és un blog amb les següents característiques:
- La pàgina rep 1000 visites diàries.
- La pàgina conté documents que s’acostumen a consultar de forma massiva i simultània.
- Es generen 1 GB de logs cada dia.
- Es generen 5 GB de dades estátiques noves cada mes.
Podeu assumir que cada mes es volquen tots els logs en una base de dades externa i que s’allibera l’espai dels logs.
Gestió de fallades
En aquest apartat, assumirem que el disc dur secundari /dev/nvme0n3 ha fallat. Aquest disc forma part del grup de volums vg_webapp i conté el volum lògic lv_data que emmagatzema les dades estàtiques de la web. La fallada del disc dur pot ser deguda a diversos factors, com ara errors de hardware, errors de software, o errors de configuració.
Preparació
-
Utilitzeu la màquina virtual creada a l'apartat anterior amb el grup de volums
vg_webappi el volum lògiclv_data. -
Escriviu dades aleatòries a l’arxiu
/opt/webapp/dataper simular les dades del lloc web. Podeu utilitzar l’script següent:#!/bin/bash # Numero de gigabytes a escriure amountGB="$1" # Directori on escriure els arxius (per defecte /opt/webapp/data) dir="${2:-/opt/webapp/data}" for i in $(seq 1 "$amountGB"); do dd if=/dev/urandom of="$dir/file$i" bs=1M count=1024 done echo "S'han escrit $amountGB GB de dades a $dir"Executeu el script amb la següent comanda per escriure 5GB de dades a l'arxiu
/opt/webapp/data:bash script.sh 5
Tasques
Anàlisi de la fallada
En primer lloc, analitzarem amb més detall utiltizant pvdisplay --maps i lvdisplay --maps per entendre com estan distribuïts els extens del grup de volums i del volum lògic.
--- Physical volume ---
PV Name /dev/nvme0n2
VG Name vg_webapp
PV Size 20.00 GiB / not usable 4.00 MiB
Allocatable yes (but full)
PE Size 4.00 MiB
Total PE 5119
Free PE 0
Allocated PE 5119
PV UUID 7saOpX-fjg1-afmU-ZoEA-d945-mJzN-6oo0Tl
--- Physical Segments ---
Physical extent 0 to 255:
Logical volume /dev/vg_webapp/lv_sources
Logical extents 0 to 255
Physical extent 256 to 2815:
Logical volume /dev/vg_webapp/lv_data
Logical extents 0 to 2559
Physical extent 2816 to 3071:
Logical volume /dev/vg_webapp/lv_run
Logical extents 0 to 255
Physical extent 3072 to 5118:
Logical volume /dev/vg_webapp/lv_data
Logical extents 2560 to 4606
--- Physical volume ---
PV Name /dev/nvme0n3
VG Name vg_webapp
PV Size 20.00 GiB / not usable 4.00 MiB
Allocatable yes
PE Size 4.00 MiB
Total PE 5119
Free PE 4606
Allocated PE 513
PV UUID 4Exs4j-Japi-ab8p-pnYx-FPNY-tKdl-KTFkHq
--- Physical Segments ---
Physical extent 0 to 512:
Logical volume /dev/vg_webapp/lv_data
Logical extents 4607 to 5119
Physical extent 513 to 5118:
FREE
```
```bash
--- Logical volume ---
LV Path /dev/vg_webapp/lv_sources
LV Name lv_sources
VG Name vg_webapp
LV UUID ElTnFj-nVJT-OwhB-dTmm-l1zR-LNht-Zk8QY1
LV Write Access read/write
LV Creation host, time localhost.localdomain, 2024-07-12 20:42:20 +0200
LV Status available
# open 1
LV Size 1.00 GiB
Current LE 256
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:2
--- Segments ---
Logical extents 0 to 255:
Type linear
Physical volume /dev/nvme0n2
Physical extents 0 to 255
--- Logical volume ---
LV Path /dev/vg_webapp/lv_data
LV Name lv_data
VG Name vg_webapp
LV UUID Oliogr-YoKj-OeKh-V3jE-bcbe-i25B-fowxdT
LV Write Access read/write
LV Creation host, time localhost.localdomain, 2024-07-12 20:42:25 +0200
LV Status available
# open 1
LV Size 20.00 GiB
Current LE 5120
Segments 3
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:3
--- Segments ---
Logical extents 0 to 2559:
Type linear
Physical volume /dev/nvme0n2
Physical extents 256 to 2815
Logical extents 2560 to 4606:
Type linear
Physical volume /dev/nvme0n2
Physical extents 3072 to 5118
Logical extents 4607 to 5119:
Type linear
Physical volume /dev/nvme0n3
Physical extents 0 to 512
--- Logical volume ---
LV Path /dev/vg_webapp/lv_run
LV Name lv_run
VG Name vg_webapp
LV UUID YGKTJ2-HwMi-k9CG-uyM1-wyG5-t0Vh-vGiptU
LV Write Access read/write
LV Creation host, time localhost.localdomain, 2024-07-12 20:42:30 +0200
LV Status available
# open 1
LV Size 1.00 GiB
Current LE 256
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:4
--- Segments ---
Logical extents 0 to 255:
Type linear
Physical volume /dev/nvme0n2
Physical extents 2816 to 3071
Si analitzem les dades anteriors, podem veure que el volum lògic lv_data està distribuït entre els discs durs /dev/nvme0n2 i /dev/nvme0n3. Això significa que si el disc dur /dev/nvme0n3 falla, les dades emmagatzemades en aquest disc dur es perdran. Si us centreu en /dev/vg_webapp/lv_data veureu que els LEs 0-2559 i 2560-4606 estan en el disc dur /dev/nvme0n2 i equivalenen als PE 256-2815 i 3072-5118. Mentre que els LEs 4607-5119 estan en el disc dur /dev/nvme0n3 i equivalen als PE 0-512. Si fem les operacions assumint que la mida dels PE és de 4MiB i que la mida del volum lògic és de 20GB, podem veure que el disc dur /dev/nvme0n2 conté 18GB i el disc dur /dev/nvme0n3 conté 2GB. La traducció es pot fer utilitzant les següents operacions: $18GB = 4606 * 4MiB$ i $2GB = 512 * 4MiB$.
Simulació de la fallada
-
Hi ha moltes maneres de simular una fallada de disc, una d'elles es corrompre la secció de metadades lvm del disc
/dev/nvme0n3. Per fer-ho, podeu utilitzar la comandaddper sobreescriure els primeres 10MB del disc dur amb zeros:dd if=/dev/zero of=/dev/nvme0n3 bs=1M count=10Alternativament, podeu utilitzar la comanda
wipefsper eliminar les signatures del disc dur/dev/nvme0n3:wipefs --all --backup -f /dev/nvme0n3 -
Un cop hàgiu simulat la fallada del disc dur
/dev/nvme0n3, comproveu l'estat del grup de volumsvg_webappi del volum lògiclv_data:vgdisplay vg_webapp lvdisplay /dev/vg_webapp/lv_dataDevice /dev/nvme0n3 has no PVID (devices file 4Exs4jJapiab8ppnYxFPNYtKdlKTFkHq) WARNING: Couldn't find device with uuid 4Exs4j-Japi-ab8p-pnYx-FPNY-tKdl-KTFkHq. WARNING: VG vg_webapp is missing PV 4Exs4j-Japi-ab8p-pnYx-FPNY-tKdl-KTFkHq (last written to /dev/nvme0n3). WARNING: Couldn't find all devices for LV vg_webapp/lv_data while checking used and assumed devices.A partir de la sortida anterior, podem veure que el disc dur
/dev/nvme0n3ha fallat i que el grup de volumsvg_webappi el volum lògiclv_datatenen problemes.Si utilitzeu
ls -la /opt/webapp/dataodf -hobservareu que encara podeu accedir a les dades. Recordeu que les primeres 18GB estan emmagatzemades al disc dur/dev/nvme0n2. Amb la comanadapvdisplay --mapsilvdisplay --mapspodeu comprovar-ho veient que únicament els LEs corresponents al disc dur/dev/nvme0n3estan marcats com a unknown. -
Ara anem a omplir el disc dur
/dev/nvme0n2per simular una fallada imminent. Per fer-ho, podeu utilitzar la comandaddper escriure 19GB de dades aleatòries a l'arxiu/opt/webapp/data:bash script.sh 19Com ha pogut guardar 19GB si el disc dur
/dev/nvme0n3ha fallat i el disc dur/dev/nvme0n2només té 18GB? Això és degut a que les dades s'estan guardant en el disc dur/dev/nvme0n2però no s'estan actualitzant les metadades de LVM. Això pot ser un problema greu, ja que si el disc dur/dev/nvme0n2falla, les dades es perdran.Aquest fet el podeu posar de manifest intentant guardar dades al següent LE del disc dur
/dev/nvme0n2i veureu que no es pot fer. Ja que el 1GB que ell tenia reservat s'ha omplert amb el 1GB restant de la còpia anterior.bash script.sh 1 /opt/webapp/rundd: error writing '/opt/webapp/run/file1': No space left on device
Solucionant la fallada
Per solucionar la fallada del disc dur /dev/nvme0n3, seguirem els següents passos:
-
Utilitzeu l'eina
pvckper comprovar la integritat del disc dur/dev/nvme0n3:pvck /dev/nvme0n3WARNING: Device for PV 4Exs4j-Japi-ab8p-pnYx-FPNY-tKdl-KTFkHq not found or rejected by a filter.A partir de la sortida anterior, podem veure que el disc dur
/dev/nvme0n3no es pot trobar. Això és degut a que hem corromput les metadades de LVM del disc dur/dev/nvme0n3. -
Utilitzeu l'eina
pvckamb l'opció--repairper intentar reparar el disc dur/dev/nvme0n3:pvck --repair -f /etc/lvm/backup/vg_webapp /dev/nvme0n3CHECK: label_header.crc expected 0x5bd06dba CHECK: label_header.type expected LVM2 001 WARNING: No LVM label found on /dev/nvme0n3. It may not be an LVM device. Writing label_header.crc 0xc9fb4741 pv_header uuid Tqyb8i0hyzOyb2AFlgMQJ4bNW6kDiOsJ device_size 21474836480 Writing data_offset 1048576 mda1_offset 4096 mda1_size 1044480 mda2_offset 0 mda2_size 0 Write new LVM header to /dev/nvme0n3? y Writing metadata at 4608 length 2190 crc 0x38751a64 mda1 Writing mda_header at 4096 mda1 Write new LVM metadata to /dev/nvme0n3? yEn aquest punt, hem intentat reparar el disc dur
/dev/nvme0n3i hem escrit noves metadades de LVM al disc dur. El problema és que les noves metadades de LVM no coincideixen amb les metadades de LVM del grup de volumsvg_webapp. Ho podeu comprovar amb la comandapvs -o+uuid:pvs -o+uuid WARNING: scan of VG vg_webapp from /dev/nvme0n3 mda1 found mda_checksum 38751a64 mda_size 2190 vs d5280ec2 2174 WARNING: Scanning /dev/nvme0n3 mda1 found mismatch with other metadata. WARNING: scan failed to get metadata summary from /dev/nvme0n3 PVID Tqyb8i0hyzOyb2AFlgMQJ4bNW6kDiOsJ Device /dev/nvme0n3 has PVID Tqyb8i0hyzOyb2AFlgMQJ4bNW6kDiOsJ (devices file none) WARNING: scan of VG vg_webapp from /dev/nvme0n3 mda1 found mda_checksum 38751a64 mda_size 2190 vs d5280ec2 2174 WARNING: Scanning /dev/nvme0n3 mda1 found mismatch with other metadata. WARNING: scan failed to get metadata summary from /dev/nvme0n3 PVID Tqyb8i0hyzOyb2AFlgMQJ4bNW6kDiOsJ PV VG Fmt Attr PSize PFree PV UUID /dev/nvme0n1p3 almalinux lvm2 a-- 18.41g 0 59JST0-TYqg-3nyz-p4ek-MaEk-pJX6-cgGf96 /dev/nvme0n2 vg_webapp lvm2 a-- <20.00g 17.99g 7saOpX-fjg1-afmU-ZoEA-d945-mJzN-6oo0Tl /dev/nvme0n3 vg_webapp lvm2 a-- <20.00g 0 Tqyb8i-0hyz-Oyb2-AFlg-MQJ4-bNW6-kDiOsJ -
Actualitzeu les metadades del grup de volums
vg_webapp:vgcfgrestore vg_webappEn aquest punt encara observareu WARNINGS, per mismatch de les metadades. Igual es pot omitir.
-
Actualitzeu les metadades del grup de volums
vg_webapp:vgck --updatemetadata vg_webappAmb aquesta comanda actualitzarem les metadades del grup de volums
vg_webappamb les noves metadades del disc dur/dev/nvme0n3. Ara ja no hauríeu de veure cap warning en la sortida depvs -o+uuid.
Canviant el disc
-
Ara que hem reparat el grup de volums
vg_webapp, procedirem a canviar el disc dur/dev/nvme0n3per un de nou. En aquest cas, assumirem que el nou disc dur és/dev/nvme0n4. -
Utilitzeu la comanda
pvcreateper inicialitzar el disc dur/dev/nvme0n4:pvcreate /dev/nvme0n4 -
Utilitzeu la comanda
vgextendper afegir el disc dur/dev/nvme0n4al grup de volumsvg_webapp:vgextend vg_webapp /dev/nvme0n4 -
Utilitzeu pvmove per moure les dades del disc dur
/dev/nvme0n3al disc dur/dev/nvme0n4:pvmove /dev/nvme0n3 /dev/nvme0n4Aquesta comanda mou les dades del disc dur
/dev/nvme0n3al disc dur/dev/nvme0n4. Aquest procés pot trigar una estona depenent de la quantitat de dades a moure. -
Utilitzeu la comanda
vgreduceper eliminar el disc dur/dev/nvme0n3del grup de volumsvg_webapp:vgreduce vg_webapp /dev/nvme0n3 -
Utilitzeu la comanda
pvremoveper eliminar el disc dur/dev/nvme0n3del grup de volumsvg_webapp:pvremove /dev/nvme0n3
Anàlisi de la situació
Creus que hi ha alguna manera de recuperar les dades del disc dur /dev/nvme0n3? Si la corrupció es fa a nivell de LEs en comptes de metadades. Investigar quines eines podrien ser útils per recuperar les dades del disc dur /dev/nvme0n3.
Snapshots
En la nostra infraestructura, la seguretat de les dades és un aspecte fonamental. Per això, és crucial disposar de mecanismes que ens permetin recuperar la informació en cas de pèrdua o corrupció. Un d’aquests mecanismes són les instantànies (snapshots), que ens permeten fer còpies de seguretat dels nostres volums lògics en un moment determinat sense interrompre el servei. Aquesta funcionalitat és possible gràcies a la tècnica de COW (copy-on-write) de LVM, que clona les dades originals abans de ser modificades.
Un cas d'ús comú, per exemple, en el nostre servei web, seria per realitzar una còpia de seguretat de la carpeta de dades abans de realitzar un canvi important. Una opció seria comprimir tots els fitxers de /opt/web/data en un arxiu tar i desar-lo en un directori de backup. No obstant això, com la web està en funcionament, els fitxers poden canviar durant el procés de compressió, cosa que podria provocar un error de 'file was changed as we read it'. Per evitar aquest problema, podem utilitzar snapshots per fer una còpia de seguretat dels fitxers en un moment determinat, sense interrompre el servei.
- Creació de snapshots: Crearem un snapshot del volum lògic
/dev/vg_webapp/lv_dataper fer una còpia de seguretat dels fitxers de la carpeta/opt/webapp/data. - Crearem una còpia de la informació: Crearem una còpia de la informació llegint l'snapshot que hem creat, mentre el volum lògic original està en funcionament i els usuaris continuen treballant.
- Mourem la còpia de seguretat: Mourem la còpia de seguretat a un altre servidor o sistema de backup.
- Neteja: Un cop hem acabat la còpia de seguretat, eliminarem l'snapshot.
Preparació
-
Utilitzeu la màquina virtual creada en els apartats anteriors.
-
Assegureu-vos que teniu el volum lògic
/dev/vg_webapp/lv_datacreat i muntat en el directori/opt/webapp/data. -
Elimineu els fitxers de prova de la carpeta
/opt/webapp/data:rm -rf /opt/webapp/data -
Creeu dades de prova en el directori
/opt/webapp/data:echo "Hello, World1!" > /opt/webapp/data/file1.txt echo "Hello, World2!" > /opt/webapp/data/file2.txt echo "Hello, World3!" > /opt/webapp/data/file3.txt
Tasques
Creació d'snapshots
El primer pas per realitzar una còpia de seguretat dels nostres fitxers, creant un snapshot del volum lògic /dev/vg_webapp/lv_data.
-
Creeu un snapshot del volum lògic
/dev/vg_webapp/lv_data:lvcreate -L 1G -s -n snap_data /dev/vg_webapp/lv_dataNota: La mida d'un snapshot hauria de ser suficient per guardar els fitxers actuals del volum lògic. Per tant, és important ajustar la mida de l'snapshot segons les necessitats del nostre sistema. En aquest laboratori, assumirem que 1GB és suficient per a les nostres dades.
Si tot ha anat bé, hauríeu de veure un missatge com aquest:
Logical volume "snap_data" created. -
Comproveu que l'snapshot s'ha creat correctament:
lvsAquesta comanda us mostrarà informació rellevant sobre l'snapshot:
LV VG Attr LSize Pool Origin Data% snap_data vg_webapp swi-a-s--- 1.00g lv_data 0.01On
snap_dataés el nom de l'snapshot,vg_webappés el grup de volums,swi-a-s---són els atributs de l'snapshot:- (s): és un snapshot
- (w): té permisos d'escriptura
- (i): indica que és un volum lògic heretat, és a dir, que depèn d'un altre volum lògic.
- (a): indica que el volum lògic està actiu
Si us fixeu, entre
a-sindica que el dispositiu (snapshot) no ha estat obert, ja que no està muntat. Ho podeu comprovar amb el volum lògic original/dev/vg_webapp/lv_dataque està muntat.La columna
Dataindica el percentatge de dades que conté l'snapshot.1.00gés la mida de l'snapshot,lv_dataés el volum lògic original,0.01és el percentatge de dades que conté l'snapshot. -
Creeu un punt de muntatge per a l'snapshot:
mkdir /snaps -
Munteu l'snapshot en el directori
/snaps:mount /dev/vg_webapp/snap_data /snaps -
Comproveu amb
lvscom ara l'snapshot està muntada:swi-aos---.lvs -
Compareu el contingut del directori
/opt/webapp/dataamb el de l'snapshot:diff -r /opt/webapp/data /snapsEn aquest punt, els dos directoris haurien de ser idèntics. Per tant, no s'hauria de mostrar cap sortida.
-
Reviseu els atributs de la carpeta
/snapsi/opt/webapp/datamostrant informació dels inodes:ls -li /opt/webapp/data /snaps/Cal destacar que un snapshot conté enllaços físics als inodes reals de les dades. Això significa que, mentre les dades no canviïn, l' snapshot només contindrà referències als fitxers originals. No obstant això, si les dades del volum original es modifiquen, l'snapshot clonarà automàticament la informació abans de ser modificada, mantenint els fitxers originals a l'snapshot i les dades noves al sistema de fitxers actiu. A més, les dades que s'escriuen a l'snapshot es marquen com a utilitzades i no es copien al volum original.
/opt/webapp/data: total 12 11 -rw-r--r--. 1 root root 15 Jul 16 09:26 file1.txt 12 -rw-r--r--. 1 root root 15 Jul 16 09:26 file2.txt 13 -rw-r--r--. 1 root root 15 Jul 16 09:26 file3.txt /snaps/: total 12 11 -rw-r--r--. 1 root root 15 Jul 16 09:26 file1.txt 12 -rw-r--r--. 1 root root 15 Jul 16 09:26 file2.txt 13 -rw-r--r--. 1 root root 15 Jul 16 09:26 file3.txt -
Modifiqueu el fitxer
file3.txtamb la comandaddper escriure-hi un nou contingut (per exemple, 100MB de zeros):dd if=/dev/zero of=/opt/webapp/data/file3.txt bs=1M count=100 -
Compareu de nou el contingut del directori
/opt/webapp/dataamb el de l'snapshot:diff -r /opt/webapp/data /snapsEn aquest punt, els dos directoris haurien de ser diferents. Per tant, hauríeu de veure les diferencies amb la comanda
diff.Binary files /opt/webapp/data/file3.txt and /snaps/file3.txt differ -
Realitzeu, un nou snapshot del volum lògic
/dev/vg_webapp/lv_data, i després modifiqueu el fitxerfile2.txt:lvcreate -L 1G -s -n snap_data2 /dev/vg_webapp/lv_data && dd if=/dev/zero of=/opt/webapp/data/file2.txt bs=1M count=100 -
Desmuntem el primer snapshot:
umount /snaps -
Muntem el segon snapshot:
mount /dev/vg_webapp/snap_data2 /snaps -
Compareu de nou els atributs de la carpeta
/snaps:ls -li /opt/webapp/data /snaps//opt/webapp/data: total 204804 11 -rw-r--r--. 1 root root 15 Jul 16 17:39 file1.txt 12 -rw-r--r--. 1 root root 104857600 Jul 16 17:40 file2.txt 13 -rw-r--r--. 1 root root 104857600 Jul 16 17:40 file3.txt /snaps/: total 102408 11 -rw-r--r--. 1 root root 15 Jul 16 17:39 file1.txt 12 -rw-r--r--. 1 root root 15 Jul 16 17:39 file2.txt 13 -rw-r--r--. 1 root root 104857600 Jul 16 17:40 file3.txtFixeu-vos que el fitxer
file2.txtde l'snapshot no ha canviat, ja que les dades originals s'han clonat abans de ser modificades. En canvi, el fitxerfile2.txtdel directori/opt/webapp/dataha canviat. Tot i això, segueixen tenint el mateix inode. Això és possible gràcies a la funcionalitat de COW (copy-on-write) dels snapshots.
En aquest punt, podria'm realitzar una còpia de seguretat de la carpeta /opt/webapp/data sense interrompre el servei. Es podria utilitzar les eines cp o rsync per copiar els fitxers de l'snapshot a un altre sistema de backup.
Recuperant dades de l'snapshot
Imaginem que el fitxer file2.txt s'han incorporat canvis incorrectes i volem restaurar la versió original. Per fer-ho, utilitzarem el segon snapshot snap_data2 que hem creat anteriorment.
-
Desmuntem el volum lògic original:
umount /dev/vg_webapp/lv_dataNota: Aquest punt provocarà una interrupció del servei, ja que el volum lògic original està en ús.
-
Fusionem l'snapshot amb el volum lògic original:
lvconvert --merge /dev/vg_webapp/snap_data2Merging of volume vg_webapp/snap_data2 started. vg_webapp/lv_data: Merged: 90.73% vg_webapp/lv_data: Merged: 100.00%Nota: Aquest procés pot trigar una estona, ja que implica la fusió de les dades de la snapshot amb el volum lògic original.
-
Montem el volum lògic original:
mount /dev/vg_webapp/lv_data /opt/webapp/data -
Comproveu que el fitxer
file2.txtha estat restaurat:ls -l /opt/webapp/data
Aquesta acció ha implicat aturar el servei durant un temps, ja que hem hagut de desmuntar el volum lògic original per fusionar-lo amb l'snapshot. Aquesta és una de les limitacions dels snapshots de LVM.
Propietats dels snapshots
Fins ara, hem vist com crear i utilitzar snapshots. Ara bé, un error comú es no tenir en compte que tot i que els snapshots no són incrementals, si que són diferencials. Això vol dir que els snapshots no guarden totes les versions anteriors de les dades, sinó només les diferències amb les dades originals. Aquesta característica ens permet registrar les diferències entre les dades originals i els snapshots, però no tenir un històric dels canvis. Això es deu a la tècnica de COW (copy-on-write) que utilitza LVM per als snapshots. Aquesta tècnica clona les dades originals abans de ser modificades.Ara bé, les dades originals es clonen només si es modifiquen, i l'únic que es clona és el bloc de dades modificat.
-
Comproveu l'estat inicial del lv i de l'snapshot amb la comanda
lvs:LV VG Attr LSize Pool Origin Data% lv_data vg_webapp owi-aos--- 1.00g snap_data vg_webapp swi-a-s--- 1.00g lv_data 0.01 -
Afegiu un nou fitxer de 100MB al directori
/opt/webapp/data:dd if=/dev/zero of=/opt/webapp/data/file4.txt bs=1M count=100 oflag=dsync -
Comproveu amb
lvsl'estat del volum lògic i de l'snapshot:LV VG Attr LSize Pool Origin Data% root almalinux -wi-ao---- 16.41g swap almalinux -wi-ao---- 2.00g lv_data vg_webapp owi-aos--- 20.00g lv_run vg_webapp -wi-a----- 1.00g lv_sources vg_webapp -wi-a----- 1.00g snap_data vg_webapp swi-a-s--- 1.00g lv_data 10.00Fixeu-vos que la columna
Datade l'snapshot ha augmentat al 10%. Això indica que l'snapshot ha registrat els canvis que hem fet al volum lògic original. Però, tal com hem vist abans, aquest fitxer no es pot visualitzar si munteu l'snapshot i comproveu el seu contingut. Això és perquè els snapshots de LVM són diferencials, no incrementals. -
Per actualitzar el contingut de l'snapshot, hauriam d'eliminar-lo i crear-ne un de nou:
lvremove /dev/vg_webapp/snap_data lvcreate -L 1G -s -n snap_data /dev/vg_webapp/lv_data
Molts us preguntareu, si no puc recuperar o veure les modificacions sense crear-ne un de nou i a més l'snapshot ocupa espai per les diferencia, quin sentit té? El sentit dels snapshots és poder fer còpies de seguretat o realitzar tasques de manteniment sense afectar el rendiment del sistema, ja que només es guarden les diferències respecte les dades originals. Això permet estalviar espai i recursos en comparació amb altres mètodes de còpia de seguretat.
Escenari: El LV original creix més que l'snapshot
Imagina que el volum lògic original /dev/vg_webapp/lv_data creix més en mida que l'snapshot snap_data. Si la mida de l'snapshot no és suficient per registrar totes les modificacions del volum lògic original, l'snapshot es corromprà.
-
Creeu un fitxer de 1GB en el directori
/opt/webapp/data:dd if=/dev/zero of=/opt/webapp/data/file4 bs=1G count=1 oflag=dsyncNota: Recordeu que la mida de l'snapshot és de 1GB. El fitxer
file4fa que el volum lògic original/dev/vg_webapp/lv_datacreixi més en mida que l'snapshotsnap_data. -
Comproveu la situació amb la comanda
lvs:[root@localhost ~]# lvs LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert root almalinux -wi-ao---- 16.41g swap almalinux -wi-ao---- 2.00g lv_data vg_webapp owi-aos--- 20.00g lv_run vg_webapp -wi-a----- 1.00g lv_sources vg_webapp -wi-a----- 1.00g snap_data vg_webapp swi-I-s--- 1.00g lv_data 100.00Fixeu-vos que l'snapshot
snap_dataestà al 100% de la seva capacitat ja que no pot registrar més canvis del volum lògic original. -
Comproveu que l'snapshot es desactiva amb la comanda
lvdisplay:lvdisplay /dev/vg_webapp/snap_data--- Logical volume --- LV Path /dev/vg_webapp/snap_data LV Name snap_data VG Name vg_webapp LV UUID UxIwLW-sppS-fxAt-ojqy-dWlx-0xhY-tu0CuR LV Write Access read/write LV Creation host, time localhost.localdomain, 2024-07-16 10:21:33 +0200 LV snapshot status INACTIVE destination for lv_data LV Status available # open 0 LV Size 20.00 GiB Current LE 5120 COW-table size 1.00 GiB COW-table LE 256 Snapshot chunk size 4.00 KiB Segments 1 Allocation inherit Read ahead sectors auto - currently set to 256 Block device 253:7 -
Feu servir la comanda
dmsetupper obtenir una informació semblant:dmsetup status | grep snap_dataPer fer-ho, podem filtrar la sortida amb la comanda
grep. Recordeu quedmsetupés una eina que permet gestionar dispositius de dispositius de blocs, com ara els volums lògics de LVM.vg_webapp-snap_data: 0 41943040 snapshot Invalid vg_webapp-snap_data-cow: 0 2097152 linearEn aquesta sortida, podem veure que l'snapshot
snap_dataha canviat d'estat aInvalid. Això significa que l'snapshot ja no és vàlida i s'ha desactivat. -
Finalment, podeu comprovar els missatges del sistema amb la comanda
grep:grep Snapshot /var/log/messagesWARNING: Snapshot vg_webapp-snap_data changed state to: Invalid and should be removed.
En totes les comandes anteriors, es pot veure que l'snapshot snap_data s'ha corromput i s'ha desactivat. Per tant, elimineu-la amb la comanda lvremove:
lvremove /dev/vg_webapp/snap_data
Do you really want to remove active logical volume vg_webapp/snap_data? [y/n]: y
Creu un nou snapshot amb mida suficient per registrar les dades del volum lògic original:
lvcreate -L 2G -s -n snap_data /dev/vg_webapp/lv_data
Configuració dels snapshots
LVM ens permet configurar els snapshots perquè s'estenguin automàticament quan arribin a un determinat límit de capacitat. Per exemple, si un snapshot arriba al 70% de la seva capacitat, es pot estendre automàticament un 50% més per evitar que es corrompi. Això és útil per a sistemes on les dades canvien ràpidament i els snapshots poden quedar obsoletes ràpidament. Per fer-ho, cal modificar el fitxer de configuració de LVM /etc/lvm/lvm.conf.
-
Obriu el fitxer de configuració de LVM amb un editor de text:
vi /etc/lvm/lvm.confUtilizeu
\per buscar la secciósnapshot_autoextend_thresholdisnapshot_autoextend_percenti afegiu-hi els valors següents:snapshot_autoextend_threshold = 70 snapshot_autoextend_percent = 50 -
Després de fer els canvis, deseu i tanqueu l'editor de text.
-
Reinicieu el servei de LVM:
systemctl restart lvm2-lvmpolld -
Creeu un nou snapshot amb una mida petita:
lvcreate -L 1G -s -n snap_data /dev/vg_webapp/lv_data -
Afegiu un fitxer de 500MB al directori
/opt/webapp/data:dd if=/dev/zero of=/opt/webapp/data/file5.txt bs=1M count=500 oflag=dsync -
Comproveu l'estat de l'snapshot amb la comanda
lvs:LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert root almalinux -wi-ao---- 16.41g swap almalinux -wi-ao---- 2.00g lv_data vg_webapp owi-aos--- 20.00g lv_run vg_webapp -wi-a----- 1.00g lv_sources vg_webapp -wi-a----- 1.00g snap_data vg_webapp swi-a-s--- 1.00g lv_data 50.10 -
Modifiqueu el fitxer
/opt/webapp/data:dd if=/dev/zero of=/opt/webapp/data/file5.txt bs=1M count=300 oflag=dsync -
Comproveu l'estat de l'snapshot amb la comanda
lvs:LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert root almalinux -wi-ao---- 16.41g swap almalinux -wi-ao---- 2.00g lv_data vg_webapp owi-aos--- 20.00g lv_run vg_webapp -wi-a----- 1.00g lv_sources vg_webapp -wi-a----- 1.00g snap_data vg_webapp swi-a-s--- 1.00g lv_data 64.12Com hem modificat el fitxer
file5.txt, l'snapshot ha augmentat la seva capacitat al 64%. -
Modifiqueu de nou el fitxer
/opt/webapp/data:dd if=/dev/zero of=/opt/webapp/data/file5.txt bs=1M count=200 oflag=dsync -
Comproveu l'estat de l'snapshot amb la comanda
lvs:LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert root almalinux -wi-ao---- 16.41g swap almalinux -wi-ao---- 2.00g lv_data vg_webapp owi-aos--- 20.00g lv_run vg_webapp -wi-a----- 1.00g lv_sources vg_webapp -wi-a----- 1.00g snap_data vg_webapp swi-a-s--- 1.00g lv_data 72.41Fixeu-vos que l'snapshot
snap_dataha arribat al 72% de la seva capacitat. Això hauria d'activar l'extensió automàtica de l'snapshot. -
Torneu a comprobar l'estat amb
lvs:
LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert
root almalinux -wi-ao---- 16.41g
swap almalinux -wi-ao---- 2.00g
lv_data vg_webapp owi-aos--- 20.00g
lv_run vg_webapp -wi-a----- 1.00g
lv_sources vg_webapp -wi-a----- 1.00g
snap_data vg_webapp swi-a-s--- 1.50g lv_data 48.28
De forma automàtica, l'snapshot s'ha ampliat un 50% més de la seva capacitat original. Això permet que l'snapshot s'adapti als canvi i redueixi la probabilitat de corrupció.
Neteja
-
Elimineu els fitxers de prova:
rm -rf /opt/webapp/data/* -
Elimineu la carpeta
/snaps:rm -rf /snaps -
Elimineu l'snapshot:
lvremove /dev/vg_webapp/snap_data
Anàlisi de l'ús dels snapshots
En el context de la nostra webapp que utilitza LVM, necessitem realitzar un backup de la nostra carpeta de dades que triga aproximadament 1 hora. Durant aquesta hora, es creen o modifiquen aproximadament 1GB de dades. Quines consideracions hauríem de tenir en compte per establir una política eficient d'snapshots, tenint en compte factors com el temps, l’espai, la freqüència i la retenció?
Mirroring
Els miralls (mirrors) són una tècnica per protegir les dades contra la fallada d'un disc dur. Són similars als RAID 1, ja que es tracta de tenir una còpia exacta de les dades en un altre disc dur. Aquesta tècnica proporciona alta disponibilitat i protegeix les dades en cas de fallada d'un dels discs durs.
Diferències entre mirrors i snapshots
-
Mirror: És una còpia exacta de les dades en temps real. Si un disc falla, l'altre continua funcionant, proporcionant un duplicat exacte de les dades en tot moment.
-
Snapshot: És una instantània de les dades en un moment determinat. No reflecteix canvis posteriors a la seva creació.
Preparació
-
Utilitzeu la màquina virtual creada en els apartats anteriors.
-
Assegureu-vos que teniu dos discos durs addicionals de 20 GB adjunts a la màquina virtual, que utilitzarem per a la configuració de mirroring, en el meu cas els discs són
/dev/nvme0n3i/dev/nvme0n5.NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sr0 11:0 1 1.7G 0 rom nvme0n1 259:0 0 20G 0 disk ├─nvme0n1p1 259:1 0 600M 0 part /boot/efi ├─nvme0n1p2 259:2 0 1G 0 part /boot └─nvme0n1p3 259:3 0 18.4G 0 part ├─almalinux-root 253:0 0 16.4G 0 lvm / └─almalinux-swap 253:1 0 2G 0 lvm [SWAP] nvme0n2 259:4 0 20G 0 disk ├─vg_webapp-lv_sources 253:2 0 1G 0 lvm ├─vg_webapp-lv_run 253:3 0 1G 0 lvm └─vg_webapp-lv_data 253:6 0 20G 0 lvm /opt/webapp/data nvme0n3 259:5 0 20G 0 disk nvme0n4 259:6 0 20G 0 disk └─vg_webapp-lv_data 253:6 0 20G 0 lvm /opt/webapp/data nvme0n5 259:7 0 20G 0 disk
Tasques
Creació de mirroring
-
Creeu un mirror del volum lògic
lv_dataamb un mirall:lvconvert --type mirror -m 1 /dev/vg_webapp/lv_dataSi observeu la sortida següent, significa que no hi ha prou espai lliure per crear el mirall:
Insufficient free space: 5121 extents needed, but only 4606 available Unable to allocate extents for mirror(s). -
Utilitzeu un altre disc dur per ampliar el grup de volums i afegir més espai lliure:
pvcreate /dev/nvme0n5 vgextend vg_webapp /dev/nvme0n5 -
Torneu a intentar crear el mirall:
lvconvert --type mirror -m 1 /dev/vg_webapp/lv_dataI observareu que encara no hi ha prou espai lliure per crear el mirall, ja que el mirall necessita dos còpies del volum lògic que es troba repartit en dos discs diferents.
-
Utilitzeu un altre disc dur per ampliar el grup de volums i afegir més espai lliure:
pvcreate /dev/nvme0n3 vgextend vg_webapp /dev/nvme0n3 -
Torneu a intentar crear el mirall:
lvconvert --type mirror -m 1 /dev/vg_webapp/lv_dataAquesta acció pot trigar una estona, ja que s'estan creant dues còpies del volum lògic
lv_data.Logical volume vg_webapp/lv_data being converted. vg_webapp/lv_data: Converted: 0.45% vg_webapp/lv_data: Converted: 100.00% -
Observareu que s'ha creat un mirror amb dos còpies del volum lògic
lvs -a -o +devices:LV VG Attr LSize Pool Origin Data% Meta% Move Log Cpy%Sync Convert Devices root almalinux -wi-ao---- 16.41g /dev/nvme0n1p3(0) swap almalinux -wi-ao---- 2.00g /dev/nvme0n1p3(4201) lv_data vg_webapp mwi-aom--- 20.00g [lv_data_mlog] 100.00 lv_data_mimage_0(0),lv_data_mimage_1(0) [lv_data_mimage_0] vg_webapp iwi-aom--- 20.00g /dev/nvme0n4(0) [lv_data_mimage_0] vg_webapp iwi-aom--- 20.00g /dev/nvme0n2(3072) [lv_data_mimage_1] vg_webapp iwi-aom--- 20.00g /dev/nvme0n3(0) [lv_data_mimage_1] vg_webapp iwi-aom--- 20.00g /dev/nvme0n5(0) [lv_data_mlog] vg_webapp lwi-aom--- 4.00m /dev/nvme0n2(256) lv_run vg_webapp -wi------- 1.00g /dev/nvme0n2(2816) lv_sources vg_webapp -wi------- 1.00g /dev/nvme0n2(0)-
Nota 1: Observeu com tenim dos miralls
lv_data_mimage_0ilv_data_mimage_1i cada mirall utilitza 2 discs diferents. El 0 correspont a/dev/nvme0n4i/dev/nvme0n2i el 1 a/dev/nvme0n3i/dev/nvme0n5. -
Nota 2: El mirall també té un log
lv_data_mlogque s'utilitza per mantenir la consistència dels miralls. -
Nota 3: Ara si un dels discs falla, el sistema continuarà funcionant sense interrupcions a partir del mirall.
-
-
Creeu un fitxer a
/opt/webapp/dataper comprovar que el mirroring funciona correctament:echo "Hello, World!" > /opt/webapp/data/hello.txt -
Desmunteu el mirall per comprovar que les dades es troben en els dos discs:
lvconvert --splitmirrors 1 --name lv_data_backup /dev/vg_webapp/lv_dataEn aquest punt, el mirall
lv_datas'ha dividit en dos volums lògicslv_datailv_data_backup. Això significa que el mirall ja no està actiu i que les dades es troben en els dos volums lògics.mount /dev/vg_webapp/lv_data_backup /mnt cat /mnt/hello.txt -
Elimineu el mirall
lv_data_backup:lvremove /dev/vg_webapp/lv_data_backupAra el mirall
lv_data_backups'ha eliminat i les dades només es troben en el volum lògiclv_data.
Anàlisi
En el context dels servidors web, valora el trade-off entre la disponibilitat i la capacitat de disc. El mirroring és una tècnica que proporciona alta disponibilitat, ja que les dades es troben en dos discs diferents. Això significa que si un disc falla, el sistema continuarà funcionant sense interrupcions a partir del mirall. No obstant això, el mirroring també implica un cost addicional, ja que es necessiten dos discs per emmagatzemar les dades.
Gestió de comptes (Lord of the system)

Tres anillos para los Reyes Elfos bajo el cielo.
Siete para los Señores Enanos en casas de piedra.
Nueve para los Hombres Mortales condenados a morir.
Uno para el Señor Oscuro, sobre el trono oscuro.
Un Anillo para gobernarlos a todos. Un anillo para encontrarlos,
un Anillo para atraerlos a todos y atarlos en las tinieblas
en la Tierra de Mordor donde se extienden las Sombras
Objectius
- Aprendre a gestionar comptes en servidors UNIX/Linux.
- Familiaritzar-se amb els mecanismes de protecció i control d'usuaris.
Requisits
En aquesta pràctica, es demana que es creïn comptes d'usuari en un sistema Linux. Aquests comptes hauran de ser creats amb diferents permisos i restriccions, i s'hauran de configurar els grups i els permisos de fitxers i directoris per a cada usuari. Per tant, reviseu les comandes i els conceptes següents abans de començar:
- useradd: Aquesta comanda s'utilitza per crear nous usuaris en un sistema Linux. Cada usuari té un identificador únic (UID) i pot ser assignat a un o més grups. Aquesta comanda també pot crear els directoris inicials (home directories) pels usuaris.
- groupadd: Aquesta comanda s'utilitza per crear nous grups en un sistema Linux. Els grups són una manera de gestionar col·leccions d'usuaris, permetent una administració eficaç de permisos i accés als recursos del sistema. Els grups ajuden a organitzar i controlar els usuaris amb un mateix conjunt de permisos.
- usermod: Aquesta comanda s'utilitza per modificar els atributs d'un usuari en un sistema Linux. Aquests atributs poden incloure el nom de l'usuari, el directori home, el grup principal, el shell, el UID, el GID, etc.
- passwd: Aquesta comanda s'utilitza per canviar la contrasenya d'un usuari en un sistema Linux. Aquesta comanda permet als usuaris canviar la seva pròpia contrasenya o als administradors canviar la contrasenya d'altres usuaris.
- chown: Aquesta comanda s'utilitza per canviar el propietari i el grup d'un fitxer o directori en un sistema Linux. Aquesta comanda permet als usuaris canviar el propietari i el grup d'un fitxer o directori, sempre que tinguin els permisos necessaris.
- chmod: Aquesta comanda s'utilitza per canviar els permisos d'un fitxer o directori en un sistema Linux. Aquesta comanda permet als usuaris canviar els permisos d'un fitxer o directori, especificant els permisos per a propietaris, grups i altres usuaris.
- setfacl/getfacl: Aquestes comandes s'utilitzen per establir i obtenir llistes de control d'accés (ACL) en un sistema Linux. Les ACL són una manera de controlar l'accés als fitxers i directoris, permetent als usuaris especificar permisos més detallats que els permisos tradicionals de propietari, grup i altres usuaris.
Preparant el servidor
Instancieu un servidor RedHat a la plataforma AWS. Aquest servidor serà el vostre Middlearth.
- Actualitzar totes les llibreries amb
sudo dnf update -y. - Instal·lar un editor de text (vim o nano) amb
sudo dnf install vim -y. - Instal·lar la shell tcsh amb
sudo dnf install tcsh -y. - Actualitzar el nom de l'amfitrió amb:
sudo hostnamectl set-hostname middlearth.
Mostrant informació de benvinguda
El fitxer /etc/motd és l'arxiu on es guarda un missatge de benvinguda; normalment és un arxiu de text senzill que es mostra als usuaris quan inicien sessió. Pot contenir informació com la benvinguda al sistema, informació d'actualitat, polítiques de l'empresa, enllaços a recursos importants o qualsevol altra cosa que es consideri útil per als usuaris en el moment d'iniciar sessió.
Copieu el text següent al fitxer /etc/motd:
# Bienvenido a la tierra media! #
# * * * #
# * * * * * #
# * * * * * * * #
# * * * * * * * #
# * * * * * * * #
# * * * * * #
# * * * #
# El hogar está atrás, el mundo por delante, y ha #
# y muchos caminos que recorrer a través de la #
# sombras hasta el borde de la noche, hasta que #
# las estrellas estén encendidas #
#################################################################
sudo vim /etc/motd
# Afegiu la informació a l'arxiu.
exit
Tornem a iniciar sessió SSH. Per veure el nostre banner, després de fer login.
Mostrant informació: Connexions remotes
L'arxiu /etc/issue.net és similar al missatge del dia (/etc/motd), però aquest s'utilitza per mostrar un missatge als usuaris abans que aquests s'autentiquin en un servidor mitjançant protocols com SSH. Aquest missatge normalment conté informació bàsica o una benvinguda als usuaris quan intenten connectar-se al servidor.
Per activar-ho:
- Copieu el contingut del fitxer /etc/issue.net a /etc/issue.net.default. D'aquesta manera sempre mantindrem una còpia del fitxer original sense editar.
- Copieu el següent text al fitxer /etc/issue.net:
#################################################################
# _ _ _ _ #
# / \ | | ___ _ __| |_| | #
# / _ \ | |/ _ \ '__| __| | #
# / ___ \| | __/ | | |_|_| #
# /_/ \_\_|\___|_| \__(_) #
# #
# You are entering into Mordor! #
# Username has been noted and has been sent to the server #
# administrator! #
#################################################################
Finalment, tornem a iniciar sessió SSH. Per veure el nostre banner.
sudo cp /etc/issue.net /etc/issue.net.default
sudo vim /etc/issue.net
# Copieu el text
# Guardar i sortir
Per podeu veure el banner, s'ha d'editar la configuració del servei SSH:
sudo vim /etc/ssh/sshd_config
# Descomentar
Banner /etc/issue.net
# Guardar i sortir
sudo systemctl restart sshd
exit
Creació de grups
La comanda groupadd s'utilitza per crear nous grups en un sistema Linux. Els grups són una manera de gestionar col·leccions d'usuaris, permetent una administració eficaç de permisos i accés als recursos del sistema. Els grups ajuden a organitzar i controlar els usuaris amb un mateix conjunt de permisos.
groupadd [opcions] nom_del_grup
Crea 4 grups amb els següents GIDs
| nom | GID |
|---|---|
| hobbits | 6000 |
| elfs | 7000 |
| nans | 8000 |
| mags | 9000 |
sudo groupadd -g 6000 hobbits
sudo groupadd -g 7000 elfs
sudo groupadd -g 8000 nans
sudo groupadd -g 9000 mags
o bé:
declare -a groups=("hobbits" "elfs" "nans" "mags")
declare -a gids=(6000 7000 8000 9000)
for i in "${!groups[@]}"; do
sudo groupadd -g ${gids[$i]} ${groups[$i]}
done
Creant els usuaris
La comanda useradd s'utilitza per crear nous usuaris en un sistema Linux. Cada usuari té un identificador únic (UID) i pot ser assignat a un o més grups. Aquesta comanda també pot crear els directoris inicials (home directories) pels usuaris.
Crea els següents comptes
| usuari | UID | GID | nom |
|---|---|---|---|
| frodo | 6001 | 6000 | Frodo |
| gollum | 6002 | 6000 | Smeagol |
| samwise | 6003 | 6000 | Samwise |
| legolas | 7001 | 7000 | Legolas |
| gimli | 8001 | 8000 | Gimli |
| gandalf | 9001 | 9000 | Gandalf |
sudo useradd frodo -g 6000 -u 6001 -c "Frodo, portador de l'anell" -m -d /home/frodo
sudo useradd gollum -g 6000 -u 6002 -c "Smeagol, el cercador de l'anell" -m -d /home/gollum
sudo useradd samwise -g 6000 -u 6003 -c "Samwise, l'amic fidel" -m -d /home/samwise
sudo useradd legolas -g 7000 -u 7001 -c "Legolas, el mestre de l'arc" -m -d /home/legolas
sudo useradd gimli -g 8000 -u 8001 -c "Gimli, el valent guerrer" -m -d /home/gimli
sudo useradd gandalf -g 9000 -u 9001 -c "Gandalf, el mag" -m -d /home/gandalf
o bé:
declare -a users=("frodo" "gollum" "samwise" "legolas" "gimli" "gandalf")
declare -a uids=(6001 6002 6003 7001 8001 9001)
declare -a gids=(6000 6000 6000 7000 8000 9000)
declare -a comments=("Frodo, portador de l'anell" "Smeagol, el cercador de l'anell" "Samwise, l'amic fidel" "Legolas, el mestre de l'arc" "Gimli, el valent guerrer" "Gandalf, el mag")
for i in "${!users[@]}"; do
sudo useradd ${users[$i]} -g ${gids[$i]} -u ${uids[$i]} -c "${comments[$i]}" -m -d /home/${users[$i]}
done
Protegint els comptes
S'ha de requerir contrasenyes robustes per als comptes d'usuari. De manera predeterminada, tots els comptes d'usuari tenen assignada la contrasenya Tolkien2LOR. Un cop l'usuari es connecti per primera vegada, haurà de canviar la contrasenya. A més, s'ha de configurar el sistema perquè bloquegi els comptes d'usuari després de 3 intents fallits.
-
Assigna la contrasenya Tolkien2LOR a tots els usuaris.
declare -a users=("frodo" "gollum" "samwise" "legolas" "gimli" "gandalf") for user in "${users[@]}"; do echo "Tolkien2LOR" | sudo passwd --stdin $user done -
Configura el sistema per bloquejar els comptes d'usuari després de 3 intents fallits durant 120 segons. D'aquesta manera, prevenim els atacs de força bruta i protegim els comptes d'usuari. Per fer-ho, podem utilitzar faillock en versions més recents de RHEL. En versions anteriors, es podia utilitzar pam_tally2.
- Activa el mòdul faillock:
sudo authselect select sssd with-faillock- Configura el mòdul pam_faillock per bloquejar els comptes d'usuari després de 3 intents fallits. El compte es desbloquejarà automàticament després de 120 segons.
sudo vi /etc/security/faillock.conf # Descomenta i modifica les següents línies del fitxer deny=3 unlock_time=120 audit-
Per testar el bloqueig del compte, intenta iniciar sessió amb una contrasenya incorrecta 3 vegades. Després de 3 intents fallits, el compte s'hauria de bloquejar durant 120 segons.
-
Per desbloquejar manualment un compte:
sudo faillock --user frodo --reset -
Configura polítiques de contrasenyes més fortes
-
Edita el fitxer /etc/security/pwquality.conf per establir requisits estrictes per a les contrasenyes:
sudo vi /etc/security/pwquality.conf minlen=12 # Longitud mínima de la contrasenya dcredit=-1 # Requereix un dígit ucredit=-1 # Requereix una lletra en majúscula ocredit=-1 # Requereix un caràcter especial lcredit=-1 # Requereix una lletra en minúscula enforcing=1 # Força l'ús de les polítiques de contrasenya -
Per verificar-ho, intenta canviar la contrasenya d'un usuari i comprova que compleix/no compleix els requisits establerts.
-
-
Requereix el canvi de contrasenya en el primer inici de sessió.
- Per assegurar que els usuaris canviïn la contrasenya predeterminada després de connectar-se per primera vegada, activa aquesta opció:
declare -a users=("frodo" "gollum" "samwise" "legolas" "gimli" "gandalf") for user in "${users[@]}"; do sudo chage -d 0 $user done
Accés a la comarca (SSH)
Configura el servidor SSH per permetre l'accés als usuaris Frodo, Samwise, Legolas i Gimli utilitzant contrasenya. L'usuari Gandalf ha de poder accedir al sistema utilitzant una clau SSH. No s'ha de permetre l'accés a l'usuari Gollum o a l'usuari root.
-
Configura el servidor SSH per permetre l'accés als usuaris Frodo, Samwise, Legolas i Gimli utilitzant contrasenya.
sudo vi /etc/ssh/sshd_config AllowUsers frodo samwise legolas gimli PasswordAuthentication yes AllowUsers gandalf ec2-user PubkeyAuthentication yesNota: La instancia EC2 de RedHat utilitza el fitxer de configuració /etc/ssh/sshd_config/50-cloud-init.conf per configurar el servei SSH. Aquest fitxer s'inclou en el fitxer de configuració principal /etc/ssh/sshd_config.
-
Afegeix la clau pública de l'usuari Gandalf al fitxer ~/.ssh/authorized_keys.
sudo mkdir /home/gandalf/.ssh sudo chmod 600 /home/gandalf/.ssh sudo vi /home/gandalf/.ssh/authorized_keys # Afegeix la clau pública de l'usuari Gandalf sudo chown -R gandalf:mags /home/gandalf/.ssh -
Bloqueja l'accés a l'usuari Gollum.
sudo usermod -s /sbin/nologin gollum -
Reinicia el servei SSH per aplicar els canvis.
sudo systemctl restart sshd
Gandalf, el mag
L'usuari gandalf vol tenir permisos de root. Per fer-ho, l'afegirem al grup wheel.
sudo usermod -aG wheel gandalf
o bé:
sudo gpasswd -a gandalf wheel
Per defecte, en les instancies EC2 d'Amazon Linux, el grup wheel no està habilitat. L'usuari ec2-user té permisos utilitzant l'eina sudo.
Per utilitzar la comanda sudo amb l'usuari gandalf:
sudo visudo
Afegiu la següent línia al fitxer:
gandalf ALL=(ALL) ALL
Si volem que l'usuari gandalf pugui executar comandes com a root sense necessitat de contrasenya, podem afegir la següent línia al fitxer /etc/sudoers:
gandalf ALL=(ALL) NOPASSWD: ALL
En les instancies EC2 d'Amazon Linux, l'usuari ec2-user ja té permisos de sudo, aquesta configuració es troba dins del fitxer /etc/sudoers.d/90-cloud-init-users. Podeu aprofitar i afegir l'usuari gandalf a aquest fitxer. Podeu comprovar que l'usuari gandalf té permisos de root executant la comanda sudo.
sudo cat /etc/shadow
Actualitzant Usuaris
- L'usuari gollum vol tenir el seu home amb el nom smeagol.
sudo usermod -d /home/smeagol -m gollum
- L'usuari legolas vol tenir per defecte la shell tcsh.
sudo usermod -s /bin/tcsh legolas
- L'usuari gimli no vol tenir contrasenya.
sudo passwd -d gimli
Notificació de la comarca
Un cop s'han creat els usuaris entrarem al sistema com a frodo i enviarem un mail a la resta amb el següent missatge: Benvinguts a la companyia, anem direcció mordor.
sudo dnf -y install postfix
sudo dnf -y install s-nail
Postfix és un programari de servidor de correu electrònic que té com a objectiu principal gestionar l'enviament, recepció i l'encaminament de correus electrònics en un entorn de servidor. És conegut per la seva eficiència, seguretat i flexibilitat, i és àmpliament utilitzat en servidors de correu electrònic en tot el món.
Configuració del postfix
Editeu el fitxer /etc/postfix/main.cf:
- myhostname = mail.middlearth.udl.cat
- mydomain = udl.cat
- myorigin = $mydomain
- inet_interfaces = all
- inet_protocols = ipv4
- mydestination = $myhostname, localhost.$mydomain, localhost, $mydomain
- mynetworks = 127.0.0.0/8
- home_mailbox = Maildir/
Afegiu al final del fitxer /etc/postfix/main.cf:
# Amaga el tipus o la versió del programari SMTP
smtpd_banner = $myhostname ESMTP
# Afegeix el següent al final
# Desactiva la comanda SMTP VRFY
disable_vrfy_command = yes
# Requereix la comanda HELO als amfitrions emissors
smtpd_helo_required = yes
# Límit de mida d'un correu electrònic
# Exemple a continuació significa límit de 10M bytes
message_size_limit = 10240000
# Configuracions SMTP-Auth
smtpd_sasl_type = dovecot
smtpd_sasl_path = private/auth
smtpd_sasl_auth_enable = yes
smtpd_sasl_security_options = noanonymous
smtpd_sasl_local_domain = $myhostname
smtpd_recipient_restrictions = permit_mynetworks, permit_auth_destination, permit_sasl_authenticated, reject
Configurant el dimoni
- Arrancant el dimoni
sudo systemctl enable --now postfix
Prova
su - ganfalf
echo "Benvinguts a la companyia, anem direcció mordor." | mail -s "Notificació de la comarca" frodo@localhost
su - frodo
mail
El poder de l'anell
- Crearem un directori /anell.
sudo mkdir /anell
- Crearem un grup portadors.
sudo groupadd portadors
- Assignarem a frodo com a propietari del directori /anell.
sudo chown frodo:portadors /anell
- Modificarem els permisos del directori: Els fitxers d’aquest directori únicament podran ser executats/editats per l’usuari Frodo, la resta d’usuaris no ha de tenir cap permís ni de lectura, a excepció del grup d'usuari del grup portadors que han de poder llegir el directori.
sudo chmod a-rwx /anell
sudo chmod g+r /anell
sudo chmod u+rwx /anell
- En Frodo ha de poder executar tots els fitxers del director /anell/bin sense haver d'afegir tota la ruta, únicament indicant el nom de l'executable.
sudo echo "export PATH=$PATH:/anell/bin" >> $HOME/.bashrc
sudo source $HOME/.bashrc
Final del viatge
- Gimli es confon amb tots els missatges que apareixen a la pantalla quan inicia sessió. Configureu el seu compte perquè no es mostri cap missatge a la pantalla quan comenci la sessió.
su gimli
touch ~/.hushlogin
- No s’ha de permetre que en Gimli executi programes des del seu propi directori /home. Per fer-ho heu d'utilitzar (setfacl):
sudo setfacl -m u:gimli:--- /home/gimli
- L’usuari Samwise s’ha perdut i ha acabat a Narnia, elimineu-lo de l’univers.
sudo userdel -r samwise
Gestió centralitzada d'usuaris utiltizant LDAP
Requisits
-
Instància EC2 amb una distribució Linux que actuara com a servidor LDAP. En el nostre cas, utilitzarem una instància Amazon Linux 2023 amb les següents característiques:
- Nom:
OpenLDAP-AMSA-Server - Tipus:
t2.micro - Arquitectura:
x86_64 - IP pública: Activada
- Seguretat:
OpenLDAP-AMSA-Server-SG- Regles d'entrada:
- SSH: Port 22
- LDAP: Port 389
- LDAPS: Port 636
- Regles de sortida:
- Totes les connexions
- Regles d'entrada:
- Nom:
Servidor LDAP
Instal·lació d'eines i dependències
Segons el manual d'instal·lació necessitem instal·lar un conjunt d'eines:
REQUIRED SOFTWARE
OpenLDAP Software 2.6.3 requires the following software:
Base system (libraries and tools):
Standard C compiler (required)
Cyrus SASL 2.1.27+ (recommended)
OpenSSL 1.1.1+ (recommended)
libevent 2.1.8+ (recommended)
libargon2 or libsodium (recommended)
Reentrant POSIX REGEX software (required)
SLAPD:
The ARGON2 password hashing module requires either libargon2
or libsodium
LLOADD:
The LLOADD daemon or integrated slapd module requires
libevent 2.1.8 or later.
CLIENTS/CONTRIB ware:
Depends on package. See per package README.
Per tant, instal·lem les eines necessàries:
sudo dnf install \
cyrus-sasl-devel make libtool autoconf libtool-ltdl-devel \
openssl-devel libdb-devel tar gcc perl perl-devel wget vim -y
Descarregant el paquet d'instal·lació
Descarreguem el paquet d'instal·lació de la pàgina oficial:
VER="2.6.3"
cd /tmp
wget ftp://ftp.openldap.org/pub/OpenLDAP/openldap-release/openldap-$VER.tgz
tar xzf openldap-$VER.tgz
cd openldap-$VER
Configuració i instal·lació
-
Configurem el paquet amb les opcions que necessitem:
./configure --prefix=/usr --sysconfdir=/etc --disable-static \ --enable-debug --with-tls=openssl --with-cyrus-sasl --enable-dynamic \ --enable-crypt --enable-spasswd --enable-slapd --enable-modules \ --enable-rlookups --disable-sql \ --enable-ppolicy --enable-syslog -
Compilem i instal·lem el paquet:
make depend makeNota: S'hauria de fer un make test per assegurar la correcta compilació, però requereix temps i ometrem el pas.
-
Habilitant paquets addicionals SHA-2: Per defecte, OpenLDAP utilitza l'algorisme de hash SHA-1 per emmagatzemar les contrasenyes. Aquesta configuració es pot trobar al fitxer de configuració d'OpenLDAP, generalment a la secció de configuració del mòdul de contrasenyes. Aquest modul és considerat poc segur pel que fa a la seguretat de les contrasenyes, ja que s'han descobert vulnerabilitats que permeten atacs amb èxit. Es recomana utilitzar algorismes més forts com SHA-256, SHA-384 o SHA-512, que ofereixen una millor seguretat.
cd contrib/slapd-modules/passwd/sha2 make -
Instal·lem els mòduls:
cd ../../../.. # Tornem a la carpeta inicial make install -
Instal·lem els mòduls addicionals:
cd contrib/slapd-modules/passwd/sha2 make install
En aquest punt, si tot ha anat bé, ja tindrem el servidor LDAP instal·lat al nostre servidor. Podeu comprovar:
-
Els fitxers de configuració a
/etc/openldap/:ls -la /etc/openldap/ -
Les llibreries instal·lades a
/usr/libexec/openldap:ls -la /usr/libexec/openldap
Creació d'un usuari/grup per gestionar el dimoni
Es una bona pràctica quan configurem serveis tenir un usuari dedicat i un grup amb permisos restringits per executar aplicacions del sistema. Per tant, anem a fer-ho pel servei LDAP.
En primer lloc crearem el grup amb gid 55 anomenat ldap.
groupadd -g 55 ldap
L'usuari ldap no necessita directori al sistema i el seu directori personal el podem assignar a /var/lib/openldap. El grup serà l'anterior amb gid 55 i podem assignar el uid 55 a l'usuari ldap. Finalment, podem impedir que aquest usuari inici sessió amb una shell nologin.
useradd -r -M -d /var/lib/openldap -u 55 -g 55 -s /usr/sbin/nologin ldap
Configuració del servei
-
Crearem un directori per guardar les dades /var/lib/openldap:
mkdir /var/lib/openldap -
Crearem un directori per guardar la base de dades /etc/openldap/slapd.d:
mkdir /etc/openldap/slapd.d -
Atorguem els permisos necessaris:
chown -R ldap:ldap /var/lib/openldap chown root:ldap /etc/openldap/slapd.conf chmod 640 /etc/openldap/slapd.conf -
Crearem un fitxer de configuració per el servei LDAP:
cat > /etc/systemd/system/slapd.service << 'EOL' [Unit] Description=OpenLDAP Server Daemon After=syslog.target network-online.target Documentation=man:slapd Documentation=man:slapd-mdb [Service] Type=forking PIDFile=/var/lib/openldap/slapd.pid Environment="SLAPD_URLS=ldap:/// ldapi:/// ldaps:///" Environment="SLAPD_OPTIONS=-F /etc/openldap/slapd.d" ExecStart=/usr/libexec/slapd -u ldap -g ldap -h ${SLAPD_URLS} $SLAPD_OPTIONS [Install] WantedBy=multi-user.target EOL-
En la primera secció Unit indicarem el dimoni del servidor OpenLDAP (Description=OpenLDAP Server Daemon) i que ha de ser iniciat després de syslog.target i network-online.target.
-
En la segona secció Service s'estableix que el servei és de tipus forking (és a dir, es farà un
fork()com a procés fill en segon pla), es defineix el fitxer de PID (PIDFile=/var/lib/openldap/slapd.pid) i es configuren les variables d'entorn per a les URL d'OpenLDAP i les opcions d'OpenLDAP. Finalment, s'especifica la comanda d'inici (ExecStart) per a iniciar el dimoni amb les opcions adequades. -
En la tercera secció Install s'indica que el servei ha de ser iniciat en el moment que s'inicia el sistema.
-
Genració de contrasenyes amb SHA-512
Per generar contrasenyes amb l'algorisme de hash SHA-512 (també conegut com a SSHA-512) utilitzant la comanda slappasswd, pots seguir aquests passos:
slappasswd -h "{SSHA512}" -o module-load=pw-sha2.la -o module-path=/usr/local/libexec/openldap
A continuació, la comanda demanarà la nova contrasenya:
# new password: 1234
# Re-enter new password: 1234
Un cop introdueixis la contrasenya, es generarà el hash corresponent amb l'algorisme SHA-512. El resultat hauria de ser similar a això:
{SSHA512}CBVaUdQC9mVvAi+0O92J3hA+aPdiWUqf4lVr6bGRAUsFJX5aFOEb+1pSsY8PQwW1UKuuCGO2+160HotnfjXIaRKlryVekLnu
Aquest és el hash de la contrasenya "1234" generat amb l'algorisme SHA-512.
Nota: D'ara en endavant...Si voleu modificar contrasenyes i utiltizar aquesta encriptació heu de seguir aquests passos.
Crent la base de dades
Notació important: LDAP utilitza una configuració basada en objectes. Cada objecte té una sèrie d'atributs que defineixen les seves característiques.
-
Configuració global: Aquesta configuració es troba a la base de dades de configuració, que es troba a la branca
cn=config. Aquesta base de dades conté la configuració del servidor LDAP, com ara els mòduls carregats, els esquemes, els índexs, etc.- dn: Distinguished Name: El nom distintiu de l'objecte. És com una adreça única que identifica l'objecte dins de l'estructura de l'arbre LDAP.
- objectClass: Classe d'objecte: Defineix el tipus d'objecte que és.
- cn: Common Name: Nom comú de l'objecte.
- olcArgsFile: Fitxer d'arguments: On es guarden els arguments usats per slapd al iniciar-se.
- olcPidFile: Fitxer PID: On es guarda el PID del procés slapd.
- olcTLSCipherSuite: Llista de xifrats TLS/SSL permesos per a les connexions segures.
- olcTLSProtocolMin: Versió mínima de TLS permesa.
-
Configuració de mòduls: Aquesta base de dades conté els mòduls carregats pel servidor LDAP. En el nostre cas, carregarem el mòdul
pw-sha2.laper a poder utilitzar l'algorisme de hash SHA-512 i el backendback_mdb.laper a emmagatzemar les dades en una base de dades de tipus MDB. -
Configuració d'esquemes: Aquesta configuració es troba a la base de dades de configuració, que es troba a la branca
cn=schema,cn=config. Aquesta base de dades conté els esquemes que defineixen els objectes i atributs que es poden utilitzar a la base de dades. -
Configuració del frontend: Aquesta configuració es troba a la base de dades de configuració, que es troba a la branca
olcDatabase=frontend,cn=config. Aquesta configuració defineix com s'accedeix a la base de dades. Crearem dos regles:- Lectura de l'esquema: Permet a qualsevol usuari llegir l'esquema de la base de dades.
- Atorgar permisos d'administrador: Permet a l'usuari
gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=authgestionar la base de dades.
Per fer-ho, crearem un fitxer de configuració slapd.ldif a /etc/openldap/ amb el següent contingut:
mv /etc/openldap/slapd.ldif /etc/openldap/slapd.ldif.default
cat > /etc/openldap/slapd.ldif << 'EOL'
dn: cn=config
objectClass: olcGlobal
cn: config
olcArgsFile: /var/lib/openldap/slapd.args
olcPidFile: /var/lib/openldap/slapd.pid
olcTLSCipherSuite: TLSv1.2:HIGH:!aNULL:!eNULL
olcTLSProtocolMin: 3.3
dn: cn=schema,cn=config
objectClass: olcSchemaConfig
cn: schema
dn: cn=module,cn=config
objectClass: olcModuleList
cn: module
olcModulepath: /usr/libexec/openldap
olcModuleload: back_mdb.la
dn: cn=module,cn=config
objectClass: olcModuleList
cn: module
olcModulepath: /usr/local/libexec/openldap
olcModuleload: pw-sha2.la
include: file:///etc/openldap/schema/core.ldif
include: file:///etc/openldap/schema/cosine.ldif
include: file:///etc/openldap/schema/nis.ldif
include: file:///etc/openldap/schema/inetorgperson.ldif
dn: olcDatabase=frontend,cn=config
objectClass: olcDatabaseConfig
objectClass: olcFrontendConfig
olcDatabase: frontend
olcPasswordHash: {SSHA512}CBVaUdQC9mVvAi+0O92J3hA+aPdiWUqf4lVr6bGRAUsFJX5aFOEb+1pSsY8PQwW1UKuuCGO2+160HotnfjXIaRKlryVekLnu
olcAccess: to dn.base="cn=Subschema" by * read
olcAccess: to *
by dn.base="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=auth" manage
by * none
dn: olcDatabase=config,cn=config
objectClass: olcDatabaseConfig
olcDatabase: config
olcRootDN: cn=config
olcAccess: to *
by dn.base="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=auth" manage
by * none
EOL
En aquest fitxer, definim la configuració del servidor LDAP, com ara la base de dades, el mòdul de contrasenyes, els esquemes i els permisos d'accés.
Un cop creat el fitxer, carreguem la configuració a la base de dades:
cd /etc/openldap/
slapadd -n 0 -F /etc/openldap/slapd.d -l /etc/openldap/slapd.ldif
chown -R ldap:ldap /etc/openldap/slapd.d
Nota: Si es produeix un error, podeu eliminar la base de dades i tornar a carregar la configuració.
Finalment, iniciem el servei LDAP:
systemctl daemon-reload
systemctl enable --now slapd
Configurant la estructura de la base de dades
Per configurar la base de dades, crearem un fitxer rootdn.ldif a /etc/openldap/ amb el següent contingut:
BASE="dc=amsa,dc=udl,dc=cat"
echo "...Generating rootdn file"
cat << EOL >> rootdn.ldif
dn: olcDatabase=mdb,cn=config
objectClass: olcDatabaseConfig
objectClass: olcMdbConfig
olcDatabase: mdb
olcDbMaxSize: 42949672960
olcDbDirectory: /var/lib/openldap
olcSuffix: $BASE
olcRootDN: cn=admin,$BASE
olcRootPW: {SSHA512}CBVaUdQC9mVvAi+0O92J3hA+aPdiWUqf4lVr6bGRAUsFJX5aFOEb+1pSsY8PQwW1UKuuCGO2+160HotnfjXIaRKlryVekLnu
olcDbIndex: uid pres,eq
olcDbIndex: cn,sn pres,eq,approx,sub
olcDbIndex: mail pres,eq,sub
olcDbIndex: objectClass pres,eq
olcDbIndex: loginShell pres,eq
olcAccess: to attrs=userPassword,shadowLastChange,shadowExpire
by self write
by anonymous auth
by dn.subtree="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=auth" manage
by dn.subtree="ou=system,$BASE" read
by * none
olcAccess: to dn.subtree="ou=system $BASE"
by dn.subtree="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=auth" manage
by * none
olcAccess: to dn.subtree="$BASE"
by dn.subtree="gidNumber=0+uidNumber=0,cn=peercred,cn=external,cn=auth" manage
by users read
by * none
EOL
En aquest fitxer estem configurant un usuari admin. Aquest usuari té privilegis elevats i pot realitzar diverses operacions d'administració en el servidor LDAP. Observeu les regles (oclAcces). Per defecte, s'utilitza 1234 com a contrasenya, per modificar-la actualitzeu el hash.
Un cop creat el fitxer, carreguem la configuració a la base de dades:
ldapadd -Y EXTERNAL -H ldapi:/// -f rootdn.ldif
Un cop carregada la configuració, ja tindrem la base de dades configurada i l'usuari admin creat. Ara crearem la estructura per guardar usuaris i grups que s'assembli a la que utilitza el sistema Linux per emmagatzemar usuaris i grups.
- dc=amsa,dc=udl,dc=cat: Node principal de la jerarquia LDAP.
- ou=groups,dc=amsa,dc=udl,dc=cat. Aquesta entrada representa una organització per als grups.
- ou=users,dc=amsa,dc=udl,dc=cat. Aquesta entrada representa una organització per als usuaris.
- ou=system,dc=amsa,dc=udl,dc=cat: Aquesta entrada representa una organització per al sistema. És comuna en moltes configuracions LDAP.
BASE="dc=amsa,dc=udl,dc=cat"
DC="amsa"
cat << EOL >> basedn.ldif
dn: $BASE
objectClass: dcObject
objectClass: organization
objectClass: top
o: AMSA
dc: $DC
dn: ou=groups,$BASE
objectClass: organizationalUnit
objectClass: top
ou: groups
dn: ou=users,$BASE
objectClass: organizationalUnit
objectClass: top
ou: users
dn: ou=system,$BASE
objectClass: organizationalUnit
objectClass: top
ou: system
EOL
Un cop creat el fitxer, carreguem la configuració a la base de dades:
ldapadd -Y EXTERNAL -H ldapi:/// -f basedn.ldif
Afegint usuaris i grups
Per crear un usuari dins la jerarquia que has definit, necessitaràs crear una nova entrada d'usuari amb les propietats adequades. Aquí tens un exemple de com fer-ho en format LDIF:
dn: uid=johndoe,ou=users,dc=amsa,dc=udl,dc=cat
objectClass: inetOrgPerson
objectClass: posixAccount
objectClass: shadowAccount
objectClass: top
cn: John Doe
sn: Doe
uid: johndoe
uidNumber: 1000
gidNumber: 1000
homeDirectory: /home/johndoe
loginShell: /bin/bash
userPassword: {SSHA512}CBVaUdQC9mVvAi+0O92J3hA+aPdiWUqf4lVr6bGRAUsFJX5aFOEb+1pSsY8PQwW1UKuuCGO2+160HotnfjXIaRKlryVekLnu
on:
- dn: Distinquished Name (DN) de l'usuari, que indica la seva ubicació dins de la jerarquia. En aquest cas, està dins de la branca "ou=users,dc=curs,dc=asv,dc=udl,dc=cat".
- objectClass: Indica les classes d'objectes a les quals pertany aquesta entrada. En aquest cas, pertany a les classes inetOrgPerson, posixAccount, shadowAccount i top, que defineixen les propietats i característiques de l'usuari.
- cn: El nom complert de l'usuari, en aquest cas "John Doe".
- sn: El cognom de l'usuari, en aquest cas "Doe".
- uid: L'identificador únic de l'usuari.
- uidNumber: L'identificador únic de l'usuari en termes numèrics.
- gidNumber: L'identificador únic del grup al qual pertany l'usuari en termes numèrics.
- homeDirectory: La carpeta d'inici de l'usuari.
- loginShell: L'intèrpret de comandes que utilitzarà l'usuari en iniciar sessió.
- userPassword: El hash de la contrasenya de l'usuari (en aquest cas, utilitzant l'algorisme SHA-512). Recordeu que aquesta és una versió encriptada de la contrasenya "1234" generada prèviament amb l'algorisme SHA-512. En la pràctica, caldria utilitzar un hash de la contrasenya de l'usuari que estigui segur.
Una pràctica comuna es la cració d'un usuari OSProxy. Aquest usuari té funcions específiques per a la resolució d'UIDs i GIDs. Aquesta separació de privilegis és una pràctica de seguretat que redueix l'abast de les possibles vulnerabilitats. Això millora la seguretat de la base de dades LDAP restringint l'accés només al que és necessari.
cat << EOL >> users.ldif
dn: cn=osproxy,ou=system,$BASE
objectClass: organizationalRole
objectClass: simpleSecurityObject
cn: osproxy
userPassword:{SSHA512}CBVaUdQC9mVvAi+0O92J3hA+aPdiWUqf4lVr6bGRAUsFJX5aFOEb+1pSsY8PQwW1UKuuCGO2+160HotnfjXIaRKlryVekLnu
description: OS proxy for resolving UIDs/GIDs
EOL
groups=("programadors" "dissenyadors")
gids=("5000" "5001")
users=("jordi" "manel")
sn=("mateo" "lopez")
uids=("4000" "4001")
programadors=("jordi")
dissenyadors=("manel")
for (( j=0; j<${#groups[@]}; j++ ))
do
cat << EOL >> users.ldif
dn: cn=${groups[$j]},ou=groups,$BASE
objectClass: posixGroup
cn: ${groups[$j]}
gidNumber: ${gids[$j]}
EOL
done
for (( j=0; j<${#users[@]}; j++ ))
do
cat << EOL >> users.ldif
dn: uid=${users[$j]},ou=users,$BASE
objectClass: posixAccount
objectClass: shadowAccount
objectClass: inetOrgPerson
cn: ${users[$j]}
sn: ${sn[$j]}
uidNumber: ${uids[$j]}
gidNumber: ${uids[$j]}
homeDirectory: /home/${users[$j]}
loginShell: /bin/sh
EOL
done
Un cop creat el fitxer, carreguem la configuració a la base de dades:
ldapadd -Y EXTERNAL -H ldapi:/// -f users.ldif
Configuració de certificats TLS
Els certificats TLS són una part important de la configuració de seguretat d'un servidor LDAP. Aquests certificats s'utilitzen per xifrar les comunicacions entre el client i el servidor, protegint les dades de ser interceptades per tercers.
Per configurar els certificats TLS en el servidor LDAP, necessitaràs generar un parell de claus privades i certificats públics, i configurar el servidor per utilitzar-los.
En primer lloc, genera un parell de claus privades i certificats públics amb la comanda openssl. A continuació, crea un fitxer ldapcert.ldif a /etc/openldap/ amb el següent contingut:
HOSTNAME="amsa.udl.cat"
commonname=$HOSTNAME
country=ES
state=Spain
locality=Igualada
organization=UdL
organizationalunit=IT
email=admin@udl.cat
echo "Generating key request for $commonname"
openssl req -days 500 -newkey rsa:4096 \
-keyout "$PATH_PKI/ldapkey.pem" -nodes \
-sha256 -x509 -out "$PATH_PKI/ldapcert.pem" \
-subj "/C=$country/ST=$state/L=$locality/O=$organization/OU=$organizationalunit/CN=$commonname/emailAddress=$email"
En segon lloc, atorga els permisos adequats als fitxers de claus privades i certificats públics:
chown ldap:ldap "$PATH_PKI/ldapkey.pem"
chmod 400 "$PATH_PKI/ldapkey.pem"
cat "$PATH_PKI/ldapcert.pem" > "$PATH_PKI/cacerts.pem"
En tercer lloc, crea un fitxer add-tls.ldif a /etc/openldap/ amb el següent contingut:
cat << EOL >> add-tls.ldif
dn: cn=config
changetype: modify
add: olcTLSCACertificateFile
olcTLSCACertificateFile: "$PATH_PKI/cacerts.pem"
-
add: olcTLSCertificateKeyFile
olcTLSCertificateKeyFile: "$PATH_PKI/ldapkey.pem"
-
add: olcTLSCertificateFile
olcTLSCertificateFile: "$PATH_PKI/ldapcert.pem"
EOL
Finalment, carrega la configuració a la base de dades:
ldapadd -Y EXTERNAL -H ldapi:/// -f add-tls.ldif
Un cop carregada la configuració, ja tindrem els certificats TLS configurats en el servidor LDAP.
Testeig de la instal·lació
Per comprovar que la instal·lació ha estat correcta, pots utilitzar la comanda ldapsearch per buscar les entrades de la base de dades. Per exemple, pots buscar l'usuari que has creat amb la comanda següent:
ldapsearch -x -W -H ldapi:/// -D "cn=admin,dc=amsa,dc=udl,dc=cat" -b "ou=users,dc=amsa,dc=udl,dc=cat"
Aquesta comanda utilitza l'usuari admin que has creat per connectar-se al servidor LDAP i buscar les entrades de la branca "ou=users,dc=amsa,dc=udl,dc=cat". Si tot ha anat bé, hauries de veure les dades dels usuaris que has creat.
Nota: Us he creat un script que recull totes les comandes anteriors i les executa: ldapserver.sh
Comandes útils de LDAP
- ldapsearch: Per buscar entrades a la base de dades LDAP.
- ldapadd: Per afegir noves entrades a la base de dades LDAP.
- ldapmodify: Per modificar les entrades de la base de dades LDAP.
- ldapdelete: Per eliminar les entrades de la base de dades LDAP.
- ldappasswd: Per canviar la contrasenya d'un usuari a la base de dades LDAP.
Per exemple:
-
Per modificar la contrasenya d'un usuari:
ldappasswd -H ldapi:/// -D "cn=admin,dc=amsa,dc=udl,dc=cat" -x -W -S "uid=jordi,ou=users,dc=amsa,dc=udl,dc=cat"Nota: Heu d'introduir la contrasenya xifrant amb SHA-512 com hem vist anteriorment.
-
Podem comprovar que la contrasenya s'ha modificat correctament amb la comanda
ldapsearch.ldapsearch -x -W -H ldapi:/// -D "uid=jordi,ou=users,dc=amsa,dc=udl,dc=cat" -b "ou=users,dc=amsa,dc=udl,dc=cat"
Exercicis
-
Configura la base de dades middlearth amb els usuaris i grups creats a l'exercici anterior.
- Crea un fitxer anomenat middleearth.ldif que contingui la configuració necessària per a la base de dades.
- Carrega aquesta configuració al servidor LDAP mitjançant eines com ldapadd o ldapmodify.
BASE="dc=amsa,dc=udl,dc=cat"
groups=("hobbits" "elfs" "nans" "mags")
gids=("6000" "7000" "8000" "9000")
for (( j=0; j<${#groups[@]}; j++ ));
do
cat << EOL >> middleearth.ldif
dn: cn=${groups[$j]},ou=groups,$BASE
objectClass: posixGroup
cn: ${groups[$j]}
gidNumber: ${gids[$j]}
EOL
done
groups=("hobbits" "elfs" "nans" "mags")
gids=("6000" "7000" "8000" "9000")
users=("frodo" "gollum" "samwise" "legolas" "gimli" "gandalf")
b2g=("hobbits","hobbits","hobbits","elfs","nans","mags")
sn=("baggins" "smeagol" "gamgee" "greenleaf" "sonofgloin" "thegrey")
uids=("6001" "6002" "6003" "7001" "8001" "9001")
for (( j=0; j<${#users[@]}; j++ ))
do
cat << EOL >> users.ldif
dn: uid=${users[$j]},ou=users,$BASE
objectClass: posixAccount
objectClass: shadowAccount
objectClass: inetOrgPerson
cn: ${users[$j]}
sn: ${sn[$j]}
uidNumber: ${uids[$j]}
gidNumber: ${b2g[$j]}
homeDirectory: /home/${users[$j]}
loginShell: /bin/sh
EOL
done
-
Configura una altra instància EC2 com a client LDAP.
-
Assegura't que aquesta màquina autentiqui els usuaris i grups de Linux mitjançant el servidor LDAP configurat prèviament.
Per configurar els nostres clients podem utilitzar un script que ens faciliti la tasca. Aquest script ens permetrà configurar el client LDAP amb les dades del servidor LDAP.
Únicament caldrà modificar les variables
LDAP_SERVERiBASEamb les dades del servidor LDAP. En el nostre cas, LDAP_SERVER ha de coincidir amb el DNS públic de la instància del servidor LDAP i BASE amb el nom de la base de dades que hem creat en el nostre casdc=amsa,dc=udl,dc=cat. A més, caldrà copiar el fitxercacert.crtdel servidor LDAP al client.Per fer-ho, copieu el contingut del fitxer
/etc/pki/tls/cacerts.pemdel servidor LDAP al client i deseu-lo com a/etc/pki/tls/cacert.crt.# Al servidor sudo cat /etc/pki/tls/cacerts.pem # Al client sudo vi "/etc/pki/tls/cacert.crt"echo "This script will configure the client to connect to the LDAP server" echo "... Did you copy the cacert.crt from the server to the client? (y/n)?" read -r response if [ "$response" != "y" ]; then echo "Exiting..." exit 1 fi # Variables LDAP_SERVER="ec2-44-206-252-61.compute-1.amazonaws.com" BASE="dc=amsa,dc=udl,dc=cat" PATH_PKI="/etc/pki/tls" echo "... Setting the hostname to $LDAP_SERVER" echo "... Setting the base to $BASE" echo "... Setting the path to $PATH_PKI" echo "... Are you sure you want to continue? (y/n), are this values correct?" read -r response if [ "$response" != "y" ]; then echo "Exiting..." exit 1 fi echo "... Install deps and tools" dnf install openldap-clients sssd sssd-tools oddjob-mkhomedir -y echo "... Configuring sssd" cat << EOL >> /etc/sssd/sssd.conf [sssd] services = nss, pam, sudo config_file_version = 2 domains = default [sudo] [nss] [pam] offline_credentials_expiration = 60 [domain/default] ldap_id_use_start_tls = True cache_credentials = True ldap_search_base = $BASE id_provider = ldap auth_provider = ldap chpass_provider = ldap access_provider = ldap sudo_provider = ldap ldap_uri = ldaps://$LDAP_SERVER ldap_default_bind_dn = cn=osproxy,ou=system,$BASE ldap_group_search_base = ou=groups,$BASE ldap_user_search_base = ou=users,$BASE ldap_default_authtok = 1234 ldap_tls_reqcert = demand ldap_tls_cacert = $PATH_PKI/cacert.crt ldap_tls_cacertdir = $PATH_PKI ldap_search_timeout = 50 ldap_network_timeout = 60 ldap_access_order = filter ldap_access_filter = (objectClass=posixAccount) EOL echo "... Configuring ldap.conf" echo "BASE $BASE" >> /etc/openldap/ldap.conf echo "URI ldaps://$LDAP_SERVER" >> /etc/openldap/ldap.conf echo "TLS_CACERT $PATH_PKI/cacert.crt" >> /etc/openldap/ldap.conf authselect select sssd --force # Oddjob is a helper service that creates home directories for users the first time they log in echo "... Configuring oddjob" systemctl enable --now oddjobd echo "session optional pam_oddjob_mkhomedir.so skel=/etc/skel/ umask=0022" >> /etc/pam.d/system-auth systemctl restart oddjobd echo "... Setting permissions" chown -R root: /etc/sssd chmod 600 -R /etc/sssd echo "... Starting sssd" systemctl enable --now sssd echo "... Done"Aquest script configura el client LDAP per connectar-se al servidor LDAP. Per fer-ho, instal·la les eines necessàries, com ara
openldap-clients,sssd,sssd-toolsioddjob-mkhomedir. A continuació, configura el fitxersssd.confamb les dades del servidor LDAP i el fitxerldap.confamb les dades de connexió al servidor LDAP. Finalment, configura el serveioddjobdper crear els directoris d'inici dels usuaris la primera vegada que inicien sessió. Podeu trobar el script a ldapclient.sh.Per testar la configuració del client crearem un directori /home/jordi i l'assignarem a un usuari i a un grup inicialitzat a LDAP.
sudo mkdir /home/jordi sudo chown 4000:5000 /home/jordiNota: L'usuari jordi no és un usuari local, sinó un usuari definit a LDAP. Per tant, si LDAP no està configurat correctament, veurem el valors numèrics 4000 i 5000 en lloc del nom de l'usuari i el grup.
En canvi, si tot està configurat correctament, veurem el nom de l'usuari i el grup corresponents a aquests valors numèrics definits a LDAP.
sudo ls -l /home drwxr-xr-x. 2 jordi programadors 6 Sep 26 18:36 jordi
-
-
Instal·la i configura un client web per gestionar LDAP. Pots utilitzar l'eina LAM.
-
Instal·la LDAP Account Manager (LAM) a la instància del servidor LDAP.
-
Configura l'eina perquè es connecti al servidor LDAP i permeti la gestió dels usuaris i grups de manera visual utilitzant una interfície web.
Per instal·lar LAM, primer cal instal·lar les dependències necessàries:
sudo dnf install -y httpd php php-ldap php-mbstring php-gd php-gmp php-zip sudo systemctl enable --now httpdA continuació, descarrega i descomprimeix el paquet de LAM:
sudo wget https://github.com/LDAPAccountManager/lam/releases/download/9.0.RC1/ldap-account-manager-9.0.RC1-0.fedora.1.noarch.rpm sudo dnf install ldap-account-manager-9.0.RC1-0.fedora.1.noarch.rpmFinalment, navega a la pàgina web de LAM a
http://<IP_SERVER>/lami segueix les instruccions per configurar la connexió al servidor LDAP. En el meu cas, he configurat la connexió al servidor LDAP amb les dades següents:http://ec2-34-207-89-93.compute-1.amazonaws.com/lam.
Per configurar l'usuari per accedir a LAM, utilitzarem l'usuari
osproxyque hem creat anteriorment. Aquest usuari té permisos per gestionar la base de dades LDAP. Per fer-ho, anem a LAM Configuration.
Editeu General Settings i us identifiqueu amb l'usuari per defecte, i la contrasenya
lam. En aquest punt, modifiqueu la contrasenya per una més segura, per exemple,@ms@22o4G3i.
Editeu Server Profiles dins de LAM Configuration i modifiqueu el perfil perquè s'identifiqui amb l'usuari
osproxyi la contrasenya que heu definit anteriorment. La contrasenya per defecte éslam. Us recomano que la modifiqueu per una més segura com per exemple@ms@22o4G3i-s3rv3rPr0f1l3.- General Settings:
- Server Address:
ldaps://ec2-44-206-252-61.compute-1.amazonaws.com:636o bé si esteu utilitzant el vostre servidor LDAP,ldap://localhost:389. - List of Valid Users:
cn=osproxy,ou=system,dc=amsa,dc=udl,dc=cat. - Tree suffix:
dc=amsa,dc=udl,dc=cat.
- Server Address:
- Account Types:
- Users:
ou=users,dc=amsa,dc=udl,dc=cat. - Groups:
ou=groups,dc=amsa,dc=udl,dc=cat.
- Users:
Si tot ha anat bé, hauríeu de poder accedir a LAM amb l'usuari
osproxyi gestionar els usuaris i grups de la base de dades LDAP.
- General Settings:
-
Desplegant un servidor web: Wordpress
En aquest laboratori, desplegarem un servidor web senzill amb WordPress, una de les plataformes de gestió de continguts (CMS) més populars del món. WordPress permet crear i gestionar llocs web de manera intuïtiva i eficient, i és ideal per a projectes com blocs, botigues en línia, portals de notícies, i molt més.
Per a aquest desplegament, utilitzarem una arquitectura monolítica, una solució senzilla on tots els components del lloc web es troben en una sola màquina virtual. Aquesta configuració és adequada per a llocs web petits o amb poc trànsit, ja que ofereix una implementació ràpida i fàcil de gestionar. No obstant això, a mesura que el lloc web creixi o augmenti el trànsit, caldrà considerar opcions més complexes, com ara l'escalabilitat horitzontal o vertical.
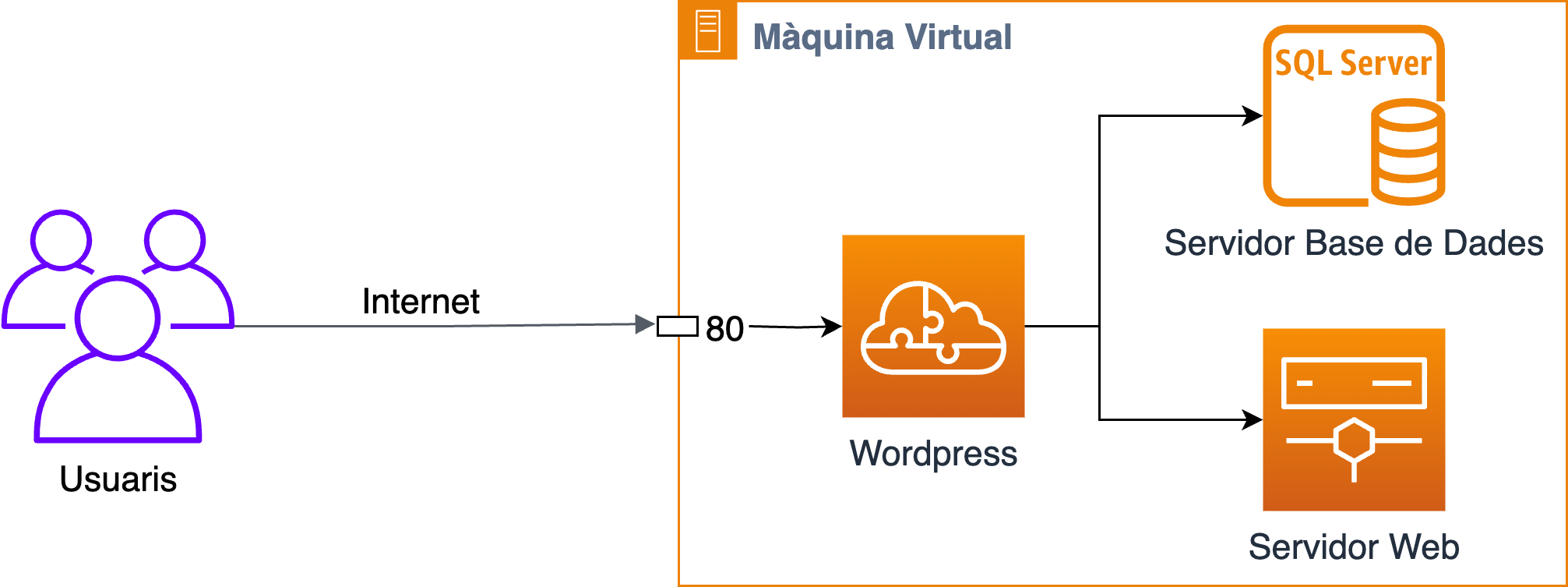
Si consulteu la web oficial de Wordpress, veureu que la versió actual és la 6.6.2. I els seus requeriments per la instal·lació són els següents:
- PHP: Versió 7.4 o superior.
- MySQL o MariaDB: MySQL versió 5.7 o superior o MariaDB versió 10.3 o superior.
- Apache o Nginx: Versió 2.4 o superior per a Apache o versió 1.26 o superior per a Nginx.
- HTTPS: Recomanat per a la seguretat del lloc web.
Per tant, haurem de preparar un servidor que compleixi aquests requeriments abans de procedir a la instal·lació de Wordpress.
Requisits
- Màquina virtual amb sistema operatiu AlmaLinux.
Objectius
- Desplegar un servidor web senzill amb Wordpress.
- Configurar un servidor web amb Apache.
- Configurar una base de dades amb MariaDB.
- Configurar un servidor PHP amb PHP.
- Instal·lar i configurar Wordpress.
- Provar el lloc web de Wordpress.
Desplegant un servidor web: Wordpress
En aquest laboratori, desplegarem un servidor web senzill amb WordPress, una de les plataformes de gestió de continguts (CMS) més populars del món. WordPress permet crear i gestionar llocs web de manera intuïtiva i eficient, i és ideal per a projectes com blocs, botigues en línia, portals de notícies, i molt més.
Per a aquest desplegament, utilitzarem una arquitectura monolítica, una solució senzilla on tots els components del lloc web es troben en una sola màquina virtual. Aquesta configuració és adequada per a llocs web petits o amb poc trànsit, ja que ofereix una implementació ràpida i fàcil de gestionar. No obstant això, a mesura que el lloc web creixi o augmenti el trànsit, caldrà considerar opcions més complexes, com ara l'escalabilitat horitzontal o vertical.
Si consulteu la web oficial de Wordpress, veureu que la versió actual és la 6.6.2. I els seus requeriments per la instal·lació són els següents:
- PHP: Versió 7.4 o superior.
- MySQL o MariaDB: MySQL versió 5.7 o superior o MariaDB versió 10.3 o superior.
- Apache o Nginx: Versió 2.4 o superior per a Apache o versió 1.26 o superior per a Nginx.
- HTTPS: Recomanat per a la seguretat del lloc web.
Per tant, haurem de preparar un servidor que compleixi aquests requeriments abans de procedir a la instal·lació de Wordpress.
Requisits
- Màquina virtual amb sistema operatiu AlmaLinux.
Objectius
- Desplegar un servidor web senzill amb Wordpress.
- Configurar un servidor web amb Apache.
- Configurar una base de dades amb MariaDB.
- Configurar un servidor PHP amb PHP.
- Instal·lar i configurar Wordpress.
- Provar el lloc web de Wordpress.
Preparant el servidor
Un cop creada la màquina virtual, el primer pas és actualitzar el sistema operatiu amb la comanda següent per assegurar-nos que disposem de les últimes actualitzacions de seguretat.
💡 Nota
Mantenir el sistema operatiu actualitzat és una responsabilitat fonamental de qualsevol administrador de sistemes, ja que garanteix l'estabilitat i la seguretat del servidor. Per això, és recomanable començar qualsevol configuració executant una actualització completa del sistema.
dnf -y update
Aquesta comanda actualitza tots els paquets del sistema utilitzant el gestor de paquets DNF. L'opció -y respon automàticament sí a totes les preguntes de confirmació, permetent que l'actualització es realitzi sense intervenció manual.
A més, si preferiu utilitzar un editor de text diferent de vi, podeu instal·lar alternatives com vim, emacs o nano amb les comandes següents:
dnf install vim -y
dnf install nano -y
dnf install emacs -y
Es recomanable tenir un script amb el resum de les comandes que s'han d'executar per preparar el servidor. Així, si cal crear un nou servidor o repetir la configuració en un altre moment, es pot utilitzar aquest script per automatitzar el procés.
#!/bin/bash
# Actualitzar el sistema
dnf -y update
# Instal·lar editors de text
dnf install vim -y
Instal·lant i configurant Apache
El primer pas per desplegar un servidor web amb WordPress és instal·lar i configurar un servidor web. Necessitem la versió 2.4 o superior d'Apache per a la nostra instal·lació.
-
Comprovem si el paquet httpd està disponible:
dnf search httpdLa sortida hauria de mostrar el paquet httpd i les seves dependències.
Last metadata expiration check: 0:00:00 ago on Tue 15 Feb 2022 09:00:00 PM UTC. ============== Name Exactly Matched: httpd ============== httpd.x86_64 : Apache HTTP ServerSi el paquet esta disponible, primer revisarem la informació del paquet amb la comanda
dnf info httpd.Installed Packages Name : httpd Version : 2.4.57 Release : 11.el9_4.1 Architecture : aarch64 Size : 155 k Source : httpd-2.4.57-11.el9_4.1.src.rpm Repository : @System From repo : appstream Summary : Apache HTTP Server URL : https://httpd.apache.org/ License : ASL 2.0 Description : The Apache HTTP Server is a powerful, efficient, and extensible : web server.Un cop ens assegurem que el paquet està disponible amb la versió correcta, procedirem a la instal·lació.
-
Instal·lem el dimoni httpd:
dnf install httpd -y -
Comprovem l'estat del servei amb
systemctl:systemctl status httpd -
Visualitzem els fitxers de configuració del servei httpd:
less /usr/lib/systemd/system/httpd.service[Unit] Description=The Apache HTTP Server Wants=httpd-init.service After=network.target remote-fs.target nss-lookup.target httpd-init.service Documentation=man:httpd.service(8) [Service] Type=notify Environment=LANG=C ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND ExecReload=/usr/sbin/httpd $OPTIONS -k graceful # Send SIGWINCH for graceful stop KillSignal=SIGWINCH KillMode=mixed PrivateTmp=true OOMPolicy=continue [Install] WantedBy=multi-user.targetAquest fitxer de configuració conté instruccions com:
ExecStart=/usr/sbin/httpd $OPTIONS -DFOREGROUND: Defineix la comanda que s'utilitza per iniciar el servei. El mode foreground permet veure la sortida al terminal, útil per a la depuració.ExecReload=/usr/sbin/httpd $OPTIONS -k graceful: Permet recarregar la configuració del servidor sense interrompre les connexions actives, garantint que els canvis es puguin aplicar de manera controlada.KillSignal=SIGWINCH: El senyal que s'envia per aturar el servei, assegurant una parada segura.PrivateTmp=true: Millora la seguretat creant un sistema de fitxers temporal privat per al servei.OOMPolicy=continue: Defineix el comportament del sistema en cas de manca de memòria, permetent que el servei continuï executant-se.
-
Habiliteu el servei per iniciar cada cop que el sistema arranqui:
systemctl enable httpd -
Arranqueu i comproveu l'estat del servei:
systemctl start httpd systemctl status httpd
Un cop aixecat el servei, podem comprovar que el servei està en marxa i funcionant correctament. Intenteu accedir al servidor web amb la vostra IP a través d'un navegador web. En el meu cas, la IP del servidor és :127.16.10.206. Recordeu que per veure la IP del vostre servidor podeu utilitzar la comanda ip a.
Observareu que no és possible accedir-hi i rebeu un missatge d'error ERR_CONNECTION_REFUSED. Això és normal, ja que AlmaLinux té un firewall activat per defecte que bloqueja el tràfic al port 80, que és el port per defecte del servidor web Apache.
systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2022-02-15 21:00:00 UTC; 1h 30min ago
Si desactiveu el servei de firewalld, podreu accedir al servidor web Apache. No obstant això, això no és una pràctica segura, ja que el firewall és una capa de seguretat important per protegir el vostre servidor.
systemctl stop firewalld
En aquest punt, podeu comprovar que el servidor web Apache està funcionant correctament.
Configuració del firewall
El firewall és un servei o programa que protegeix la xarxa del vostre servidor control·lant el tràfic de xarxa que entra i surt del servidor. Això és important per garantir que el vostre servidor sigui segur i protegit contra atacs maliciosos. Permetre només el tràfic necessari i bloquejar el tràfic no desitjat és una pràctica de seguretat recomanada per mantenir el vostre servidor segur. En aquest cas, necessitem permetre el tràfic HTTP (port 80) perquè el servidor web Apache sigui accessible des de l'exterior però bloquejar altres ports i serveis no necessaris.
En tots els sistmes linux el firewall es configura utilitzant les iptables. En el nostre cas, podem veure les regles amb la comanda iptables -L. Permetre el tràfic HTTP (port 80) amb les iptables seria:
iptables -A INPUT -m state --state NEW -m tcp -p tcp --dport 80 -j ACCEPT
iptables -A INPUT -m state --state NEW -m udp -p udp --dport 80 -j ACCEPT
on:
-A INPUT: Afegeix una regla a la cadena INPUT (paquets que entren al servidor).-m state --state NEW: Només s'aplica a paquets nous.-m tcp -p tcp: Només s'aplica a paquets TCP.-M udp -p udp: Només s'aplica a paquets UDP.--dport 80: Només s'aplica als paquets que arriben al port 80.-j ACCEPT: Accepta els paquets que compleixen les condicions anteriors.
Però, tenim eines que ens faciliten la tasca com firewalld o ufw. En aquest cas, utilitzarem firewalld. Firewalld és un firewall dinàmic per a sistemes Linux que proporciona una interfície de línia de comandes i una interfície gràfica per gestionar les regles del firewall. Firewalld té un programa de comandament anomenat firewall-cmd que us permet gestionar les regles del firewall de manera senzilla i eficaç. Per permetre el tràfic HTTP (port 80) amb firewalld, podeu utilitzar la comanda següent:
firewall-cmd --add-service=http --permanent
on:
--add-service=http: Afegeix una regla per permetre el tràfic HTTP.--permanent: Afegeix la regla de manera permanent, la qual cosa significa que es mantindrà després de reiniciar el sistema.
Per aplicar els canvis, cal recarregar el firewall amb la comanda següent:
firewall-cmd --reload
Amb aquesta configuració, el vostre firewall està configurat per permetre el tràfic HTTP (port 80) al vostre servidor. Per verificar que la configuració del firewall s'ha aplicat correctament i que el servei HTTP està habilitat, podeu utilitzar la següent comanda:
firewall-cmd --list-all
Aquesta comanda mostrarà la sortida amb informació detallada sobre la configuració actual del firewall. Per identificar si el servei HTTP està habilitat, busqueu la secció services i verifiqueu que aparegui el servei http com a un dels serveis habilitats.
La sortida hauria de semblar-se així:
public
target: default
icmp-block-inversion: no
interfaces:
sources:
services: cockpit dhcpv6-client http ssh
ports:
protocols:
forward: no
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
En aquest exemple, podeu veure que el servei HTTP està habilitat, la qual cosa significa que el tràfic HTTP hauria de ser permès a través del firewall. A més a més, podeu veure altres serveis com el servei SSH, el servei DHCPv6-client i el servei Cockpit que també estan habilitats. Aquests serveis són necessaris per a la gestió del servidor i per a la connectivitat de xarxa.
Com deshabilitareu la regla per bloquejar el tràfic?
firewall-cmd --remove-service=http --permanent
firewall-cmd --reload
Instal·lant i configurant MariaDB
Per poder utilitzar el Wordpress necessitem d'una base de dades del tipus MariaDB o MySQL. El primer pas es revisar si el paquet mariadb està disponible amb la versió correcta.
dnf search mariadb
dnf info mariadb
Name : mariadb
Epoch : 3
Version : 10.5.22
Release : 1.el9_2.alma.1
Architecture : aarch64
Size : 18 M
Source : mariadb-10.5.22-1.el9_2.alma.1.src.rpm
Repository : @System
From repo : appstream
Summary : A very fast and robust SQL database server
URL : http://mariadb.org
License : GPLv2 and LGPLv2
Description : MariaDB is a community developed fork from MySQL - a multi-user, multi-threaded
: SQL database server. It is a client/server implementation consisting of
: a server daemon (mariadbd) and many different client programs and libraries.
: The base package contains the standard MariaDB/MySQL client programs and
: utilities.
-
Instal·lem el paquet mariadb:
dnf install mariadb-server mariadb -y -
Iniciem el servei de MariaDB:
systemctl enable --now mariadb -
Comprovem l'estat del servei:
systemctl status mariadb -
Configurem MariaDB:
mysql_secure_installation 1. Enter current password for root (enter for none): 2. Switch to unix_socket authentication [Y/n] n 3. Set root password? Y 4. New password: xxxxxxx 5. Remove anonymous users? Y 6. Disallow root login remotely? Y 7. Remove test database and access to it? Y 8. Reload privilege tables now? Yon:
- Enter current password for root (enter for none): En aquest punt, si és la primera vegada que configureu MariaDB, premeu simplement Enter, ja que encara no hi ha contrasenya establerta per a l'usuari root.
- Switch to unix_socket authentication [Y/n]: En aquest punt, respongueu n per desactivar l'autenticació de l'usuari root a través de unix_socket. Si respongueu Y, l'autenticació de l'usuari root es farà a través del sistema de fitxers, aquesta opció permet autenticacions avançades que veurem més endavant.
- Set root password? (Y/n): Respongueu Y per indicar que voleu establir una contrasenya per a l'usuari root de MariaDB. A continuació, introduïu la nova contrasenya quan se us demani. (per exemple: 1234).
- Remove anonymous users? (Y/n): Respongueu Y per eliminar els usuaris anònims. Això millora la seguretat del sistema, ja que no permet connexions no autenticades.
- Disallow root login remotely? (Y/n): Respongueu Y per desactivar l'inici de sessió remot per a l'usuari root. Això significa que l'usuari root només podrà iniciar sessió des de la màquina local.
- Remove test database and access to it? (Y/n): Respongueu Y per eliminar la base de dades de proves i l'accés a ella. Això elimina les bases de dades i els usuaris de prova, augmentant encara més la seguretat.
- Reload privilege tables now? (Y/n): Respongueu Y per recarregar les taules de privilegis de MariaDB. Això assegura que els canvis de configuració es facin efectius de seguida.
-
Inicieu sessió a MariaDB:
mysql -u root -p -
Creeu una base de dades per a Wordpress:
CREATE DATABASE wordpress_db; -
Creeu un usuari per a la base de dades:
CREATE USER 'wordpress_user'@'localhost' IDENTIFIED BY 'password';- wordpress_user: Nom de l'usuari de la base de dades.
- password: Contrasenya de l'usuari de la base de dades.
- localhost: Nom de l'amfitrió on es connectarà l'usuari.
En aquest cas, heu de substituir wordpress_user i password pels valors que vulgueu utilitzar.
-
Atorgueu tots els permisos a l'usuari per a la base de dades:
GRANT ALL ON wordpress_db.* TO 'wordpress_user'@'localhost';- wordpress_db: Nom de la base de dades.
- wordpress_user: Nom de l'usuari de la base de dades.
- localhost: Nom de l'amfitrió on es connectarà l'usuari.
Aquesta comanda atorga tots els permisos de la base de dades wordpress_db a l'usuari wordpress_user.
-
Actualitzeu els permisos:
FLUSH PRIVILEGES; -
Sortiu de MariaDB:
EXIT;
Aquesta configuració de MariaDB és suficient per a la instal·lació de Wordpress. S'han adaptat els passos de la documentació oficial https://developer.wordpress.org/advanced-administration/before-install/creating-database/.
Instal·lant i configurant PHP
Actualment, la documentació oficial de WordPress recomana utilitzar PHP versió 7.4 o superior per a un funcionament òptim i segur del sistema.
-
Compovem si el paquet php està disponible:
dnf search php -
Comprovem les versions disponibles de PHP:
dnf module list phpAquesta comanda mostra una llista de les versions del mòdul PHP disponibles. Et permetrà veure quines versions de PHP pots instal·lar mitjançant mòduls.
-
Instal·lem la versió 8.1 de PHP:
dnf module install php:8.1 -yL'ús de versions més recents de PHP ofereix molts avantatges, com ara un millor rendiment, més seguretat i noves característiques. Les versions antigues de PHP poden ser més vulnerables a problemes de seguretat i tenir limitacions de rendiment. Per tant, és important seguir les recomanacions de la documentació oficial de WordPress quant a la versió de PHP que has d'utilitzar per a la teva instal·lació.
Un cop instal·lada la versió de PHP, podem comprovar la versió actual amb la comanda
php -v. I començar a instal·lar els paquets i complements necessaris:dnf install php-curl php-zip php-gd php-soap php-intl php-mysqlnd php-pdo -y- php-curl: Proporciona suport per a cURL, que és una llibreria per a la transferència de dades amb sintaxi URL.
- php-zip: Proporciona suport per a la manipulació de fitxers ZIP.
- php-gd: Proporciona suport per a la generació i manipulació d'imatges gràfiques.
- php-soap: Proporciona suport per a la creació i consum de serveis web SOAP.
- php-intl: Proporciona suport per a la internacionalització i localització de l'aplicació.
- php-mysqlnd: És l'extensió MySQL nativa per a PHP, que permet la connexió i la comunicació amb bases de dades MySQL o MariaDB.
- php-pdo: Proporciona l'abstracció de dades d'Objectes PHP (PDO) per a la connexió amb bases de dades.
-
Per finalitzar, podem reiniciar el servei web (httpd).
systemctl restart httpd
Instal·lant i configurant Wordpress
Per instal·lar WordPress ens hem de baixar el paquet de la web oficial. Per fer-ho podem utilitzar la comanda wget per descarregar el paquet de WordPress.
-
Instal·lem el paquet wget:
dnf install wget -y -
Descarreguem el paquet de WordPress:
Es una bona pràctica utilitzar el directori temporal (/tmp) per descarregar el programari a instal·lar com el Wordpress. L'ús d'aquest directori ens proporciona:
-
Espai de disc temporal: Ubicació on es poden emmagatzemar fitxers sense preocupar-se pel seu ús posterior. És una ubicació amb prou espai de disc disponible, generalment, i sol estar netejada periòdicament pels sistemes operatius per evitar l'acumulació de fitxers temporals innecessaris.
-
Evitar problemes de permisos: El directori temporal (/tmp) sol tenir permisos que permeten a tots els usuaris crear fitxers temporals sense problemes de permisos. Això és important quan estàs treballant amb fitxers que poden ser manipulats per diversos usuaris o processos.
-
Seguretat: Com que el directori temporal és netejat periòdicament, hi ha menys risc de deixar fitxers temporals sensibles o innecessaris al sistema després d'una operació. Això ajuda a prevenir la acumulació de residus i a minimitzar els problemes de seguretat relacionats amb fitxers temporals.
-
Evitar col·lisions de noms de fitxers: Utilitzant el directori temporal, es redueixen les possibilitats de col·lisions de noms de fitxers. En altres paraules, si molts usuaris estan descarregant fitxers a la mateixa ubicació, utilitzar el directori temporal ajuda a garantir que els noms de fitxers siguin únics.
En resum, garanteix l'espai, la seguretat i la gestió adequats per a aquest tipus de fitxers, com és el cas de la descàrrega i descompressió de paquets com WordPress.
cd /tmp wget https://wordpress.org/latest.tar.gz -O wordpress.tar.gz -
-
Després d'haver descarregat el paquet, el descomprimim amb la comanda
tar:dnf install tar -y tar -xvf wordpress.tar.gz -
Copiem els continguts a la carpeta del servidor Apache:
cp -R wordpress /var/www/html/ -
Assignem el ownership al usuari apache:
chown -R apache:apache /var/www/html/wordpressEl servei Apache s'executa amb l'usuari apache i el grup apache per defecte. Per tant, és important assegurar-se que els fitxers i directoris del lloc web tinguin el propietari i el grup correctes perquè el servidor web pugui accedir-hi i gestionar-los correctament. Aquesta informació la podeu trobar al fitxer de configuració del servidor web, normalment a /etc/httpd/conf/httpd.conf.
less /etc/httpd/conf/httpd.conf -
Donem permisos (rwx) a l'usuari apache i el seu grup i permisos rw per qualsevol altre usuari:
chmod -R 775 /var/www/html/wordpressAquesta comanda estableix permisos de lectura, escriptura i execució per a l'usuari apache i el seu grup, i permisos de lectura i escriptura per a qualsevol altre usuari. Això permet que l'usuari apache pugui llegir, escriure i executar els fitxers i directoris del lloc web, mentre que altres usuaris poden llegir i escriure-hi. Aquesta configuració és adequada per a la majoria dels llocs web i proporciona un equilibri entre la seguretat i la facilitat d'ús. No obstant això, si teniu necessitats específiques de seguretat o de permisos, podeu ajustar aquests permisos segons les vostres necessitats. L'argument
-Rindica que els permisos s'aplicaran de manera recursiva a tots els fitxers i directoris dins de la carpeta especificada. -
Reiniciem el servei Apache:
systemctl restart httpd
Instal·lació del Wordpress
Un cop hàgiu completat aquests passos, ja podeu accedir a la instal·lació web de WordPress navegant a http://ip/wordpress/. On ip és la ip del vostre servidor. En el nostre cas, la ip del servidor és 172.16.10.206. Per tant: http://172.16.10.206/wordpress/. O bé podeu utilitzar el nom de domini si teniu un configurat.
El primer pas serà completar un formulari amb la informació de la base de dades que hem creat anteriorment. Aquesta informació és necessària per connectar WordPress a la base de dades i emmagatzemar-hi la informació del lloc web.
- Nom de la base de dades:
wordpress-db - Nom d'usuari de la base de dades:
wordpress-user - Contrasenya de la base de dades:
password - Servidor de la base de dades:
localhost - Prefix de la taula:
wp_
Un cop hàgiu introduït aquesta informació, podeu continuar amb el procés d'instal·lació de WordPress.
En aquest punt, observareu el missatge d'error Unable to write to wp-config.php file és típic d'un problema de permisos en el sistema de fitxers quan s'intenta escriure un fitxer com el wp-config.php durant la instal·lació de WordPress.
Ara bé, ja hem donat permisos a l'usuari apache perquè pugui escriure a la carpeta de WordPress. El problema resideix en els permisos de SELinux.
SELinux és un sistema de seguretat que proporciona controls addicionals de seguretat basats en polítiques. Impedeix que els processos realitzin certes accions que no estan permeses per la política de seguretat. Ho podem comprovar amb la comanda:
getenforce
Aquesta comanda et mostrarà l'estat actual de SELinux, que pot ser Enforcing, Permissive o Disabled.
Una solució ràpida seria desactivar SELinux amb la comanda:
setenforce 0
No obstant això, és millor entendre com funciona i com gestionar-lo adequadament. Aquesta és la manera més segura de resoldre problemes relacionats amb permisos sense comprometre la seguretat del sistema. Quan es configuren les etiquetes SELinux correctes i es gestionen els permisos de fitxers de manera adequada, SELinux pot oferir una protecció addicional per al vostre sistema.
Mes endavant al curs veurem com configurar SELinux de manera adequada. De moment us deixo la resolució del problema amb SELinux.
-
Instal·lem les eines de SELinux en cas de no tenir-les:
dnf install policycoreutils-python-utils -y -
Configurem les etiquetes SELinux per a la carpeta de WordPress:
semanage fcontext -a -t httpd_sys_rw_content_t '/var/www/html/wordpress(/.*)?'on:
-a: Afegeix una nova regla.-t httpd_sys_rw_content_t: Estableix l'etiqueta SELinux per als fitxers i directoris de la carpeta de WordPress.'/var/www/html/wordpress(/.*)?': Ruta de la carpeta de WordPress.
-
Aplicar les etiquetes SELinux configurades:
restorecon -Rv /var/www/html/wordpresson:
-R: Aplica els canvis de manera recursiva a tots els fitxers i directoris dins de la carpeta especificada.-v: Mostra la sortida detallada de les accions realitzades./var/www/html/wordpress: Ruta de la carpeta de WordPress.
Amb aquestes accions hem creat una política que permet als processos del servei httpd llegir i escriure a la carpeta de WordPress.
-
Inici de la configuració:
-
Introdueix les dades de la base de dades:
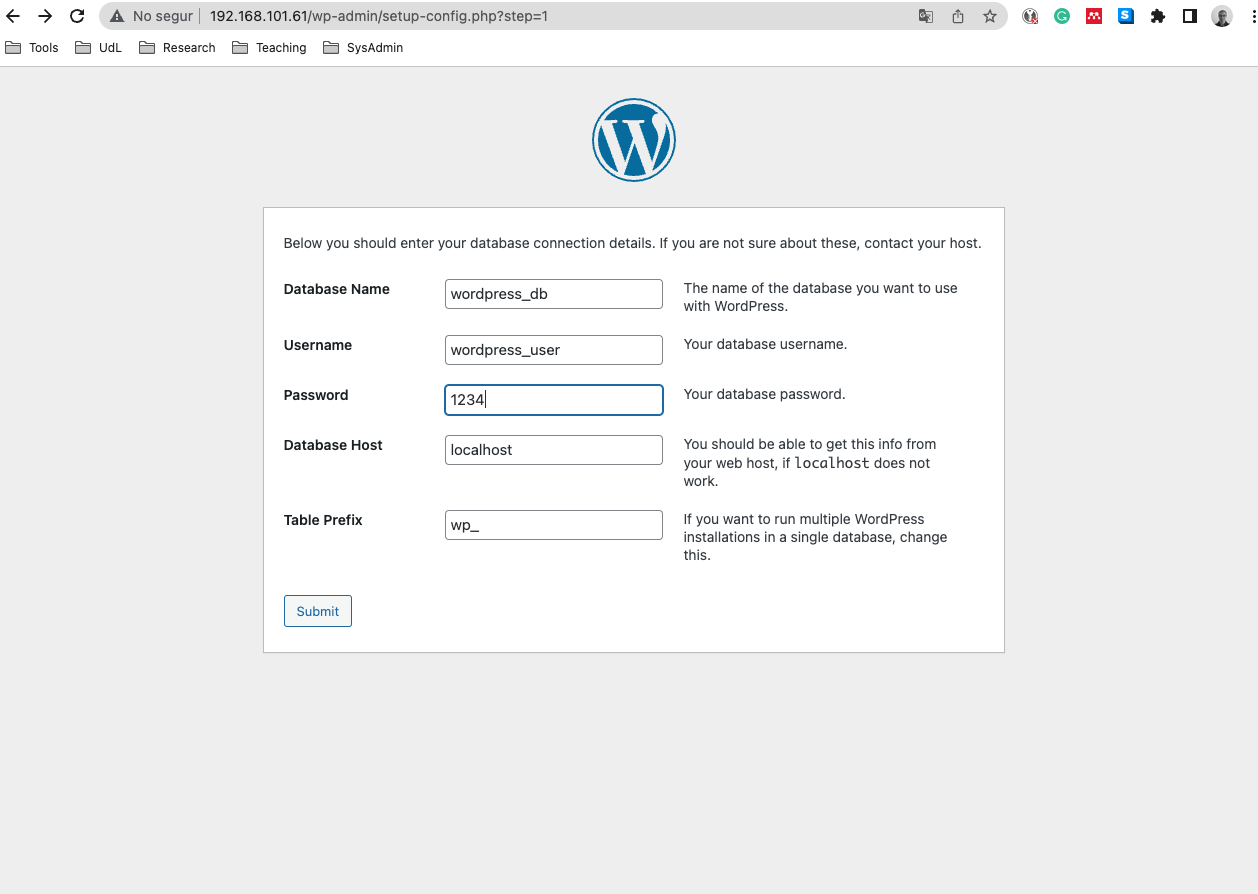
-
Realitza la instal·lació:
-
Configuració del lloc web:
on:
- Site Title: Títol del lloc.
- Username: Nom d'usuari per accedir al panell d'administració.
- Password: Contrasenya per accedir al panell d'administració.
- Your Email: Correu electrònic per a la recuperació de la contrasenya.
Un cop hàgiu introduït aquesta informació, podeu continuar amb el procés d'instal·lació de WordPress. Després d'instal·lar amb èxit WordPress, podreu iniciar la sessió al panell d'administració amb el nom d'usuari i la contrasenya que heu triat i començar a personalitzar i gestionar el vostre lloc web.
-
Inicia sessió amb les credencials creades:
-
Panell d'administració:
-
Visualització del lloc web:
En aquest punt tenim 2 accessos al nostre servidor web. Un és el panell d'administració de WordPress i l'altre és el lloc web en si mateix:
- Panell d'administració: http://ip/wordpress/wp-admin/
- Lloc web: http://ip/wordpress/
On ip és la ip del vostre servidor o el vostre nom de domini si teniu un configurat.
Desplegament al núvol (AWS)
En aquest laboratori desplegarem un servidor web amb Wordpress a Amazon Web Services (AWS). Utilitzarem una instància EC2 amb Amazon Linux 2023 i una base de dades RDS amb MySQL.
Podeu revisar també la guía oficial de Wordpress a AWS.
Configuració de la clau SSH
La clau SSH és un mecanisme de seguretat que permet l'autenticació segura entre dos sistemes. Per a la connexió amb el servidor d'Amazon EC2, utilitzarem una clau SSH per autenticar-nos. Aquesta clau SSH es pot crear amb la utilitat ssh-keygen que ve amb la majoria de sistemes Linux o podeu fer servir una power shell de Windows.
En aquest mecanisme, el servidor d'Amazon EC2 té la clau pública i el client té la clau privada. Quan el client es connecta al servidor, el servidor comprova si la clau pública del client coincideix amb la clau privada del servidor. Si les claus coincideixen, el client es connecta al servidor. Per tant, la clau privada no s'ha de compartir amb ningú. Mentre que la clau pública es pot compartir amb qualsevol i la podeu fer servir en múltiples servidors. A dia d'avui, no hi ha cap mecanisme per obtenir la claue privada a partir de la clau pública.
Creació de la clau SSH
La comanda ssh-keygen permet crear una clau SSH. Aquesta comanda té diversos paràmetres que permeten personalitzar la clau SSH. Els paràmetres més comuns són:
-t: Especifica el tipus de xifratge de la clau. Els tipus més comuns són rsa, dsa, ecdsa i ed25519.-f: Especifica el nom del fitxer on es guardarà la clau.-b: Especifica la longitud de la clau en bits.
En el nostre cas crearem una clau SSH amb el tipus de xifratge ed25519 i la guardarem al fitxer ~/.ssh/aws-key.
ssh-keygen -t ed25519 -f ~/.ssh/aws-key
Enter passphrase (empty for no passphrase):
Ener same passphrase again:
Nota:
Si no voleu posar una contrasenya a la clau, simplement premeu la tecla
Enterquan us demani la contrasenya.
Aquesta comanda generarà dues claus, una clau privada ~/.ssh/aws-key i una clau pública ~/.ssh/aws-key.pub.
Configuració de la clau SSH a Amazon EC2
-
Inicieu sessió al vostre compte d'Amazon Educate, aneu a moduls del Learner Lab. AWS. Fent clic a Start lab i quan el laboratori estigui en marxa, feu clic a la icona verda per obrir la consola d'Amazon AWS.
-
A la consola d'Amazon AWS, cerqueu KEY PAIRS a la barra de recerca i feu clic a Key Pairs relacionades amb el servei EC2.
-
Feu clic a Actions i seleccioneu Import Key Pair.
-
Copieu el contingut de la clau pública
~/.ssh/aws-key.pubi enganxeu-lo al camp Public key contents.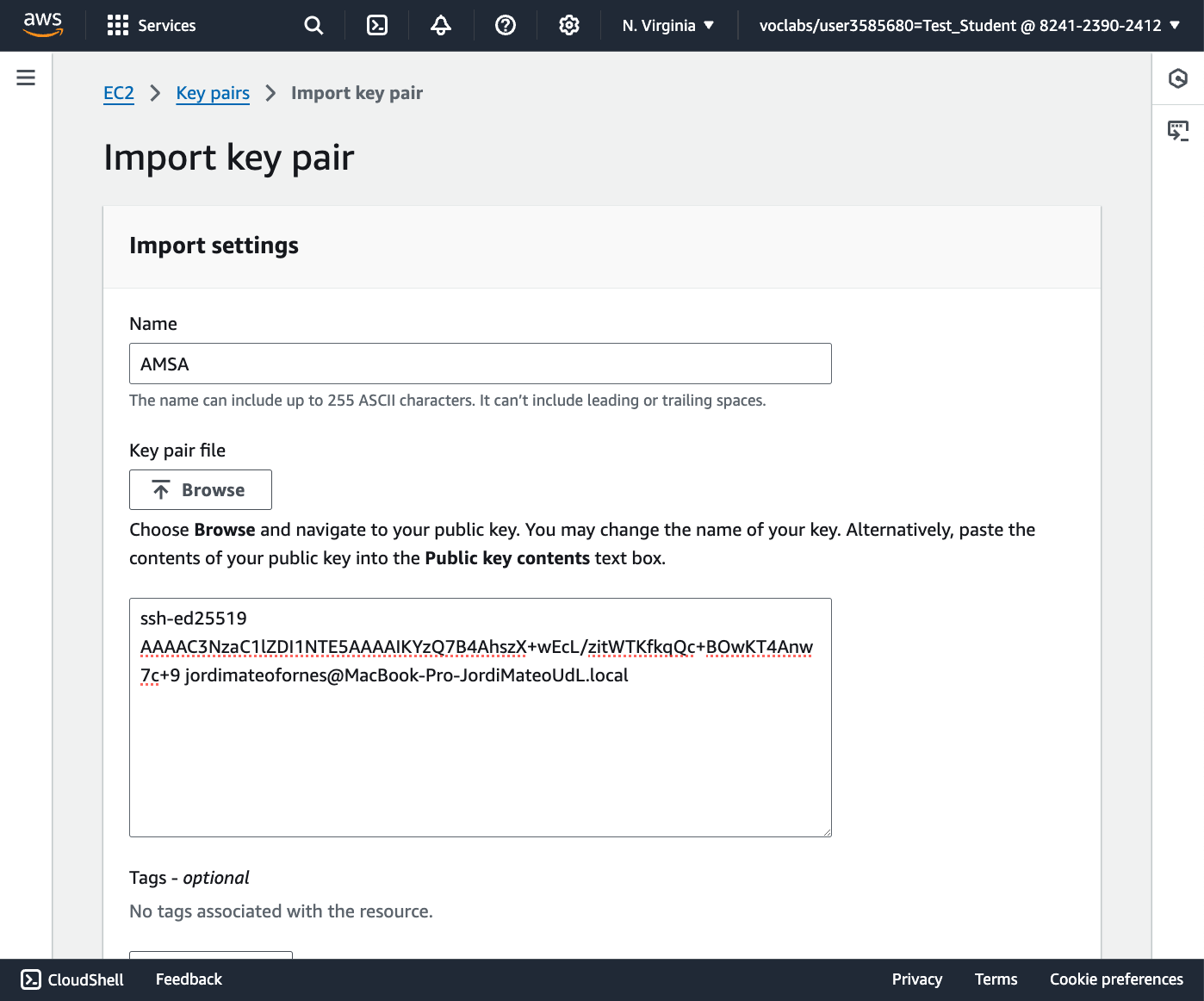
-
Doneu un nom a la clau i feu clic a Import key pair.
-
La clau s'importarà amb èxit i la podreu veure a la llista de claus.
Creació d'una instància EC2
-
Anem a la consola d'Amazon AWS i cerquem EC2 a la barra de recerca.
-
A la consola d'Amazon EC2, fem clic a Launch Instance.
-
Omplim el formulari amb els paràmetres següents:
- Name:
WP-01 - OS:
Amazon Linux 2023 AMI - Instance Type:
t2.micro - Key Pair:
AMSA - Network: Per defecte
- Activeu Allow SSH traffic from anywhere.
- Name:
-
Cliqueu a Launch.
-
Espereu uns minuts fins que la instància estigui en marxa.
-
Un cop en marxa, feu clic al identificador de la instància per veure els detalls.
-
Feu clic a Connect per veure les instruccions per connectar-vos a la instància.
-
Obriu una terminal i connecteu-vos a la instància amb la comanda
ssh -i ~/.ssh/aws-key ec2-user@IP.
-
Si tot ha anat bé, ja esteu connectats a la instància EC2.
-
Un cop connectats, ja podem repetir els passos per instal·lar Apache com vam fer a la màquina local.
sudo dnf install httpd -y sudo systemctl start httpd sudo systemctl enable httpd -
Obriu un navegador i poseu la IP de la instància EC2. En aquest punt, veureu que no podeu accedir a la pàgina web.
- Si reviseu la màquina virtual, observareu que el firewall està desactivat i per tant, no és el culpable.
- El núvol d'Amazon té un firewall per defecte que bloqueja el tràfic a les instàncies. Aquest firewall es diu Security Group i s'ha de configurar per permetre el tràfic HTTP.
-
Anem a la consola d'Amazon EC2 i als detalls de la instància, fem clic a Security i Security Groups.
-
Feu clic a Edit inbound rules i afegiu una regla nova per permetre el tràfic HTTP.
- Type:
HTTP - Source:
Anywhere - Description:
Allow HTTP traffic - Cliqueu a Save rules.
- Type:
-
Torneu a la pàgina web i refresqueu-la. Ara ja veureu la pàgina web d'Apache.
Nota:
Si feu clic als enllaços igual el navegador cerca https i no http. De moment no tenim configurat el certificat SSL i per tant, no funcionarà. Assegureu-vos de posar http a la barra d'adreces i si teniu https, eliminar la s manualment i refrescar la pàgina.
-
Ara ja podem instal·lar PHP igual que vam fer a la màquina local.
sudo dnf install php8.1 -y sudo dnf install php-curl php-zip php-gd php-soap php-intl php-mysqlnd php-pdo -y sudo systemctl restart httpd
Bases de dades RDS
El servei de bases de dades relacional d'Amazon Web Services (RDS) és una opció molt interessant per a desplegar bases de dades MySQL, MariaDB, PostgreSQL, Oracle, SQL Server i Aurora. Aquest servei ofereix una gestió fàcil i eficient de les bases de dades, així com la possibilitat de fer còpies de seguretat, escalabilitat i alta disponibilitat.
Per utiltizar RDS amb WordPress, seguirem els següents passos:
-
Anem a la consola de Amazon RDS.
-
A la consola de Amazon RDS, fem clic a Create database.
- Seleccionem el mode Standard Create.
- Seleccionem el motor de base de dades MySQL.
- Seleccionem la versió de la base de dades MySQL 8.0.25.
- Seleccionem la plantilla Free tier.
- Nom de la base de dades wordpress.
- Master username admin.
- Seleccioneu auto-generate a password.
La resta de paràmetres els deixarem per defecte.
Recordatori:
Fer clic a Connection details per veure la password generada. Si no ho feu, haureu d'anar a modificar, regenerar la password i aplicar els canvis.
-
Espereu uns minuts fins que la base de dades estigui en marxa.
-
Ara ja podem connectar-nos a la base de dades amb un client MySQL com MySQL Workbench o phpMyAdmin.
- Hostname:
database-1.cik8jidkherq.us-east-1.rds.amazonaws.com - Port:
3306 - Username:
admin - Password:
XXXXXXXXXXXXXXX
Nota:
Per simplicitat, instal·larem el client MySQL a la mateixa instància EC2 on tenim instal·lat Apache i PHP.
sudo dnf install mariadb105 -y - Hostname:
-
Un cop connectats, ja podem crear la base de dades wordpress i l'usuari wordpress amb tots els permisos.
mysql -h database-1.cik8jidkherq.us-east-1.rds.amazonaws.com -u admin -pUps! No ens podem connectar a la base de dades. Això és degut a que la base de dades està protegida per un Security Group que no permet connexions des de l'exterior. Per solucionar-ho, hem d'afegir una regla al Security Group de la base de dades per permetre connexions des de la instància EC2.
CREATE DATABASE wordpress; CREATE USER 'wordpress'@'%' IDENTIFIED BY 'wordpress'; GRANT ALL PRIVILEGES ON wordpress.* TO 'wordpress'@'%'; FLUSH PRIVILEGES;
Docker
Fins ara, hem explorat com els administradors de sistemes poden utilitzar la virtualització per crear entorns aïllats i segurs per a les aplicacions. Hem après a crear màquines virtuals, xarxes virtuals i emmagatzematge virtual, comprenent com aquestes tecnologies són útils per desenvolupar entorns de desenvolupament i producció robustos. També hem posat de manifest que la virtualització és una eina fonamental per a la creació de datacenters i la implementació de tecnologies de núvol. En aquesta secció, ens aprofundirem en una evolució significativa: la virtualització mitjançant contenidors.
Els contenidors, a diferència de les màquines virtuals, ofereixen una aproximació més lleugera i eficient a la virtualització. El concepte de contenidor implica la virtualització d'un entorn amb només el programari necessari per a executar una aplicació específica. Considerem, per exemple, la necessitat d'executar programes en Python 2 i Python 3 en el mateix sistema. En lloc de crear una màquina virtual, configurar-la i instal·lar Python 2 i Python 3, podem crear dos contenidors separats, un per a cada versió de Python. Aquests contenidors no contenen un sistema operatiu complet; només integren les llibreries i dependències imprescindibles per a executar Python 2 i Python 3.
Quantes vegades us ha passat que heu fet un desenvolupament ho heu testat a la vostra màquina i quan l'heu passat a producció no ha funcionat? Això és degut a que el vostre entorn de desenvolupament no és igual que l'entorn de producció. Amb els contenidors podem crear un entorn de desenvolupament idèntic a l'entorn de producció, de manera que el que funciona en un entorn també funcionarà en l'altre.
A més a més, penseu que els sistemes canvien constantment. Quantes vegades heu hagut de canviar de sistema operatiu i heu hagut de tornar a configurar tots els vostres programes? Amb els contenidors podem crear un contenidor amb tots els nostres programes i configuracions i executar-lo en qualsevol sistema operatiu que vulguem.
Les diferències principals entre les màquines virtuals i els contenidors es detallen a continuació:
| Característiques | Màquines Virtuals (MV) | Contenidors |
|---|---|---|
| Virtualització | Virtualització completa de Hardware. | Virtualitza el sistema operatiu i els recursos de l'aplicació. |
| Pes i Overhead | Més pesats i requereixen més recursos. | Més lleugers, amb baix overhead i ràpids d'iniciar. |
| Aïllament | Fort aïllament, com màquines físiques separades. | Aïllament lleuger, comparteixen el mateix nucli del sistema. |
| Rendiment | Potencialment menor rendiment a causa de la virtualització completa. | Major rendiment gràcies a la virtualització de sistema. |
| Temps d'inici | Més llarg per iniciar ja que tot el sistema operatiu s'ha de carregar. | Ràpids d'iniciar ja que només es necessiten els recursos específics de l'aplicació. |
| Portabilitat | Menys portables, ja que poden estar lligats a configuracions de hardware específiques. | Més portables, ja que tots els requisits estan inclosos en el contenidor. |
| Escalabilitat | Menys eficients en termes de recursos en entorns amb múltiples màquines virtuals. | Més eficients, ja que comparteixen recursos amb el sistema host. |
| Desenvolupament | Requereix configuració específica i gestió de dependencies. | Més simple i eficient en el desenvolupament, ja que tot està contingut en el contenidor. |
| Utilització de Recursos | Utilitza més recursos a causa de la virtualització completa. | Utilitza menys recursos, ja que comparteixen moltes de les llibreries amb el sistema host. |
Dins d'aquest àmbit, destaca Docker. Docker és una eina de virtualització de contenidors que ofereix una plataforma per a crear, distribuir i executar aplicacions en contenidors. Docker és una eina de codi obert que utilitza la tecnologia de contenidors Linux per a crear i gestionar contenidors virtuals aïllats en un sistema operatiu. És una eina molt popular i és utilitzada per moltes empreses per a crear i gestionar aplicacions en contenidors.
Amb la seva naturalesa multiplataforma, portabilitat i àmplia adopció, Docker s'ha convertit en una eina essencial per als administradors de sistemes moderns.
Instal·lació de Docker a EC2
Docker està disponible per a molts sistemes operatius, incloent-hi Linux, macOS i Windows. En aquesta secció, instal·larem Docker en un sistema Linux. En concret, instal·larem a Amazon Linux 2023.
- Windows: https://docs.docker.com/docker-for-windows/install/
- macOS: https://docs.docker.com/docker-for-mac/install/
- Linux: https://docs.docker.com/engine/install/
Instal·lació de Docker
Per a instal·lar Docker, seguirem els passos següents:
-
Instal·larem el paquet
docker:sudo yum install docker -y -
Activarem i iniciarem el servei de Docker:
sudo systemctl enable --now docker -
Comprovarem que Docker s'ha instal·lat correctament:
docker version -
Per a poder executar comandes de Docker sense necessitat de ser un usuari root, afegirem el nostre usuari al grup
docker:sudo usermod -a -G docker ec2-user newgrp docker # Per a aplicar els canvis -
Actualitzarem els permissos del socket de Docker per permetre als usuaris del grup docker llegir i escriure:
sudo chmod g+rw /var/run/docker.sock
Imatges i contenidors
Una imatge de Docker és un fitxer de lectura que encapsula tots els elements necessaris per executar una aplicació. Aquesta imatge actua com una plantilla utilitzada per crear instàncies específiques conegudes com a contenidors.
Per exemple, en el cas de Python, una imatge de Docker pot contenir el codi font de Python, les llibreries associades i altres dependències requerides per a executar una aplicació Python.
La imatge de Python 3.9 es pot descarregar des del repositori oficial de Docker:
docker pull python:3.9
Aquesta comanda descarrega la imatge de Python 3.9 des del repositori oficial de Docker. Per a comprovar que la imatge s'ha descarregat correctament, podem utilitzar la comanda docker images:
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
python 3.9 1a2b3c4d5e6f 2 minutes ago 128MB
Aquesta comanda llista totes les imatges de Docker al sistema. En aquest cas, només tenim una imatge, la imatge de Python 3.9.
Per poder revisar el dockerfile de la imatge de Python 3.9 podem utilitzar la comanda docker history:
docker history python:3.9 --no-trunc --format "{{.CreatedBy}}"
Amb aquesta comanda podem veure tot el que s'ha fet per crear la imatge de Python 3.9.
Un cop tenim la imatge descarregada, podem crear un contenidor a partir d'aquesta imatge. Un contenidor és una instància en execució d'una imatge. És a dir, un contenidor és un procés en execució aïllat del sistema host que utilitza els recursos de la imatge per a executar una aplicació. Per tant, podem crear múltiples contenidors a partir de la mateixa imatge.Per a crear un contenidor, utilitzarem la comanda docker run amb la següent sintaxi:
docker run <nom_imatge> <ordre>
Per exemple, podem crear un contenidor a partir de la imatge python:3.9 i executar la comanda python --version dins del contenidor:
docker run python:3.9 python --version
Aquesta comanda crea un contenidor a partir de la imatge python:3.9 i executa la comanda python --version dins del contenidor. Aquesta comanda mostra la versió de Python que s'està executant dins del contenidor.
docker run python:3.9 python -c "s = 'Hola món'; print(s)"
Aquesta comanda crea un contenidor a partir de la imatge python:3.9 i executa la comanda python -c "s = 'Hola món'; print(s)" dins del contenidor. Aquesta comanda mostra el text "Hola món" a la consola.
Després d'executar aquestes comandes, el contenidor s'atura de manera automàtica. Ho podem comprovar amb la comanda docker ps -a. Però, i si volem que el contenidor no s'aturi? I poder reaprofitar-lo?
Per a crear un contenidor que s'executi en segon pla, utilitzarem l'opció -d i afegirem l'opció -i per a executar la comanda en mode interactiu (stdin). D'aquesta manera, el contenidor no s'aturarà fins que no l'aturarem manualment.
docker run -d -i python:3.9
Per poder executar comandes dins del contenidor que acabem de crear, necessitarem el seu identificador (CONTAINER ID). Amb aquest identificador, utilitzarem la comanda docker exec per a executar comandes dins del contenidor:
docker exec -it <CONTAINER ID> <ordre>
# En el meu cas el CONTAINER ID és dbd2498d3f1c
docker exec -it dbd2498d3f1c python -c "s = 'Hola món'; print(s)"
docker exec -it dbd2498d3f1c python --version
D'aquesta manera, tenim un contenidor en segon pla que no s'atura i podem executar comandes dins del seu entorn.
Per a aturar el contenidor, utilitzarem la comanda docker stop:
docker stop <CONTAINER ID>
# En el meu cas el CONTAINER ID és dbd2498d3f1c
docker stop dbd2498d3f1c
Per a eliminar el contenidor, utilitzarem la comanda docker rm:
docker rm <CONTAINER ID>
# En el meu cas el CONTAINER ID és dbd2498d3f1c
docker rm dbd2498d3f1c
NOTA: Podeu tenir múltiples contenidors a partir de la mateixa imatge. Amb noms de contenidors diferents.
docker run -di --name python-app-1 python:3.9
docker run -di --name python-app-2 python:3.9
Per aturar i eliminar tots els contenidors, utilitzarem les comandes docker stop i docker rm amb la següent sintaxi:
docker stop $(docker ps -aq) && docker rm $(docker ps -aq)
Personalitzant imatges amb Dockerfile
Una imatge és immutable, però es poden afegir capes per crear noves versions en funció de les necessitats. Per exemple, si necessitem instal·lar una llibreria específica, podem crear una nova imatge que contingui aquesta llibreria. Aquesta imatge es basarà en la imatge original, però amb una nova capa que conté la llibreria que volem instal·lar.
docker run python:3.9 python -c "import numpy as np; print(np.random.rand())"
# ModuleNotFoundError: No module named 'numpy'
Per a crear una nova imatge, utilitzarem un fitxer anomenat Dockerfile. Aquest fitxer conté les instruccions per a crear una imatge de Docker. A continuació, es mostra un exemple de Dockerfile:
# Dockerfile
FROM python:3.9
RUN pip install numpy
En aquest exemple, la primera línia indica que la imatge es basa en una versió específica de Python (3.9). La segona línia executa la comanda pip install per instal·lar la llibreria NumPy. Per a crear una imatge de Docker, utilitzarem la comanda docker build amb la següent sintaxi:
docker build -t <nom_imatge> <directori>
Per crea una imatge de Docker amb el nom python-app:
mkdir python-app
cd python-app
cat << EOF > Dockerfile
FROM python:3.9
RUN pip install numpy
EOF
docker build -t python-app .
cd ..
Per utilitzar la imatge que acabem de crear, utilitzarem la comanda docker run amb la següent sintaxi:
docker run python-app python -c "import numpy as np; print(np.random.rand())"
Compartint dades entre el sistema host i els contenidors
Els contenidors i el sistema host en principi estan aïllats. Però, i si volem compartir dades entre el sistema host i els contenidors? Però i si vull executar un script de Python que està al meu sistema host dins del contenidor?
Per exemple:
mkdir python-project
cd python-project
cat << EOF > hola.py
print("Hola món!")
EOF
Si intentem executar el fitxer hola.py dins del contenidor, obtindrem un error:
docker run python:3.9 python hola.py
# python: can't open file '//hola.py': [Errno 2] No such file or directory
Això és degut a que el fitxer hola.py no existeix dins del contenidor. Per a solucionar aquest problema, utilitzarem l'opció -v per a vincular un fitxer o directori des del sistema host al contenidor:
docker run -v $(pwd):/app python:3.9 python /app/hola.py
Aquesta comanda vincula el directori actual al directori /app del contenidor. D'aquesta manera, podem executar el fitxer hola.py dins del contenidor.
Què passa si ara el script python esciu un fitxer de sortida? Si el fitxer de sortida es crea dins del directori /app del contenidor, com el tenim vinculat al directori actual del sistema host, el fitxer de sortida també es crearà en el sistema host. Això és molt útil per a compartir dades entre el sistema host i els contenidors.
cat << EOF > hola2.py
output = open("/app/sortida.txt", "w")
output.write("Hola món!")
output.close()
EOF
docker run -v $(pwd):/app python:3.9 python /app/hola2.py
Si comprovem el directori actual, veurem que s'ha creat el fitxer sortida.txt:
ls
# hola.py hola2.py sortida.txt
En canvi, si fem el mateix però sense vincular el directori actual al directori /app del contenidor, el fitxer sortida.txt es crearà dins del contenidor i no es compartirà amb el sistema host:
rm sortida.txt
docker run python:3.9 python /app/hola2.py
ls
# hola.py hola2.py
Accedint a un contenidor
Hem vist que els contenidors estan aïllats del sistema host però els podem executar en segon pla i executar comandes dins del seu entorn. Però, i si volem accedir al seu entorn? Per exemple, i si volem accedir a la consola del contenidor?
docker run -it python:3.9 bash
Observem que la consola ha canviat. Això és degut a que ara estem dins del contenidor. Podem comprovar-ho executant la comanda python --version:
python --version
# Python 3.9.7
Per a sortir del contenidor, utilitzarem la comanda exit:
exit
Si volem accedir a un contenidor que està en segon pla, utilitzarem la comanda docker exec amb la següent sintaxi:
docker exec -it <nom_contenidor> <ordre>
# En el meu cas el nom del contenidor cranky_bhabha
docker exec -it cranky_bhabha bash
Cheat Sheet
| Comanda | Descripció |
|---|---|
docker build -t <nom_imatge> <directori> | Construeix una imatge de Docker a partir d'un Dockerfile al directori especificat. |
docker images | Llista totes les imatges de Docker al sistema. |
docker run -d --name <nom_contenidor> -p <port_host>:<port_contenidor> <nom_imatge> | Crea i executa un nou contenidor a partir d'una imatge de Docker. |
docker ps | Llista tots els contenidors en execució. |
docker stop <nom_contenidor> | Atura un contenidor en execució. |
docker rm <nom_contenidor> | Elimina un contenidor. |
docker rmi <nom_imatge> | Elimina una imatge. |
docker exec -it <nom_contenidor> <ordre> | Executa una comanda a l'interior d'un contenidor en execució. |
docker logs <nom_contenidor> | Mostra els registres (logs) d'un contenidor. |
docker inspect <nom_contenidor> | Mostra informació detallada d'un contenidor. |
Emmagatzematge
En el món de Docker, és essencial comprendre com gestionar les dades emmagatzemades pels contenidors, ja que aquests són efímers de manera predeterminada. Les imatges de Docker estan compostes per capes de lectura, i quan s'executa un contenidor, es crea una nova capa d'escriptura temporal. No es persisteixen canvis en aquesta capa d'escriptura, i quan el contenidor es deté o s'elimina, tots els canvis es perden Aquest comportament presenta alguns reptes:
- Com es poden persistir les dades?
- Com es poden compartir entre contenidors?
- Com es poden compartir entre el sistema host i els contenidors?
Volums
Els volums són la manera recomanada de persistir dades generades o utilitzades pels contenidors de Docker, especialment quan la càrrega de treball implica un gran volum de dades, com ara en el cas de bases de dades. Utilitzant volums, les dades persisteixen més enllà del cicle de vida d'un contenidor. Imagineu que tenim un contenidor que executa una base de dades. Si aquest contenidor es deté o s'elimina, les dades de la base de dades es perdran. Per a evitar aquest problema, podem utilitzar volums per a persistir les dades de la base de dades.
Configurant un contenidor per una base de dades no relacional
En aquesta secció, configurarem un contenidor per a una base de dades no relacional. Utilitzarem MongoDB, una base de dades no relacional orientada a documents. MongoDB és una base de dades molt popular i és utilitzada per moltes empreses per a crear i gestionar bases de dades no relacionals.
Per a configurar un contenidor per a MongoDB, seguirem els passos següents:
-
Crearem un directori per a guardar les dades de la base de dades:
mkdir -p /opt/mongodb/data -
Crearem un contenidor per a MongoDB:
docker run -d --name mongodb \ -p 27017:27017 \ -v /opt/mongodb/data:/data/db \ mongo:4Estem creant un contenidor anomenat
mongodba partir de la imatgemongoa la versió 4. Aquest contenidor s'està executant en segon pla (-d) i s'està vinculant el port 27017 del sistema host al port 27017 del contenidor (-p 27017:27017). A més a més, s'està creant un volum anomenat/opt/mongodb/datai s'està vinculant al directori/data/dbdel contenidor (-v /opt/mongodb/data:/data/db). Això permetrà que les dades de la base de dades es guardin al sistema host i no es perdran quan el contenidor es deté o s'elimina. -
Comprovarem que el contenidor s'està executant:
docker ps # CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES # e4c8a84be889 mongo:4 "docker-entrypoint.s…" 7 seconds ago Up 4 seconds 0.0.0.0:27017->27017/tcp, :::27017->27017/tcp mongodb -
Comprovarem que la base de dades està en execució:
docker exec -it mongodb mongoObservem que la consola ha canviat. Això és degut a que ara estem dins del contenidor, concretament de la base de dades mongo. Podem comprovar-ho executant la comanda
db.version():> db.version() # 4.4.26 -
Crearem una base de dades i inserirem un document:
> use testdb # switched to db testdb > db.test.insert({name: "test"}) # WriteResult({ "nInserted" : 1 }) -
Comprovarem que el document s'ha inserit correctament:
> db.test.find() # { "_id" : ObjectId("5f5f5f5f5f5f5f5f5f5f5f5f"), "name" : "test" } -
Sortirem de la consola de MongoDB:
> exit
En aquesta configuració el servei MongoDB és gestionat per un contenidor però les dades són persistents gràcies al volum que hem creat. Això ens permetrà aturar i eliminar el contenidor sense perdre les dades.
-
Per a comprovar-ho, aturem i eliminem el contenidor:
docker stop mongodb docker rm mongodb -
Ara, tornem a crear el contenidor:
docker run -d --name mongodb \ -p 27017:27017 \ -v /opt/mongodb/data:/data/db \ mongo:4 -
I comprovem que la base de dades i el document encara existeixen:
docker exec -it mongodb mongo > use testdb > db.test.find() # { "_id" : ObjectId("5f5f5f5f5f5f5f5f5f5f5f5f"), "name" : "test" } > exit -
També podeu observer el contingut del host:
ls -la /opt/mongodb/data
Els vincles ofereixen una altra opció per accedir a fitxers del sistema host des dins d'un contenidor. Aquesta opció és especialment útil quan necessitem accedir a fitxers específics del sistema host, com ara sistemes de fitxers compartits.
Per exemple, en el cas de la base de dades MongoDB, podem tenir vincles a fitxers de configuració específics del sistema host. Això ens permetrà configurar la base de dades des del sistema host.
docker run -d --name mongodb \
-p 27017:27017 \
-v /opt/mongodb/data:/data/db \
-v /path/to/mongo.conf:/etc/mongo.conf \
mongo:4 --config /etc/mongo.conf
El ftixer /path/to/mongo.conf conté la configuració de MongoDB. Aquest fitxer es troba al sistema host i es vincula al contenidor. Això permet que el fitxer de configuració es mantingui al sistema host i no es perdi quan el contenidor es deté o s'elimina.
Controladors d'emmagatzematge
Els controladors d'emmagatzematge es fan servir per emmagatzemar les diferents capes i per desar dades a la capa d'escriptura d'un contenidor. En general, els controladors d'emmagatzematge estan implementats amb l'objectiu d'optimitzar l'ús d'espai, però la velocitat d'escriptura pot ser més baixa que el rendiment del sistema de fitxers, depenent del controlador que s'estigui utilitzant. Per defecte s'utiltiza el controlador anomenat overlay2, el qual està basat en OverlayFS.
Per a comprovar quin controlador d'emmagatzematge s'està utilitzant, utilitzarem la comanda docker info:
docker info | grep Storage
# Storage Driver: overlay2
Per a canviar el controlador d'emmagatzematge, utilitzarem la comanda dockerd amb la següent sintaxi:
dockerd --storage-driver <controlador>
Existeixen diferents controladors d'emmagatzematge. A continuació, es mostra una llista dels controladors d'emmagatzematge més utilitzats:
| Overlay2 | ZFS | Btrfs | Device Mapper | VFS | |
|---|---|---|---|---|---|
| Suport per Còpia d'Esriptura (Copy-on-Write) | Sí | Sí | Sí | Sí | No |
| Rendiment d'Esriptura | Mitjà/Alt | Alt | Alt | Mitjà/Alt | Baix |
| Optimització d'Espai | Sí | Sí | Sí | Sí | No |
| Suport de Volums | Sí | Sí | Sí | Sí | Sí |
| Compatibilitat (amb altres sistemes de fitxers) | Bona | Bona | Bona | Bona | Excel·lent |
| Velocitat de Llegir (Read Speed) | Alta | Molt Alta | Alta | Mitjà/Alta | Alta |
| Suport a Instantànies (Snapshots) | No | Sí | No | Sí | No |
| Compressió i Deduplicació | No | Sí | No | Sí | No |
| Replicació de Dades | No | Sí | No | Sí | No |
| Recomanat per a Producció | Sí | Depèn de la configuració | No | Depèn de la configuració | No |
Xarxes
Els contenidors de Docker poden utilitzar xarxes per a comunicar-se entre ells. Aquesta comunicació pot ser entre contenidors en el mateix sistema host o entre contenidors en diferents sistemes host. Això permet que els contenidors es comuniquin entre ells i amb el sistema host.
Per defecte, Docker crea una xarxa virtual per a cada contenidor. Aquesta xarxa és privada i només els contenidors que pertanyen a la mateixa xarxa poden comunicar-se entre ells. Aquesta xarxa és creada automàticament per Docker i no es pot eliminar.
Per a crear una xarxa de contenidors, utilitzarem la comanda docker network create:
docker network create my-network
Aquesta comanda crea una xarxa de contenidors amb el nom my-network. Per a comprovar que la xarxa s'ha creat correctament, podem utilitzar la comanda docker network ls:
docker network ls
NETWORK ID NAME DRIVER SCOPE
1a2b3c4d5e6f bridge bridge local
7a8b9c0d1e2f host host local
3a4b5c6d7e8f my-network bridge local
Ara, crearem dos contenidors i els afegirem a la xarxa my-network:
docker run -d --name nginx --network my-network nginx
docker run -d --name apache --network my-network httpd
Aquests contenidors s'han creat a partir de les imatges nginx i httpd i s'han afegit a la xarxa my-network. Per a comprovar que els contenidors s'han creat correctament, podem utilitzar la comanda docker ps:
docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1a2b3c4d5e6f nginx "nginx -g 'daemon of…" 2 minutes ago Up 2 minutes 80/tcp nginx
7a8b9c0d1e2f httpd "httpd-foreground" 2 minutes ago Up 2 minutes 80/tcp apache
Aquesta xarxa és privada i només els contenidors que pertanyen a la mateixa xarxa poden comunicar-se entre ells. Podem comprovar-ho executant la comanda docker exec:
docker exec -it nginx curl http://apache
Aquesta comanda executa la comanda curl dins del contenidor nginx i comprova que pot comunicar-se amb el contenidor apache. Ara bé, si fem un curl des del sistema host al contenidor apache no funcionarà:
curl http://apache
curl: (6) Could not resolve host: apache
Si volem que els contenidors puguin comunicar-se amb el sistema host, hem d'utilitzar l'opció --publish o -p:
docker run -d --name nginx --network my-network -p 8080:80 nginx
docker run -d --name apache --network my-network -p 8081:80 httpd
Aquesta comanda crea un contenidor a partir de la imatge nginx i l'afegeix a la xarxa my-network. A més a més, el contenidor està escoltant en el port 80 del sistema host. Si accediu utiltizant un navegador a http://127.0.0.1:8080 o http://127.0.0.1:8081 observareu que els dos contenidors estan funcionant. Els dos utilitzen el port 80 del seu contenidors, però es mappegen a diferents ports del sistema host.
Variables d'entorn
Els contenidors de Docker poden utilitzar variables d'entorn per a configurar el seu comportament. Les variables d'entorn són variables dinàmiques que poden afectar el comportament d'un procés en un sistema. Aquestes variables s'utilitzen per a configurar el comportament del procés i són especialment útils per a passar informació a les aplicacions.
Imaginem que volem modificar el comportament d'un procés. Per exemple, volem modificar el comportament d'un procés de Python. Per a fer-ho, podem utilitzar variables d'entorn. A continuació, es mostra un exemple de com utilitzar variables d'entorn per a modificar el comportament d'un procés de Python:
cat << EOF > hola3.py
import os
print("Hola " + os.environ["NOM"] + "!")
EOF
docker run -v $(pwd):/app --env NOM=Joan python:3.9 python /app/hola3.py
Dockeritzant aplicacions
OBSERVACIÓ: Una tasca fonamental és dockeritzar les vostres aplicacions. Això us permetrà tenir un entorn de desenvolupament idèntic a l'entorn de producció. A més a més, us permetrà compartir les vostres aplicacions amb altres persones de manera senzilla. Per a més informació, podeu consultar la documentació oficial de Docker: Dockerfile reference.
Sintaxi de Dockerfile
A continuació, es mostra la sintaxi bàsica d'un Dockerfile:
# Imatge base que s'utilitzarà com a punt de partida
FROM <nom_imatge>
# Executa una comanda durant la construcció de la imatge
RUN <ordre>
# Defineix una variable d'entorn que pot ser utilitzada durant l'execució del contenidor
ENV <variable_entorn>=<valor>
# Estableix el directori de treball per a les comandes següents
WORKDIR <directori>
# Vincula un fitxer o directori des del sistema host al contenidor
COPY <fitxer|directori> <directori>
# Comanda per defecte que s'executarà quan es crei un contenidor basat en aquesta imatge
CMD ["<ordre>"]
# Etiqueta amb metadades per proporcionar informació addicional
LABEL <clau>=<valor>
# Crea un volum per emmagatzemar dades fora del contenidor
VOLUME <directori>
# Indica quin port exposarà el contenidor (no obre realment el port, només és informatiu)
EXPOSE <port>
# Especifica l'usuari que s'executarà en el contenidor
USER <usuari>
# Punt d'entrada per a l'aplicació. Sobreescriu la comanda CMD
ENTRYPOINT ["<ordre>"]
# Arguments per passar a l'ENTRYPOINT
# (Útil quan vols parametritzar l'entrada a l'aplicació)
ARGS ["<argument1>", "<argument2>"]
Imagineu que tenim un projecte de Python amb la següent estructura:
.
├── main.py
└── requirements.txt
on requirements.txt conté les dependències del projecte:
cat << EOF > requirements.txt
numpy==1.21.2
EOF
i main.py conté el codi font de l'aplicació:
cat << EOF > main.py
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
print(a + b)
EOF
Per a dockeritzar aquest projecte, crearem un fitxer anomenat Dockerfile amb la següent sintaxi:
FROM python:3.9
COPY . /app
WORKDIR /app
RUN pip install -r requirements.txt
CMD ["python", "main.py"]
En aquest exemple, la primera línia indica que la imatge es basa en una versió específica de Python (3.9). La segona línia copia el codi font de l'aplicació a la imatge. La tercera línia estableix el directori de treball de la imatge. La quarta línia executa la comanda pip install per instal·lar les dependències de l'aplicació. Finalment, la cinquena línia executa l'aplicació quan es crea un contenidor.
Ara l'estructura del projecte és la següent:
.
├── Dockerfile
├── main.py
└── requirements.txt
Per a crear una imatge de Docker, utilitzarem la comanda docker build amb la següent sintaxi:
docker build -t <nom_imatge> -f <fitxer> <directori>
# Ens situem al directori que volem dockeritzat
docker build -t python-app -f Dockerfile .
Aquesta comanda crea una imatge de Docker amb el nom python-app a partir del directori actual. Per verificar que la imatge s'ha creat amb èxit, podem utilitzar la comanda docker images. Per a comprovar que l'aplicació funciona correctament, crearem un contenidor a partir de la imatge python-app:
docker run python-app
# [5 7 9]
Exercisis amb Docker i Docker Compose
-
Donada la següent aplicació en Python:
import falcon class Item: def __init__(self, id, name): self.id = id self.name = name items = [ Item(1, "Item 1"), Item(2, "Item 2"), Item(3, "Item 3"), ] class ItemListResource: def on_get(self, req, resp): resp.media = [{"id": item.id, "name": item.name} for item in items] class ItemResource: def on_get(self, req, resp, item_id): item = next((i for i in items if i.id == int(item_id)), None) if item: resp.media = {"id": item.id, "name": item.name} else: resp.status = falcon.HTTP_404 resp.media = {"error": "Item not found"} app = falcon.App() app.add_route('/items', ItemListResource()) app.add_route('/items/{item_id}', ItemResource())Per executar l'aplicació, es pot fer servir el següent script:
gunicorn -b 0.0.0.0:8000 app:appOn
appés el nom del fitxer on es troba l'aplicació.A més, sabem que l'aplicació necessita les següents llibreries:
falconigunicornen les versions 3.0.0 i 20.1.0 respectivament.La teva tasca és crear un Dockerfile per a aquesta aplicació i un fitxer Makefile que permeti construir la imatge i executar-la.
-
Analitza el següent projecte Dockeritzat Laboratoris i desplega'l en el teu entorn de desenvolupament.
-
Crea un fitxer
docker-compose.ymlque permeti desplegar 3 aplicacions web diferents, i un servidor nginx que faci de balancejador de càrrega entre elles. Per fer-ho, farem servir aplicacions web molt senzilles en Python amb Flask. A continuació, es mostren els fitxers de les aplicacions:from flask import Flask app = Flask(__name__) @app.route('/') def home(): return "Hello from App 1!" if __name__ == "__main__": app.run(host="0.0.0.0", port=5000)Nota: Per instal·lar docker-compose a Amazon linux 2023, es pot fer servir el següent script:
sudo curl -L https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-compose -
A la feina us han demanat una arquitectura de desplegament escalable i portable per desenvolupar una app web que fa consultes a una base de dades. La estructura del projecte és la següent:
web-app/ ├── app/ │ ├── main.py │ ├── models.py │ ├── database.py │ ├── schemas.py │ ├── requirements.txt ├── db/ │ ├── init.sqlEl requísits són els següents:
- La base de dades ha de ser MySQL a la versió 5.7.
- La aplicació web ha de ser en Python 3.9 utiltizant les següents llibreries:
- fastapi==0.95.1
- uvicorn==0.22.0
- SQLAlchemy==2.0.21
- pymysql==1.0.3
- cryptography==35.0.0
On
main.pyés el següent:from fastapi import FastAPI, HTTPException, Depends from sqlalchemy.orm import Session import models, schemas, database # Crear l'aplicació FastAPI app = FastAPI() # Crear les taules de la base de dades models.Base.metadata.create_all(bind=database.engine) # Ruta inicial @app.get("/") def read_root(): return {"message": "Hello World"} # Ruta per obtenir un element @app.get("/items/{item_id}", response_model=schemas.Item) def read_item(item_id: int, db: Session = Depends(database.get_db)): item = db.query(models.Item).filter(models.Item.id == item_id).first() if item is None: raise HTTPException(status_code=404, detail="Item not found") return item # Ruta per crear un nou element @app.post("/items/", response_model=schemas.Item) def create_item(item: schemas.ItemCreate, db: Session = Depends(database.get_db)): db_item = models.Item(**item.dict()) db.add(db_item) db.commit() db.refresh(db_item) return db_itemi models.py:
from sqlalchemy import Column, Integer, String, Float from sqlalchemy.ext.declarative import declarative_base Base = declarative_base() class Item(Base): __tablename__ = "items" id = Column(Integer, primary_key=True, index=True) name = Column(String(50), index=True) description = Column(String(255)) price = Column(Float) tax = Column(Float, nullable=True)i schemas.py:
from pydantic import BaseModel class ItemBase(BaseModel): name: str description: str price: float tax: float = None class ItemCreate(ItemBase): pass class Item(ItemBase): id: int class Config: orm_mode = Truei database.py:
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker SQLALCHEMY_DATABASE_URL = "mysql+pymysql://root:password@db:3306/testdb" engine = create_engine(SQLALCHEMY_DATABASE_URL) SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine) def get_db(): db = SessionLocal() try: yield db finally: db.close()i init.sql:
CREATE DATABASE IF NOT EXISTS testdb; USE testdb; CREATE TABLE IF NOT EXISTS items ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50) NOT NULL, description TEXT, price FLOAT NOT NULL, tax FLOAT );
Dockeritzant NGINX
A classe hem utilitzat docker-compose per a desplegar 3 aplicacions web diferents: app1, app2 i app3 en una instancia EC2 d'AWS.
Configurant de l'entorn multi-aplicació
En primer lloc, hem creat les aplicacions web amb Flask. Aquí teniu un exemple del codi per a app1:
```python
from flask import Flask
app = Flask(__name__)
@app.route('/')
def home():
return "Hello from App 1!"
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
```
A continuació, hem creat el fitxer Dockerfile per cada aplicació:
FROM python:3.9
WORKDIR /app
COPY app.py .
RUN pip install flask
CMD ["python", "app.py"]
Per app2 i app3, hem fet el mateix, simplement modificant el missatge de retorn. L'estructura de les aplicacions és la següent:
app1/
├── app.py
└── Dockerfile
app2/
├── app.py
└── Dockerfile
app3/
├── app.py
└── Dockerfile
Un cop preparades les aplicacions, hem creat un fitxer docker-compose.yml per orquestrar els nostres serveis:
version: '3.9'
services:
app1:
build: ./app1
container_name: app1
ports:
- "5001:5000"
app2:
build: ./app2
container_name: app2
ports:
- "5002:5000"
app3:
build: ./app3
container_name: app3
ports:
- "5003:5000"
Amb aquest fitxer, hem desplegat els serveis mitjançant docker-compose up -d. Per accedir a les aplicacions, hem utilitzat la IP pública de la instància EC2 i el port corresponent de cada aplicació.
Nota 1: Recordeu d'obrir els ports corresponents a les aplicacions a la instància EC2 (5001, 5002 i 5003).
Nota 2: Recordeu que si feu modificacions als contenidors, heu de fer
docker-compose up --build -dper aplicar els canvis.
Amb aquesta configuració, hem pogut accedir a les aplicacions a través de http://ip:5001, http://ip:5002 i http://ip:5003. Per aconseguir-ho, hem afegit nginx com a proxy invers al nostre docker-compose.yml:
Configurant NGINX com a proxy invers
Per evitar accedir a diferents ports per a cada aplicació, l'Alberto ens va suggerir utilitzar un únic punt d'entrada. Així, podem accedir a les aplicacions a través de http://ip/app1, http://ip/app2 i http://ip/app3.
- Actualitzeu el vostre
docker-compose.ymlamb el següent contingut:
version: '3.9'
services:
app1:
build: ./app1
container_name: app1
ports:
- "5001:5000"
app2:
build: ./app2
container_name: app2
ports:
- "5002:5000"
app3:
build: ./app3
container_name: app3
ports:
- "5003:5000"
nginx:
image: nginx:latest
container_name: nginx
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf
ports:
- "80:80"
- Inicialment hem configurat
nginxde la següent manera:
events {}
http {
server {
listen 80;
location / {
proxy_pass http://127.0.0.1:5001;
}
location /app1/ {
proxy_pass http://127.0.0.1:5001;
}
location /app2/ {
proxy_pass http://127.0.0.1:5002;
}
location /app3/{
proxy_pass http://127.0.0.1:5003;
}
}
}
No obstant això, després de desplegar-ho, vam observar que les aplicacions no funcionaven i apareixien errors de connection refused. Consultant els logs a través de docker logs nginx, vam veure que nginx no podia connectar-se als contenidors de les aplicacions.
El problema rau en el fet que nginx, al ser un contenidor, no pot utilitzar 127.0.0.1 per connectar-se als altres serveis, ja que aquest localhost és específic del contenidor nginx i no de la instància EC2. Si el servidor nginx fos a la instància EC2, aquesta configuració hauria estat correcta.
Per solucionar-ho, hem actualitzat la configuració de nginx per utilitzar els noms dels serveis definits a docker-compose.yml, que són accessibles dins de la xarxa de contenidors:
events {}
http {
server {
listen 80;
location / {
proxy_pass http://app1:5000/;
}
location /app1/ {
proxy_pass http://app1:5000/;
}
location /app2/ {
proxy_pass http://app2:5000/;
}
location /app3/{
proxy_pass http://app3:5000/;
}
}
}
Amb aquesta configuració, nginx utilitza la xarxa interna de Docker per comunicar-se amb els serveis. Un cop implementats els canvis, podem accedir a les aplicacions a través de:
http://ip/app1http://ip/app2http://ip/app3
Nota: Ara només cal obrir el port 80 a la instància EC2, ja que nginx redirigeix les peticions al port correcte dins de la xarxa de contenidors. Els ports 5001, 5002 i 5003 ja no són necessaris a AWS.
Amb aquesta configuració, hem aconseguit desplegar 3 aplicacions web diferents amb un únic punt d'entrada, gràcies a nginx com a proxy invers.
AWS S3
Amazon Simple Storage Service (S3) és un servei de magatzematge d'objectes que ofereix escalabilitat, disponibilitat i durabilitat. Aquest servei permet emmagatzemar i recuperar dades a través d'una interfície web.
Per a més informació, consulta la documentació oficial d'Amazon S3.
La capa gratuita d'AWS inclou 5 GB de magatzematge d'objectes, 20.000 sol·licituds GET i 2.000 sol·licituds PUT al mes. Superades aquestes limitacions, es facturaran segons el consum.
Configuració d'una instància EC2 per accedir a S3
Per accedir a S3 des d'una instància EC2, primer cal configurar les credencials d'accés a S3 a la instància. Aquests són els passos a seguir:
-
Executa el següent comandament per configurar les credencials AWS a la instància:
aws configureCompleta els camps amb les teves credencials:
AWS Access Key ID [None]: <ACCESS_KEY> AWS Secret Access Key [None]: <SECRET_KEY> Default region name [None]: us-east-1 Default output format [None]: None
-
Alternativament, pots configurar directament la teva
Access Token:aws configure set aws_session_token <ACCESS_TOKEN>
Un cop configurades les credencials, la instància EC2 estarà preparada per accedir a S3.
Nota: Per obtenir les credencials d'accés a AWS, heu de visitar AWS Details.
Operacions bàsiques amb S3
-
Copiar un document d'EC2 a S3:
echo "Hello World" > file.txt aws s3 cp file.txt s3://<bucket-name>/file.txt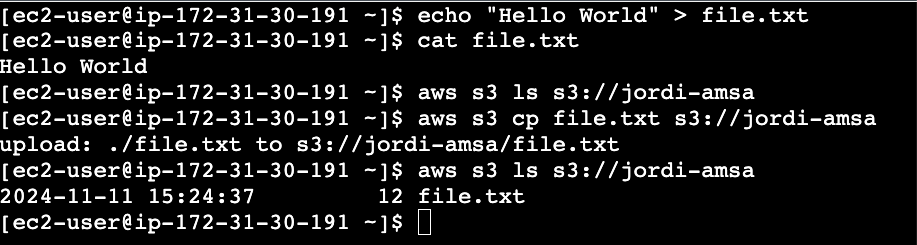
-
Copiar un document de S3 a EC2:
# Assumeix que `a.txt` ja existeix a S3. dir=/home/ec2-user aws s3 cp s3://<bucket-name>/a.txt $dir/a.txt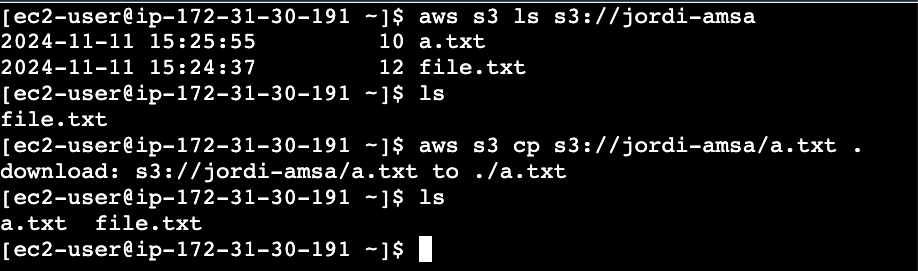
-
Crear una carpeta a S3:
aws s3 mb s3://<bucket-name>/folder -
Eliminar un document de S3:
aws s3 rm s3://<bucket-name>/file.txt -
Eliminar documents de S3 de manera recursiva:
aws s3 rm s3://<bucket-name>/ --recursive -
Llistar els documents d'un bucket de S3:
aws s3 ls s3://<bucket-name> -
Llistar els documents d'un bucket de S3 de forma recursiva:
aws s3 ls s3://<bucket-name> --recursive -
Sincronitzar un directori local amb un bucket de S3:
aws s3 sync /home/ec2-user s3://<bucket-name> -
Sincronitzar un bucket de S3 amb un directori local:
aws s3 sync s3://<bucket-name> /home/ec2-user
Per exemple, podem descarregar un notebook de Jupyter a la instància EC2 i pujar-lo a S3 sincronitzant la carpeta local (notebooks) amb el bucket de S3 (jordi-amsa/notebooks):
aws s3 mb s3://jordi-amsa/notebooks
mkdir notebooks
cd notebooks
wget https://github.com/JordiMateoUdL/Model-reusability-on-the-edge/blob/master/notebooks/Generating%20synthethic%20data.ipynb
mv 'Generating synthethic data.ipynb' notebook1.ipynb
aws s3 sync notebooks s3://jordi-amsa/notebooks

Xarxa a AWS
Virtual Private Cloud (VPC)
Una VPC és una xarxa virtual que es pot configurar a AWS. Per defecte, AWS crea una VPC per a cada compte, però també es poden crear noves VPCs. Una VPC es pot configurar amb subxarxes, taules de rutes, grups de seguretat, etc.
En la imatge es mostren 4 VPCs diferents. Cada VPC està aïllada de les altres. Una VPC es crea dins d'una regió específica i pot abastar múltiples zones de disponibilitat dins d'aquesta regió.
A més, en l'arquitectura de la imatge, el tràfic es comparteix entre dues VPCs a la mateixa regió però en diferents zones de disponibilitat. No obstant això, les VPCs de les regions 1 i 2 no poden connectar-se entre elles.
Per crear una VPC, es pot utilitzar la consola de AWS, la interfície de línia de comandes o l'API de AWS.
-
Consola de AWS:
- Anar a la consola de AWS.
- Anar a la secció de VPC.
- Seleccionar "Your VPCs".
- Clicar a "Create VPC".
- Omplir els camps necessaris.
- Clicar a "Create VPC".
-
Interfície de línia de comandes:
aws ec2 create-vpc --cidr-block 10.0.0.0/16 --region us-east-1 --tag-specifications "ResourceType=vpc,Tags=[{Key=Name,Value=amsa-vpc}]"
En aquest exemple, s’utilitza una màscara de xarxa /16, que permet disposar de fins a 65,536 adreces IP. No obstant això, algunes d’aquestes IP seran reservades per AWS per a serveis interns, de manera que el nombre efectiu d’adreces disponibles serà lleugerament inferior.
Per defecte, les VPC no tenen connexió a Internet. Per proporcionar accés, es poden configurar una Internet Gateway (IGW) per connectar la VPC a Internet o una Virtual Private Gateway (VGW) per connectar-la a una xarxa privada, com una VPN. Aquestes passarel·les permeten establir la connectivitat necessària segons les necessitats de l'entorn de xarxa.
Subxarxes
Les subxarxes són una part d'una VPC. Una VPC pot tenir múltiples subxarxes. Cada subxarxa es pot configurar amb una zona de disponibilitat específica. Això permet distribuir les càrregues de treball en diferents zones de disponibilitat. Un exemple útil de subxarxes és la creació de subxarxes públiques i privades en funció de les necessitats de seguretat i operacionals.

En la imatge es mostra una VPC amb un bloc CIDR de 10.0.0.0/24 que suporta 256 adreces IP. Aquest bloc CIDR es pot dividir en dues subxarxes, cadascuna amb 128 adreces IP. Una subxarxa utilitza el bloc CIDR 10.0.0.0/25 (per a les adreces 10.0.0.0 - 10.0.0.127) i l'altra utilitza el bloc CIDR 10.0.0.128/25 (per a les adreces 10.0.0.128 - 10.0.0.255).
Per crear una subxarxa, es pot utilitzar la consola de AWS, la interfície de línia de comandes o l'API de AWS.
-
Consola de AWS:
- Anar a la consola de AWS.
- Anar a la secció de VPC.
- Seleccionar "Subnets".
- Clicar a "Create subnet".
- Omplir els camps necessaris.
- Clicar a "Create subnet".
-
Interfície de línia de comandes:
aws ec2 create-subnet --vpc-id <vpc-id> --cidr-block 10.0.1.0/24 --availability-zone us-east-1a # Per exemple: # aws ec2 create-subnet --vpc-id vpc-013ece49204bdf533 --cidr-block 10.0.1.0/24 --availability-zone us-east-1a
Desplegant una EC2 a una VPC
En aquesta activitat, es desplegarà una VPC amb dues subxarxes, una pública i una privada. A més, es configurarà una Internet Gateway per connectar la VPC a Internet.
En aquesta figura, es mostra una VPC amb dues subxarxes, una pública i una privada. La subxarxa pública té una connexió a Internet a través d'una Internet Gateway. La subxarxa privada no té connexió a Internet. Per defecte, les VPC no tenen connexió a Internet. Per proporcionar accés, es poden configurar una Internet Gateway (IGW) i una taula de rutes per connectar la VPC a Internet.
Per desplegar aquesta arquitectura, es pot utilitzar CloudFormation. A continuació, es mostra un exemple de plantilla de CloudFormation per desplegar aquesta arquitectura.
-
Creació del Internet Gateway (IGW):
- Anar a VPC > Internet Gateways.
- Clicar a "Create internet gateway".
- Omplir els camps necessaris (AMSA-IGW).
- Attach el AMSA-IGW a AMSA-VPC.
-
Crear l'enrutador de la taula de rutes:
- Anar a VPC > Route Tables.
- Clicar a "Create route table".
- Nom: AMSA-PublicNet-RT-TO-Internet.
- VPC: AMSA-VPC.
- Clicar a "Edit routes".
- Afegir una nova ruta:
- Destination: 0.0.0.0/0.
- Target: AMSA-IGW.
Cadascuna de les subxarxes de la VPC es pot associar a una taula de rutes. Una subxarxa es pot associar explícitament a una taula de rutes personalitzada o implícitament a la taula de rutes principal.
-
Una associació explícita implica que una subxarxa està associada a una taula de rutes personalitzada. En l'exemple, la subxarxa pública està associada a la taula de rutes personalitzada AMSA-PublicNet-RT-TO-Internet, que redirigeix tot el tràfic a l'Internet Gateway. Aquesta associació explícita fa que la subxarxa sigui una subxarxa pública.
-
Una associació implícita implica que la subxarxa està associada a la taula de rutes principal. En l'exemple, la subxarxa privada està associada a la taula de rutes principal, que redirigeix tot el tràfic al Virtual Private Gateway. No obstant això, no té una ruta a l'Internet Gateway, fent que la subxarxa sigui una subxarxa només per a VPN.
La diferència clau entre les associacions explícites i implícites rau en la taula de rutes implicada. La taula de rutes principal està associada implícitament a totes les subxarxes de la VPC, mentre que les taules de rutes personalitzades estan associades explícitament a subxarxes específiques.
La imatge mostra una arquitectura de xarxa dins d’una VPC, amb una configuració que inclou subxarxes, taules de rutes, gateways per connectar un entorn privat a Internet i a un centre de dades mitjançant una VPN.
-
Subxarxa pública: En aquesta subxarxa és on es troben les instàncies EC2 accessibles des d’Internet. Té una associació explícita amb una taula de rutes (Route Table A) que inclou una ruta cap a l'Internet Gateway, permetent a les instàncies connectar-se a Internet. Està associada amb el Security Group A, que defineix les polítiques de seguretat per a les instàncies en aquesta subxarxa.
-
Subxarxa privada: En aquesta subxarxa és per a recursos que necessiten seguretat addicional i que no haurien de ser accessibles directament des d'Internet. Té una associació implícita amb una taula de rutes (Route Table B), que no inclou una ruta cap a l'Internet Gateway, de manera que les instàncies no poden accedir a Internet directament. Està associada amb el Security Group B, que gestiona les regles de seguretat d'aquest entorn privat.
Per tant, la taula de rutes A permet a les instàncies de la subxarxa pública accedir a Internet a través de l'Internet Gateway, mentre que la taula de rutes B permet a les instàncies de la subxarxa privada comunicar-se amb el centre de dades corporatiu a través de la VPN Gateway.
Nota: La VPN Connection és el túnel que connecta la VPN Gateway de la VPC amb el Customer Gateway situat al centre de dades corporatiu. El Customer Gateway és un dispositiu de xarxa (pot ser un router o un firewall) situat a les instal·lacions del client, que gestiona el trànsit cap a la VPC. Aquesta configuració permet als recursos de la subxarxa privada accedir al centre de dades corporatiu i viceversa, de manera segura, sense exposar aquests recursos a Internet.
Desplegant Wordpress a una VPC Privada
-
Creació de la VPC i les Subxarxes
- Crea una VPC amb un rang d'adreces IP, per exemple, 10.0.0.0/16.
- Configura dues subxarxes públiques per a les instàncies de l'aplicació a diferents zones de disponibilitat (AZ).
- Subxarxa 1 (pública) en AZ 1 amb rang d'IP 10.0.1.0/24 (us-east-1a).
- Subxarxa 2 (pública) en AZ 2 amb rang d'IP 10.0.2.0/24 (us-east-1b).
- Configura una subxarxa privada per a la base de dades en una zona de disponibilitat específica. (us-east-1c).
-
Configuració de la Taula de Rutes
- Crea una Internet Gateway i associa-la amb la VPC.
- Configura una taula de rutes per a les subxarxes públiques (HDCB-APPS-R1 i HDCB-APPS-R2).
- Configura una taula de rutes separada per la subxarxa privada (HDCB-DATA-R). Aquesta taula no tindrà rutes a Internet. Només tindrà rutes per accedir internament als recursos de la VPC.
-
Configuració del Balancer de Càrrega (Load Balancer)
- Crea un Application Load Balancer (ALB) i selecciona les dues subxarxes públiques.
- Configura el balançador perquè escolti al port 80 per HTTP.
- Crea un grup objectiu (Target Group) per a les instàncies de l'aplicació.
- Defineix L'objectiu com a Instances i el protocol com a HTTP al port 80.
- Assigna les instàncies que crearem a continuació al grup objectiu perquè el balançador distribueixi el tràfic entre elles.
-
Crea Instàncies EC2 per a Wordpress una a cada instància.
Arquitectura Escalable per a WordPress
En aquesta pràctica, dissenyarem i implementarem una arquitectura escalable i segura per a una aplicació WordPress, utilitzant els serveis d’AWS. Aquesta arquitectura constarà dels següents components:
-
Balancejador de Càrrega (Load Balancer): Serà responsable de distribuir uniformement el tràfic entrant entre múltiples instàncies EC2. Això assegura una alta disponibilitat i resiliència davant augments de càrrega.
-
Instàncies EC2: Aquestes màquines virtuals allotjaran l’aplicació WordPress. Estaran dins d’un grup d’autoscaling, que permetrà ajustar dinàmicament el nombre d’instàncies en funció de la demanda.
-
Base de Dades RDS: Utilitzarem Amazon RDS per gestionar la base de dades de WordPress.
Tasques
- Creació de la VPC i les subxarxes
- Taules d'Enrutament i Associacions
- Grups de Seguretat
- Creació de la Base de Dades RDS
- Creació de l'instància EC2
- Wordpress
- Balancejador de Càrrega
- Configuració VPN
Cloud Formation
Us he preparat diferents fitxers de plantilles de CloudFormation per a desplegar diferents versions de la infraestructura.
- Versió 1: En aquesta versió es desplegarà la VPC, les subxarxes, els grups de seguretat, la base de dades RDS i les instàncies EC2. No s'instal·larà WordPress. A més a més, es crearan les taules d'enrutament i les associacions necessàries. Podeu trobar el fitxer de plantilla a infra_v1.yaml.
Creació de la VPC i les subxarxes
Com a primer pas per a la nostra arquitectura, definirem una VPC (Virtual Private Cloud). La configurarem amb la xarxa 10.0.0.0/16, la qual ens proporciona fins a 65.536 adreces IP, més que suficients per al nostre cas d'ús.
Podem definir la VPC utilitzant AWS CloudFormation amb el següent codi YAML:
AMSAVPC:
Type: AWS::EC2::VPC
Properties:
CidrBlock: 10.0.0.0/16
Tags:
- Key: Name
Value: AMSA-VPC
Alternativament, també podem crear-la manualment a través de la interfície web d'AWS, utilitzant els formularis disponibles:
Nota: Si a la plantilla de CloudFormation no especifiquem cap zona de disponibilitat, la VPC es crearà a la zona de disponibilitat per defecte de la regió seleccionada. Per a més informació sobre els paràmetres de la VPC, podeu consultar la documentació d'AWS.
Creació de les subxarxes
A continuació, afegirem les subxarxes necessàries per a la nostra arquitectura. Cadascuna estarà associada a una zona de disponibilitat diferent per garantir alta disponibilitat:
-
AMSA-Front-01: Subxarxa privada per a les instàncies de WordPress a la zona de disponibilitat us-east-1a.
AMSAFront01: Type: AWS::EC2::Subnet Properties: AvailabilityZone: us-east-1a CidrBlock: 10.0.1.0/24 VpcId: !Ref AMSAVPC Tags: - Key: Name Value: AMSA-Front-01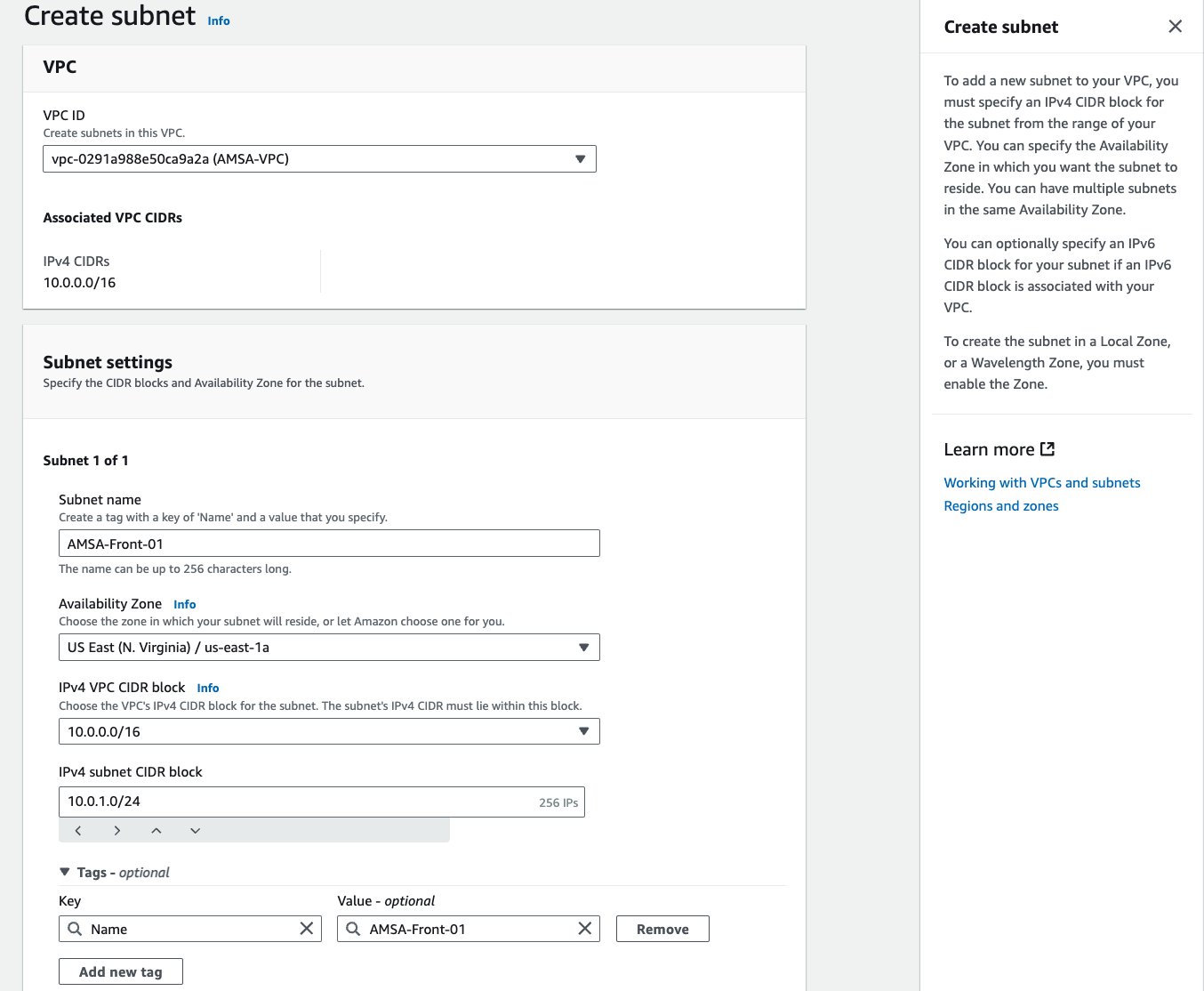
-
AMSA-Front-02: Subxarxa privada per a les instàncies de WordPress a la zona de disponibilitat us-east-1b.
AMSAFront02: Type: AWS::EC2::Subnet Properties: AvailabilityZone: us-east-1b CidrBlock: 10.0.2.0/24 VpcId: !Ref AMSAVPC Tags: - Key: Name Value: AMSA-Front-02 -
AMSA-Data: Subxarxa privada per a la base de dades RDS a la zona de disponibilitat us-east-1c.
AMSAData: Type: AWS::EC2::Subnet Properties: AvailabilityZone: us-east-1c CidrBlock: 10.0.3.0/24 VpcId: !Ref AMSAVPC Tags: - Key: Name Value: AMSA-Data
A continuació es mostra un diagrama amb les subxarxes creades, incloent-hi els seus blocs CIDR i zones de disponibilitat associades:
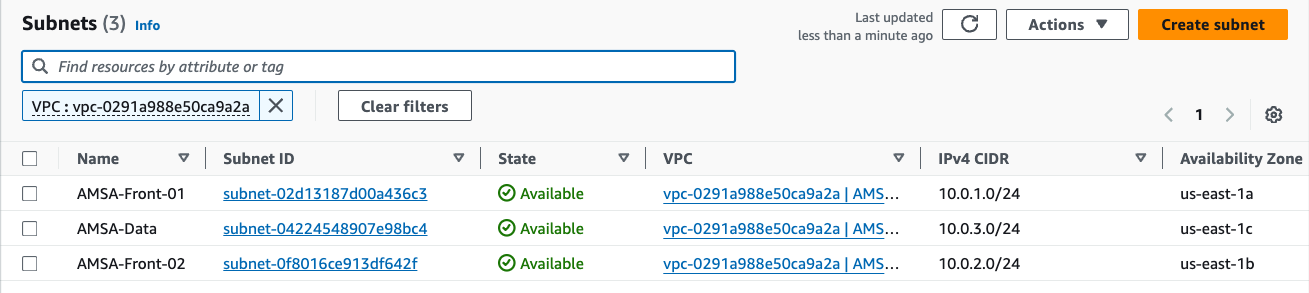
Nota: Assegureu-vos de tenir en aquest punt la VPC i les subxarxes creades correctament abans de continuar amb la configuració dels altres components.
Taules d'Enrutament i Associacions
Per gestionar les rutes del tràfic i determinar com es distribueix entre les subxarxes, crearem taules de rutes i les associem a les subxarxes corresponents. En aquesta fase inicial, cal assegurar:
- Front-01 i Front-02 tenen accés a Internet.
- Data no té accés a Internet; només necessita rutes locals per comunicar-se amb Front-01 i Front-02.
Recordeu que dins d'una VPC, les subxarxes poden comunicar-se entre elles sense necessitat de rutes explícites.
En primer lloc crearem un Gateway d'Internet per a la nostra VPC:
MSAIGW:
Type: AWS::EC2::InternetGateway
Properties:
Tags:
- Key: Name
Value: AMSA-IGW

I l'associarem a la nostra VPC:
AMSAIGWAttachment:
Type: AWS::EC2::VPCGatewayAttachment
Properties:
VpcId: !Ref AMSAVPC
InternetGatewayId: !Ref AMSAIGW
-
Taula de rutes per a la subxarxa AMSA-Front-01:
AMSAFront01RouteTable: Type: AWS::EC2::RouteTable Properties: VpcId: !Ref AMSAVPC Tags: - Key: Name Value: AMSA-Front-01-RouteTable
-
Associació de la taula de rutes amb la subxarxa AMSA-Front-01:
AMSAFront01RouteTableAssociation: Type: AWS::EC2::SubnetRouteTableAssociation Properties: RouteTableId: !Ref AMSAFront01RouteTable SubnetId: !Ref AMSAFront01Per fer-ho, navegarem a la consola de VPC d'AWS, seleccionarem la subxarxa AMSA-Front-01 anireu a la secció Subnet Associations i clicareu a Edit subnet associations. A continuació, seleccionarem la taula de rutes AMSA-Front-01-RouteTable i clicarem a Save.
-
Permetem el tràfic de sortida a Internet:
AMSAFront01Route: Type: AWS::EC2::Route Properties: RouteTableId: !Ref AMSAFront01RouteTable DestinationCidrBlock: 0.0.0.0/0 GatewayId: !Ref AMSAIGWPer fer-ho, navegarem a la consola de VPC d'AWS, seleccionarem la subxarxa AMSA-Front-01 anireu a la secció Routes i clicareu a Edit routes. A continuació, Add route i editareu (Destination: 0.0.0.0/0; Target:Seleccionar el AMSA-IG).
-
-
Repetir el procés per a AMSA-Front-02
Els passos per a la subxarxa AMSA-Front-02 són idèntics als anteriors:
- Crear una taula de rutes específica.
- Associar-la a la subxarxa.
- Configurar una ruta de sortida al Gateway d'Internet.
Taula de rutes per a AMSA-Data
La subxarxa AMSA-Data no requereix accés directe a Internet. Només necessita rutes locals per comunicar-se amb altres subxarxes dins de la VPC. Per a això, crearem una taula de rutes i l'associarem a AMSA-Data, però sense definir cap ruta al Gateway d'Internet.
En la següent figura es mostra la configuració de les taules de rutes i les associacions amb les subxarxes:
Nota: Assegureu-vos de tenir en aquest punt les associacions creades correctament abans de continuar amb la configuració dels altres components.
Grups de Seguretat
Els grups de seguretat (Security Groups) són una eina per controlar el tràfic de xarxa de les instàncies i altres recursos d’AWS. A cada grup de seguretat se li poden definir regles per especificar:
- Trafic inbound: Permet decidir quins tipus de connexions entrants (cap al recurs) són permeses.
- Trafic outbound: Controla quines connexions sortints (des del recurs cap a altres destinacions) estan autoritzades.
A continuació, configurarem els grups de seguretat per a les instàncies EC2 i la base de dades RDS.
Grup de Seguretat per a les instàncies EC2
Aquest grup de seguretat permetrà:
- Connexions entrants (inbound) per als serveis web HTTP (port 80) i HTTPS (port 443), accessibles des de qualsevol origen.
- Connexions SSH (port 22) per a administració remota, també accessibles des de qualsevol origen (inicialment, però més endavant es restringiran).
- Totes les connexions sortints (outbound), que per defecte estan permeses a AWS, cosa que permet a les instàncies EC2 comunicar-se amb altres recursos com ara RDS.
AMSAWebSG:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Security Group for AMSA Web Servers
VpcId: !Ref AMSAVPC
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: 80
ToPort: 80
CidrIp: 0.0.0.0/0
- IpProtocol: tcp
FromPort: 443
ToPort: 443
CidrIp: 0.0.0.0/0
- IpProtocol: tcp
FromPort: 22
ToPort: 22
CidrIp: 0.0.0.0/0
SecurityGroupEgress:
- IpProtocol: -1
FromPort: -1
ToPort: -1
CidrIp: 0.0.0.0/0
Tags:
- Key: Name
Value: AMSA-Web-SG
Per fer-ho, navegarem a la consola de VPC d'AWS, seleccionarem la secció Security Groups i clicarem a Create security group. A continuació, omplirem els camps amb la informació necessària i clicarem a Create security group.
Nota: En aquest moment, estem permetent tot el tràfic de xarxa per als serveis web i SSH. Quan ho tinguem tot configurat, restringirem aquest accés únicament al trafic entrant provinent del balancejador de càrrega pels serveis web i a la nostra xarxa interna per a SSH.
Grup de Seguretat per a la base de dades RDS
Aquest grup de seguretat limitarà:
- Connexions inbound: Només permetrà tràfic al port 3306 (MySQL) i exclusivament des de les instàncies EC2 que pertanyin al grup de seguretat AMSAWebSG.
- Connexions outbound: Per defecte, AWS permetrà totes les connexions sortints, cosa que garanteix que la base de dades pugui comunicar-se amb altres recursos si és necessari.
AMSADbSG:
Type: AWS::EC2::SecurityGroup
Properties:
GroupDescription: Allow MySQL
VpcId: !Ref AMSAVPC
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: '3306'
ToPort: '3306'
SourceSecurityGroupId: !Ref AMSAWebSG
SecurityGroupEgress:
- IpProtocol: -1
FromPort: -1
ToPort: -1
CidrIp: 0.0.0.0/0
Tags:
- Key: Name
Value: AMSA-DB-SG
Per fer-ho, navegarem a la consola de VPC d'AWS, seleccionarem la secció Security Groups i clicarem a Create security group. A continuació, omplirem els camps amb la informació necessària i clicarem a Create security group.
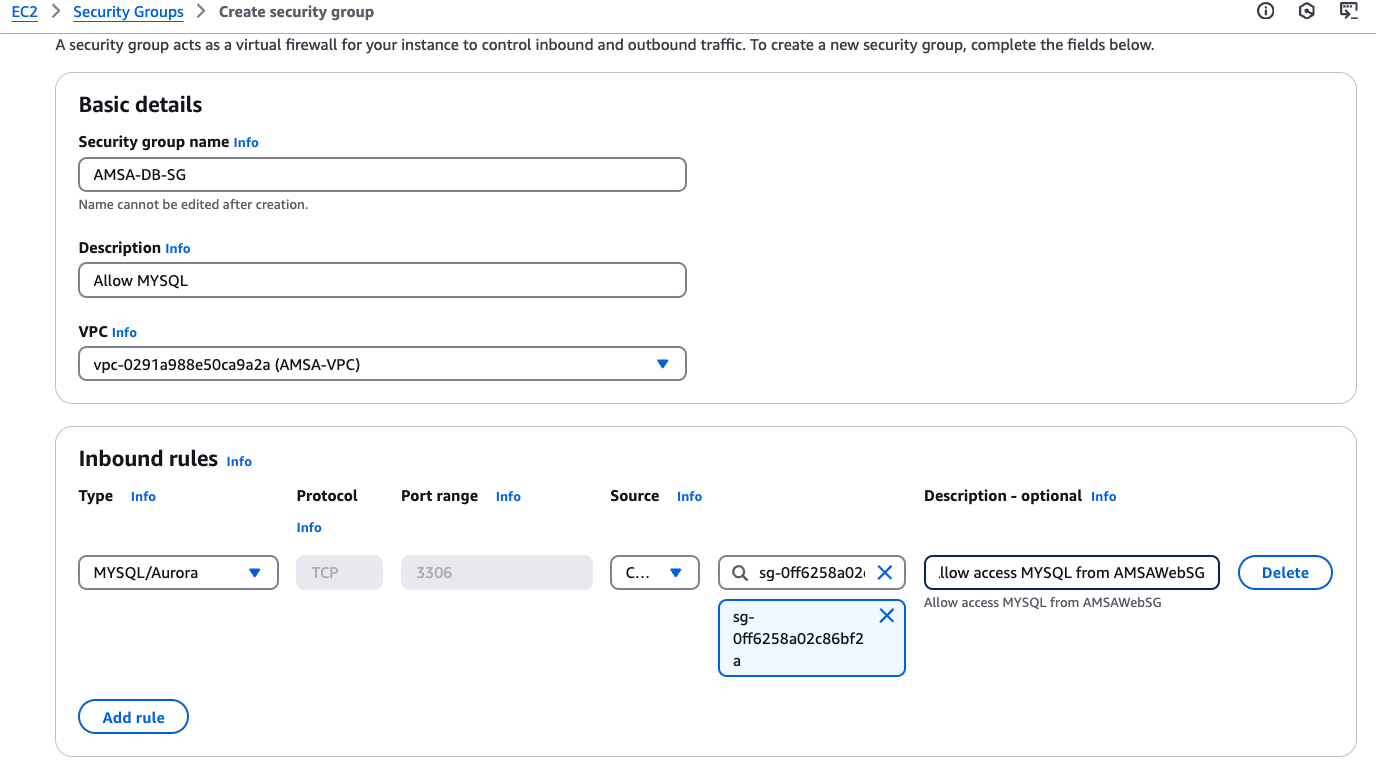
Resum
| Grup de Seguretat | Inbound | Outbound |
|---|---|---|
| AMSA-Web-SG | HTTP (80) i HTTPS (443) des de 0.0.0.0/0; SSH (22) des de 0.0.0.0/0 | Totes permeses |
| AMSA-DB-SG | MySQL (3306) des de AMSA-Web-SG | Totes permeses |
Creació de la Base de Dades RDS
En aquest punt, crearem la base de dades RDS que utilitzarà WordPress per emmagatzemar les dades. Utilitzarem una instància de base de dades MySQL amb les següents característiques:
- Choose a database creation method: Standard Create
- Motor de base de dades: MariaDB
- Version: MariaDB 10.11.9
- Templates: Free tier
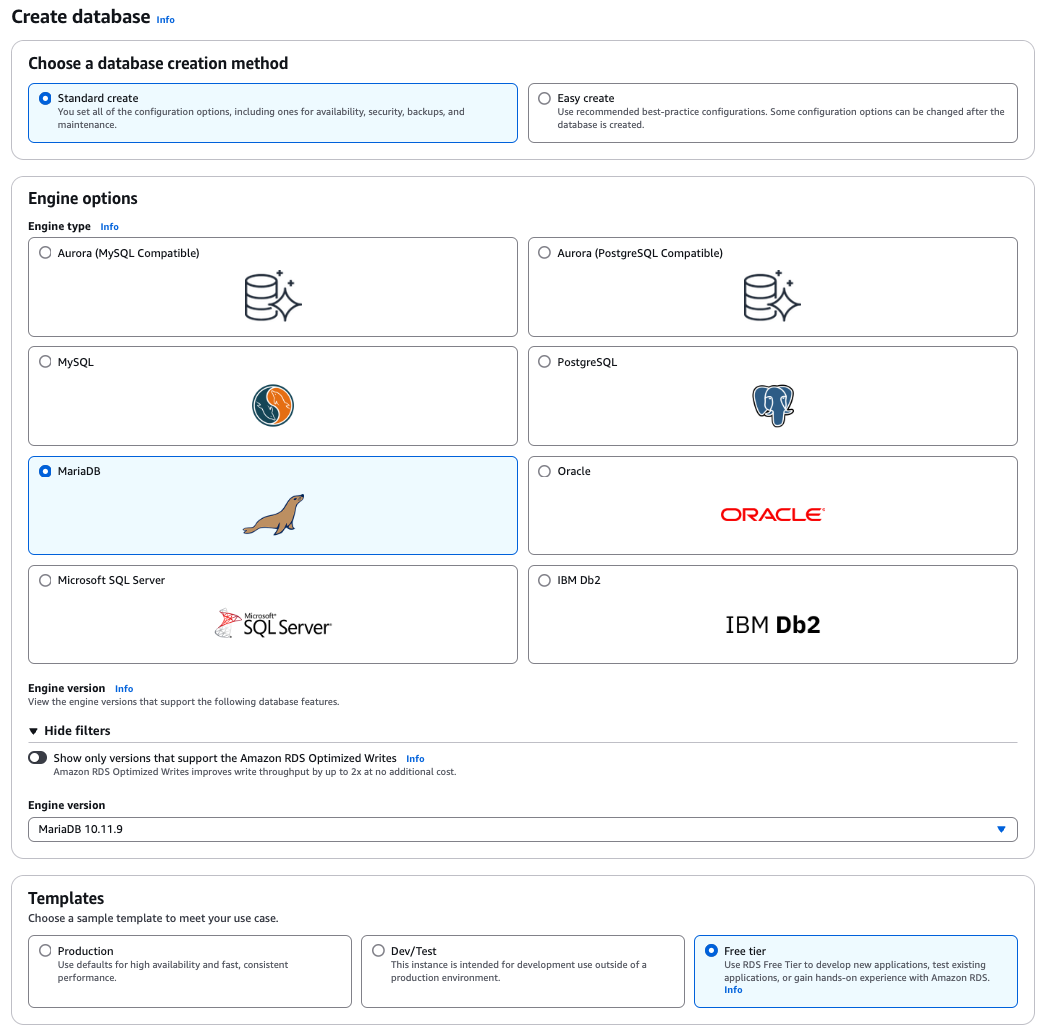
- DB instance Identifier: AMSA-DB
- Credentials Management: Self-managed
- Master Username: admin
- Master Password: h0dc?r00t?p4ssw0rd
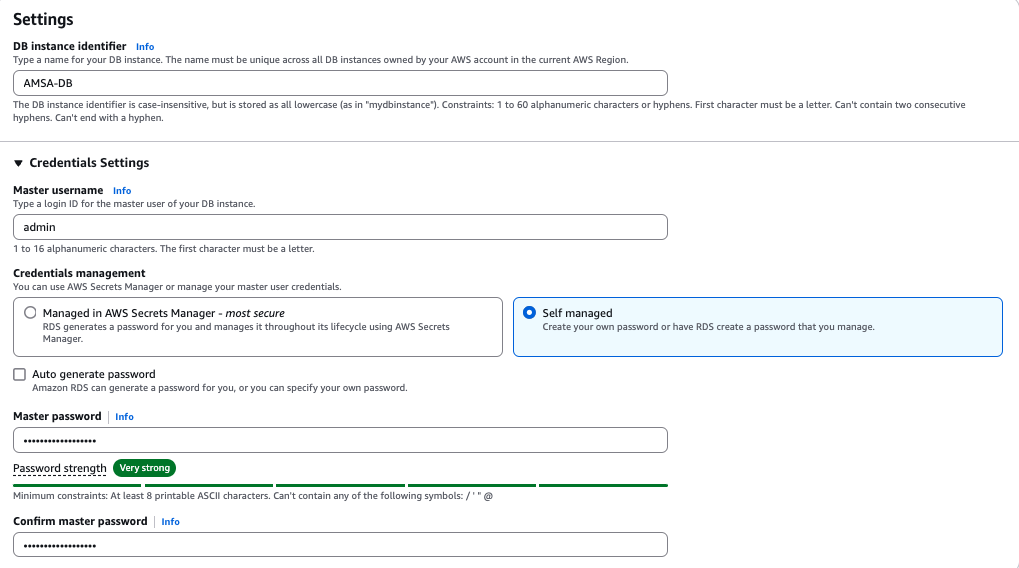
La resta de paràmetres es poden deixar per defecte a les seccions de Instance Configuration, i Storage.
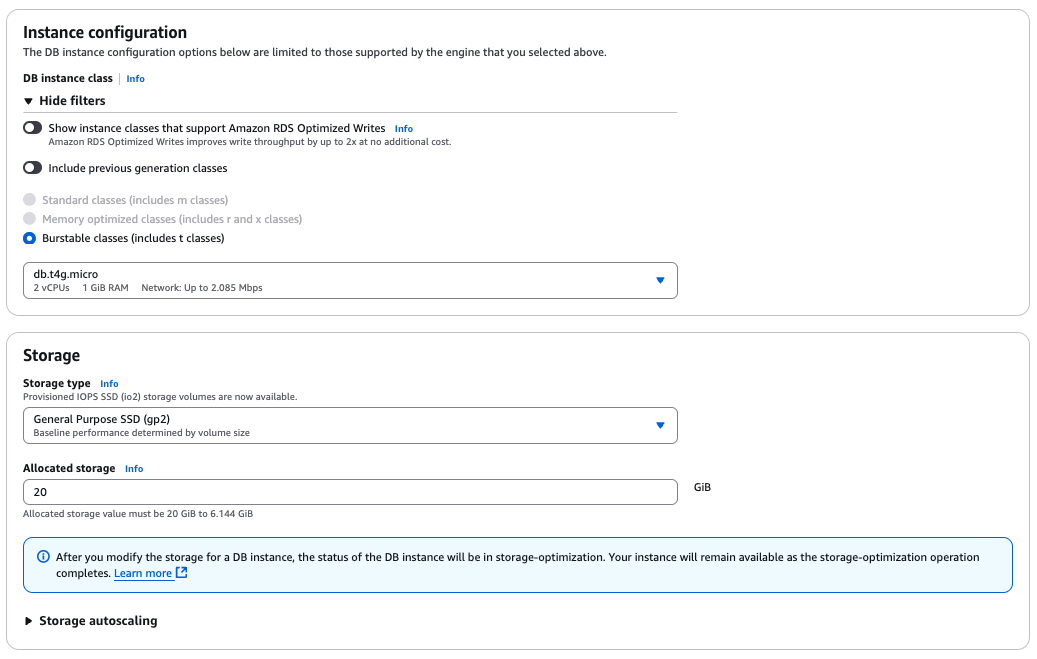
- Compute resources: Don't connect to an EC2 compute resource
- VPC: AMSA-VPC
- Subnet Group: Create new DB Subnet Group
- Public accessibility: No
- VPC security group: AMSA-DB-SG
- Availability Zone: No preference
La resta de paràmetres es poden deixar per defecte a les seccions de Database authentication, i Backup.
AMSADataDB:
Type: AWS::RDS::DBInstance
Properties:
AllocatedStorage: '20'
DBInstanceIdentifier: AMSA-DB
DBInstanceClass: db.t4g.micro
Engine: mariadb
EngineVersion: 10.11.9
MasterUsername: admin
MasterUserPassword: h0dc?r00t?p4ssw0rd
VPCSecurityGroups:
- !GetAtt AMSADataSG.GroupId
DBSubnetGroupName: !Ref AMSADBSubnetGroup
MultiAZ: false
PubliclyAccessible: false
Tags:
- Key: Name
Value: AMSA-Data-DB
DependsOn:
- AMSADataSG
- AMSADBSubnetGroup
Nota: Assegureu-vos de tenir en aquest punt la base de dades RDS creada correctament abans de continuar amb la configuració dels altres components.
Creació de l'instància EC2
En aquest punt, crearem una instancia EC2 amb el grup de seguretat AMSAWebSG amb AMI Amazon Linux 2023 i el tipus d'instància t2.micro, instal·larem el client mysql i testarem la connexió amb la base de dades RDS.
- Nom de la instància: AMSA-WS-WP01
- AMI: Amazon Linux 2023 (64-bit x86)
- Tipus d'instància: t2.micro
-
Key Pair: AMSA-KEY
-
VPC: AMSA-VPC
-
Subxarxa: AMSA-Front-01
-
Grup de Seguretat: AMSAWebSG
-
IP Pública: Enable
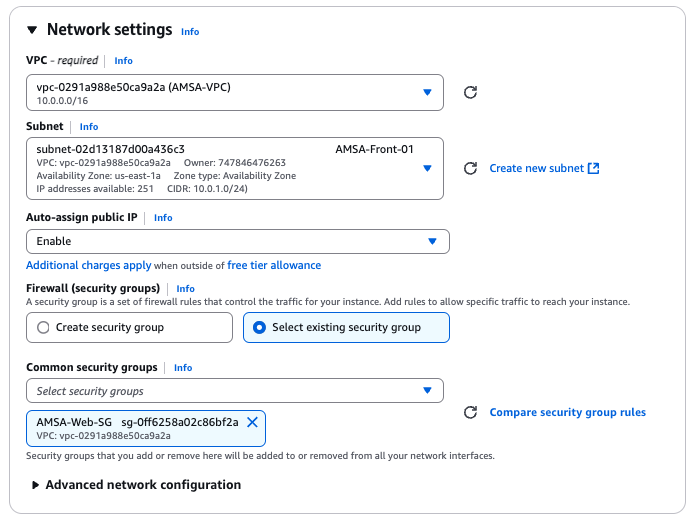
La resta de paràmetres es poden deixar per defecte a la resta de seccions.
AMSAWebServer:
Type: AWS::EC2::Instance
Properties:
InstanceType: t2.micro
ImageId: ami-0c55b159cbfafe1f0
KeyName: AMSA-KEY
NetworkInterfaces:
- AssociatePublicIpAddress: true
DeviceIndex: 0
GroupSet:
- !Ref AMSAWebSG
SubnetId: !Ref AMSAFront01
Tags:
- Key: Name
Value: AMSA-WS-WP01

Per accedir a la instància EC2, podeu utilitzar una shell SSH amb la clau privada associada al vostre Key Pair o bé la consola web d'AWS.
Un cop dins de la instància, instal·larem el client MySQL i provarem la connexió amb la base de dades RDS:
sudo dnf install mariadb105 -y
Un cop instal·lat el client MySQL, provarem la connexió amb la base de dades RDS:
# Modifiqueu les dades d'accés segons les vostres credencials i el vostre endpoint
# mysql -h <endpoint> -u <usuari> -p
mysql -h amsa-db.cztwlalq0ipf.us-east-1.rds.amazonaws.com -u admin -p
Si tot ha anat bé, hauríeu de poder connectar-vos a la base de dades RDS amb les credencials proporcionades:
En aquest punt, podem aprofitar i configurar una base de dades per a WordPress. Això ens permetrà tenir la base de dades preparada per a la instal·lació de WordPress en les instàncies EC2.
CREATE DATABASE wordpress;
CREATE USER 'amsa-wordpress-user'@'%' IDENTIFIED BY 'h0dc-w0rdpr3ss-p4ssw0rd';
GRANT ALL PRIVILEGES ON wordpress.* TO 'amsa-wordpress-user'@'%';
FLUSH PRIVILEGES;
exit
Nota: Assegureu-vos de que totes les comandes s'executen correctament i obteniu un Query OK per a cada comanda.
Configuració del Servidor Web amb WordPress
En aquest punt, volem crear un servidor web amb WordPress. Per fer-ho, instal·larem el servidor web Apache, el llenguatge de programació PHP. A continuació, descarregarem i configurarem WordPress per a la nostra aplicació. Aquests passos ja els vam realitzar en la pràctica anterior de forma manual. Ara, els automatitzarem creant una plantilla que ens permeti desplegar instàncies EC2 amb WordPress ja configurat i preparades per connectar amb la nostra base de dades RDS.
#!/bin/bash
# sudo bash install_wp.sh
# Ajusteu les dades següents segons les vostres dades
DB_NAME="wordpress"
DB_USER="amsa-wordpress-user"
DB_ROOT_USER="admin"
DB_USER_PASSWORD="h0dc-w0rdpr3ss-p4ssw0rd"
DB_ROOT_PASSWORD="h0dc?r00t?p4ssw0rd"
DB_HOST="amsa-db.cztwlalq0ipf.us-east-1.rds.amazonaws.com"
if [ "$(id -u)" -ne 0 ]; then
echo "Please run this script with sudo or as root."
exit 1
fi
dnf install -y wget php-mysqlnd httpd php-fpm php-mysqli php-json php php-devel php-gd expect
cd /tmp
wget https://wordpress.org/latest.tar.gz
tar -xzf latest.tar.gz
# Configure WordPress
cp wordpress/wp-config-sample.php wordpress/wp-config.php
sed -i "s/database_name_here/$DB_NAME/g" wordpress/wp-config.php
sed -i "s/username_here/$DB_USER/g" wordpress/wp-config.php
sed -i "s/password_here/$DB_USER_PASSWORD/g" wordpress/wp-config.php
sed -i "s/localhost/$DB_HOST/g" wordpress/wp-config.php
sudo cp -r wordpress/* /var/www/html/
sudo sed -i 's/AllowOverride None/AllowOverride All/g' /etc/httpd/conf/httpd.conf
sudo chown -R apache:apache /var/www
sudo chmod 2775 /var/www
sudo systemctl restart httpd
Aquest script ens permetrà instal·lar i configurar un servidor web amb WordPress a les nostres instàncies EC2. Aneu a Launch Templates i creeu una nova plantilla amb la configuració de la instància EC2 i el script anterior.
- Nom de la plantilla: AMSA-WS-WP-Template
- Auto Scaling Guidance: Yes
- AMI: Amazon Linux 2023 (64-bit x86)
- Tipus d'instància: t2.micro
- Key Pair: AMSA-KEY
- Subxarxa: No seleccionar cap subxarxa (es seleccionarà dinàmicament)
- Grup de Seguretat: AMSAWebSG
Aneu a la secció de Advanced Details i afegiu el script anterior a la secció de UserData.

AMSAWSWPLT01:
Type: AWS::EC2::LaunchTemplate
Properties:
LaunchTemplateName: AMSA-WS-WP-LT01
LaunchTemplateData:
ImageId: ami-063d43db0594b521b
InstanceType: t2.micro
NetworkInterfaces:
- DeviceIndex: 0
AssociatePublicIpAddress: true
SubnetId: !Ref AMSAFront01
Groups:
- Ref: AMSAWebSG
UserData: !Base64
Fn::Sub: |
#!/bin/bash
dnf install -y wget php-mysqlnd httpd php-fpm php-mysqli php-json php php-devel php-gd expect
cd /tmp
wget https://wordpress.org/latest.tar.gz
tar -xzf latest.tar.gz
cp wordpress/wp-config-sample.php wordpress/wp-config.php
sed -i "s/database_name_here/wordpress/g" wordpress/wp-config.php
sed -i "s/username_here/amsa-wordpress-user/g" wordpress/wp-config.php
sed -i "s/password_here/h0dc-w0rdpr3ss-p4ssw0rd/g" wordpress/wp-config.php
sed -i "s/localhost/${AMSADataDB.Endpoint.Address}/g" wordpress/wp-config.php
cp -r wordpress/* /var/www/html/
sed -i 's/AllowOverride None/AllowOverride All/g' /etc/httpd/conf/httpd.conf
chown -R apache:apache /var/www
chmod 2775 /var/www
systemctl enable httpd
systemctl restart httpd
TagSpecifications:
- ResourceType: launch-template
Tags:
- Key: Name
Value: AMSA-WS-WP-LT01
Un cop creada la plantilla de llançament, podeu utilitzar-la per crear instàncies EC2 amb WordPress ja configurat i preparades per connectar amb la vostra base de dades RDS.

Aneu a la secció EC2 de la consola d'AWS i seleccioneu Launch Instance.

A continuació, seleccioneu la plantilla de llançament AMSA-WS-WP-Template i configureu la resta de paràmetres segons les vostres necessitats (seleccioneu la subxarxa Front-02 per a aquest exemple). A més a més, seleccioneu que s'assigni una IP pública a la instància.
Un cop creada la instància:

Observeu que la instància EC2 s'ha creat sense nom assignat. Això és degut a que el nom de la instància no l'hem definit.
Si tot ha anat bé, hauríeu de poder accedir a la instància EC2 a través del navegador web i veure la pàgina d'instal·lació de WordPress:
Nota: No realitzarem la instal·lació de WordPress en aquest punt, ja que primer configurarem el balancejador de càrrega. Quan s'instal·la wordpress guarda i configurar la ip de la instància, per tant, si després es vol posar un balancejador de càrrega, no funcionarà correctament i haurem de reconfigurar wordpress. Per tant, primer configurarem el balancejador de càrrega i després instal·larem wordpress per tal de que quan s'instal·li, es guardi la ip del balancejador de càrrega que és la que es mantindrà constant.
Creació del Balancejador de Càrrega
En aquest punt, crearem un balancejador de càrrega per a les nostres instàncies EC2. Aquest balancejador de càrrega serà responsable de distribuir uniformement el tràfic entre les instàncies EC2 que allotgen WordPress.
Existeixen 3 tipus de balancejadors de càrrega a AWS: Application Load Balancer (ALB), Network Load Balancer (NLB) i Gateway Load Balancer (GWLB). En aquest cas, utilitzarem un Application Load Balancer (ALB), ja que és el recomanat per a aplicacions web que utiltizen HTTP i HTTPS.
Navegueu a la consola de AWS i seleccioneu el servei EC2. A la barra lateral, seleccioneu Load Balancers i després Create Load Balancer.
- Nom del balancejador de càrrega: AMSA-ALB
- Scheme: Internet-facing
- IP Address Type: IPv4

- VPC: AMSA-VPC
- Availability Zones: Seleccionar les zones de disponibilitat on tenim les subxarxes Front-01 i Front-02.
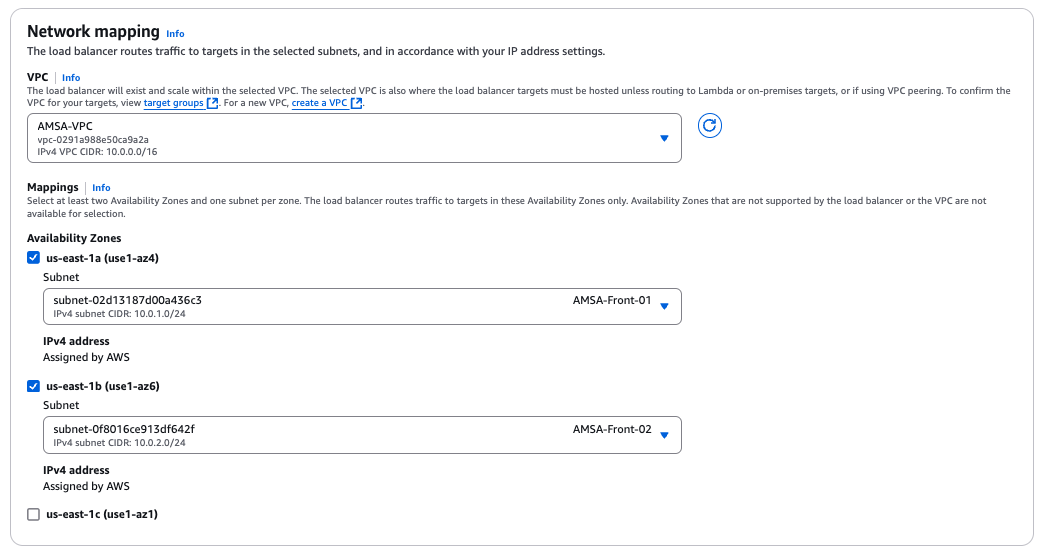
-
Grups de Seguretat: Nou grup de seguretat (AMSA-ALB-SG), aquest grup de seguretat permetrà el tràfic d'entrada per als ports 80 (HTTP) i 443 (HTTPS) des de qualsevol origen però restringirà el tràfic de sortida a les instàncies EC2 (grup de seguretat AMSAWebSG).
AMSALBSG: Type: AWS::EC2::SecurityGroup Properties: GroupDescription: Security Group for AMSA ALB VpcId: !Ref AMSAVPC SecurityGroupIngress: - IpProtocol: tcp FromPort: 80 ToPort: 80 CidrIp: 0.0.0.0/0 - IpProtocol: tcp FromPort: 443 ToPort: 443 CidrIp: 0.0.0.0/0 SecurityGroupEgress: - IpProtocol: -1 FromPort: -1 ToPort: -1 DestinationSecurityGroupId: !Ref AMSAWebSG Tags: - Key: Name Value: AMSA-ALB-SG
-
Listeners: Crearem un listener per al port 80 (HTTP), que redirigirà el tràfic al port 80 de les instàncies EC2. Al port 443 (HTTPS) de moment no configurarem cap redirecció. Per fer-ho, primer haureu de crear un Target Group. Aquest grup es necessari per indicar al balancejador de càrrega on enviar el tràfic.
-
Target Group:
- Target Type: Instance
- Nom: AMSA-WS-WP-TG
- Protocol: HTTP
- Port: 80
- VPC: AMSA-VPC
- Health Check: Per defecte, el balancejador de càrrega comprova la salut de les instàncies EC2 a través del port 80 i la ruta /. Això significa que el balancejador de càrrega enviarà tràfic a les instàncies EC2 que responguin correctament a les peticions HTTP a la ruta /. Com que les nostres instàncies EC2 tenen WordPress instal·lat, aquestes instàncies respondran correctament a les peticions HTTP a la ruta /. Podem deixar la configuració per defecte.
Nota: La instal·lació de wordpress retorna 302, per tant, el health check no funcionarà correctament. Per solucionar-ho, temporalment, podem modificar el health check perquè comprovi la resposta 302 en lloc de la 200.
Finalment, crearem el target group:
AMSAWSWPTG: Type: AWS::ElasticLoadBalancingV2::TargetGroup Properties: HealthCheckIntervalSeconds: 30 HealthCheckPath: / HealthCheckProtocol: HTTP HealthCheckTimeoutSeconds: 5 HealthyThresholdCount: 2 Name: AMSA-WS-WP-TG Port: 80 Protocol: HTTP TargetType: instance UnhealthyThresholdCount: 2 VpcId: !Ref AMSAVPC-
Registrar targets: Afegeix les instàncies EC2 al target group. De les dues instàncies EC2 que tenim, seleccionarem les dues. Una instancia es marcarà com a healthy i l'altra com a unhealthy ja que la primera instancia no té wordpress instal·lat (l'hem creat per testar la connexió amb la base de dades RDS). Un cop ho comprovem, la desregistrem i només deixem la instància amb wordpress instal·lat.
-
Un cop creat el target group, el seleccionarem com a target del listener del balancejador de càrrega.
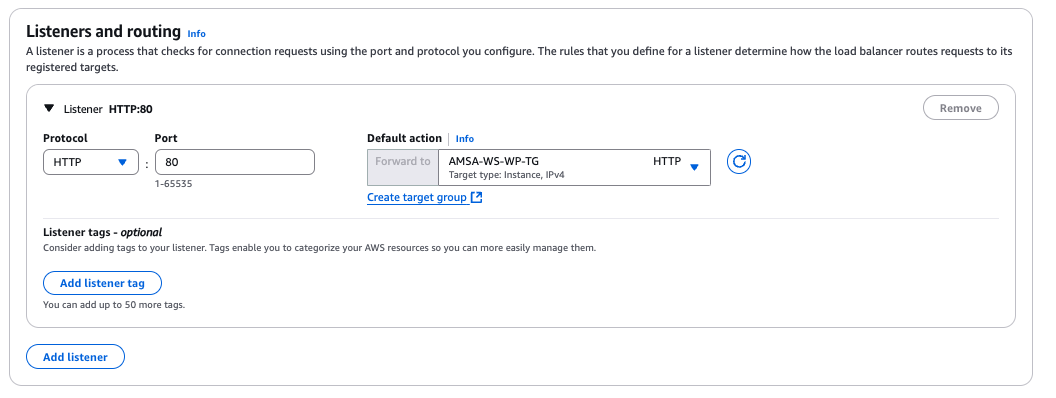
AMSAALB:
Type: AWS::ElasticLoadBalancingV2::LoadBalancer
Properties:
Name: AMSA-ALB
Scheme: internet-facing
IpAddressType: ipv4
SecurityGroups:
- !Ref AMSALBSG
Subnets:
- !Ref AMSAFront01
- !Ref AMSAFront02
Tags:
- Key: Name
Value: AMSA-ALB
DependsOn: AMSAWSWPTG
Abans de crear el balancejador de càrrega, assegureu-vos de tenir un resum amb totes les configuracions necessàries:
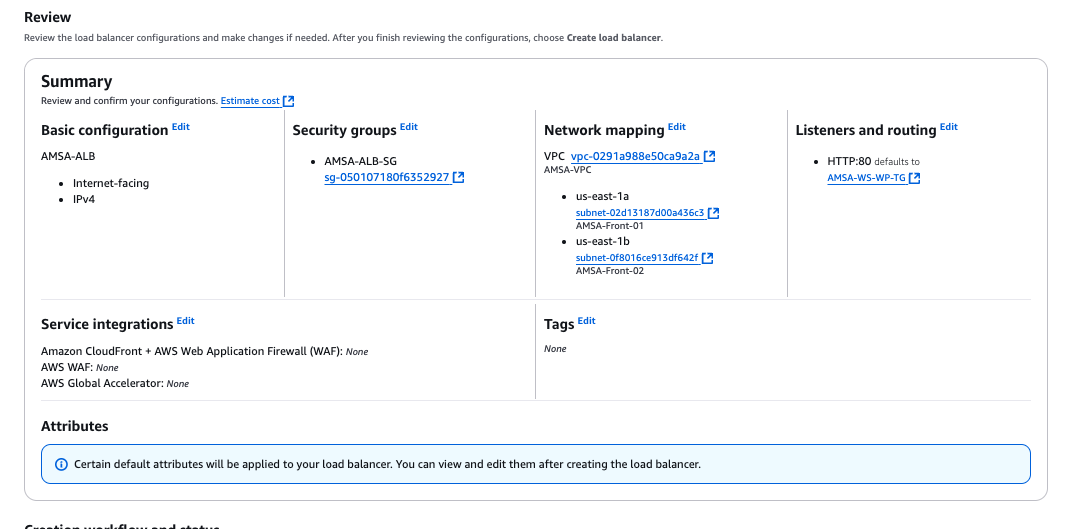
Un cop creat el balancejador de càrrega, heu d'esperar uns minuts fins que el seu estat passi de Provisioning a Active. Un cop l'estat sigui Active, podeu accedir al balancejador de càrrega a través de la seva adreça DNS.
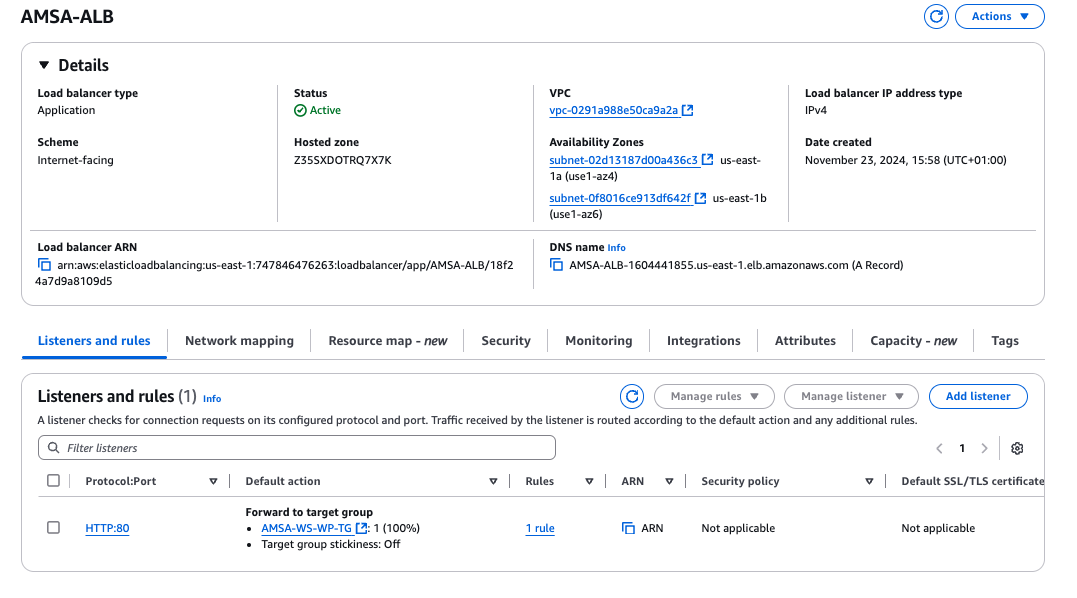
Un cop l'estat del balancejador de càrrega sigui Active, veure que tenim una target group amb una instància healthy i una unhealthy. Això és degut a que una de les instàncies EC2 no té WordPress instal·lat. Per solucionar-ho, desregistreu la instància unhealthy i només deixeu la instància healthy.
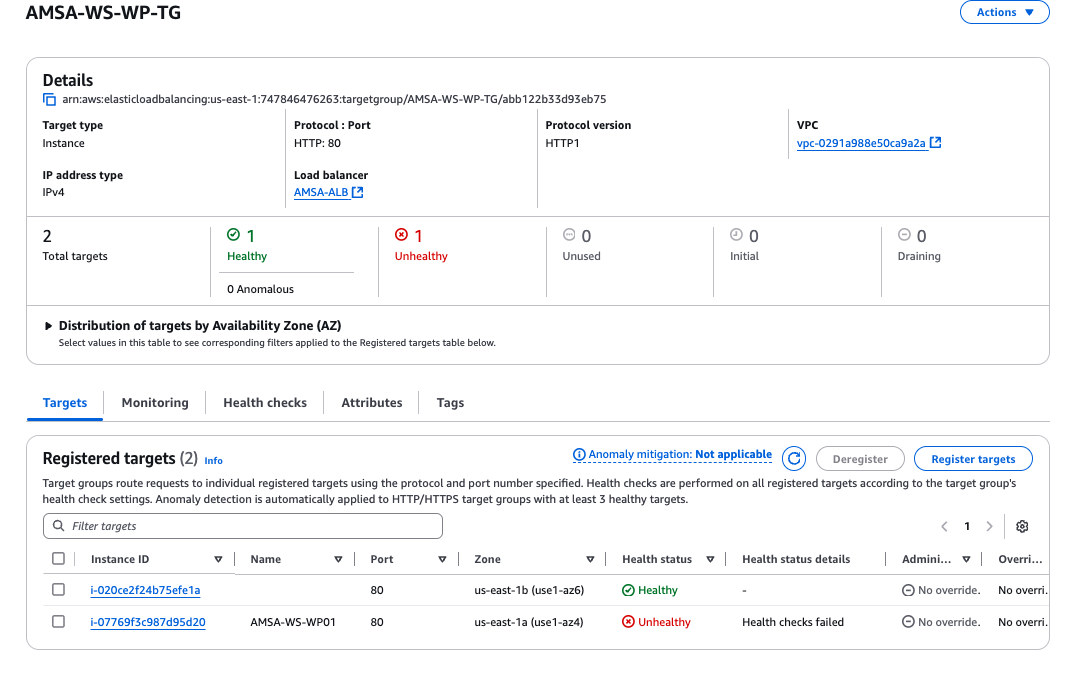
Ara ja podem accedir al balancejador de càrrega a través de la seva adreça DNS i veure la pàgina d'instal·lació de WordPress:
Procedirem a instal·lar WordPress a través del balancejador de càrrega. Podem definir el nom del lloc, l'usuari i la contrasenya de l'administrador, i la nostra adreça de correu electrònic:
- Site Title: AMSA WordPress
- Username: amsa-wp-admin
- Password: smveMMyD79@%4OauH3
- Your Email: amsa-wp-admin@gmail.com
Un cop instal·lat WordPress, haureu de veure la pàgina d'inici de WordPress:
Ara ja teniu el servidor web configurat amb WordPress i el balancejador de càrrega per distribuir el tràfic entre les instàncies EC2. Recordeu de modificar el health check del target group perquè comprovi la resposta del 200 en lloc de la 302. Haureu de deregistrar i tornar a registrar les instàncies EC2 perquè el health check es torni a comprovar.
Ara podeu utilitzar curl o recarregar la pàgina web per veure com el balancejador de càrrega distribueix el tràfic entre les instàncies EC2.
curl http://AMSA-ALB-XXXXXXX.us-west-2.elb.amazonaws.com
Per observar-ho podeu accedir als logs de les instàncies EC2 i veure com el tràfic es distribueix entre les dues instàncies.
sudo tail -f /var/log/httpd/access_log
Configuració VPN
En aquest punt, la vostra arquitectura permet als usuaris des de l'exterior a través d'interent mitjançant:
- El DNS públic del Load Balancer d'aplicacions (ALB) que redirigeix el tràfic HTTP i HTTPS a les instàncies EC2.
- El DNS públic de les instancies EC2 que despleguen el servei de WordPress.
Per solucionar-ho, actualitzarem el grup de seguretat de les instàncies EC2 per permetre el tràfic al port 80 únicament provinent del Load Balancer d'aplicacions (ALB). Això significa que les instàncies EC2 només acceptaran tràfic HTTP del Load Balancer d'aplicacions (ALB) i no de qualsevol altre origen.
A més a més, també es pot accedir a les instàncies EC2 a través de SSH que esta exposat a internet. Aquesta configuració pot ser un risc de seguretat, ja que els atacants podrien intentar accedir a les vostres instàncies EC2 a través de SSH. Un forma de solucionar es configurar una VPN que ens permeti adminsitrar els nostres recursos. D'aquesta forma, tindrem un únic punt d'entrada a la nostra intranet i podrem accedir als nostres recursos de forma segura.
EC2 per desplegar el servidor VPN
Per desplegar el servidor VPN, crearem una nova instància EC2 que actuarà com a servidor VPN. Aquesta instància EC2 haurà d'estar en una subxarxa pública connectada a interent.
-
Navegueu a la consola de AWS i seleccioneu el servei EC2. A la barra lateral, seleccioneu Instances i després Launch Instances.
-
Seleccioneu la imatge Ubuntu Server 22.04 LTS.
-
Seleccioneu la instància t2.micro.
-
Configureu la instància:
- Network: AMSA-VPC
- Subnet: Front-01
- Auto-assign Public IP: Enable
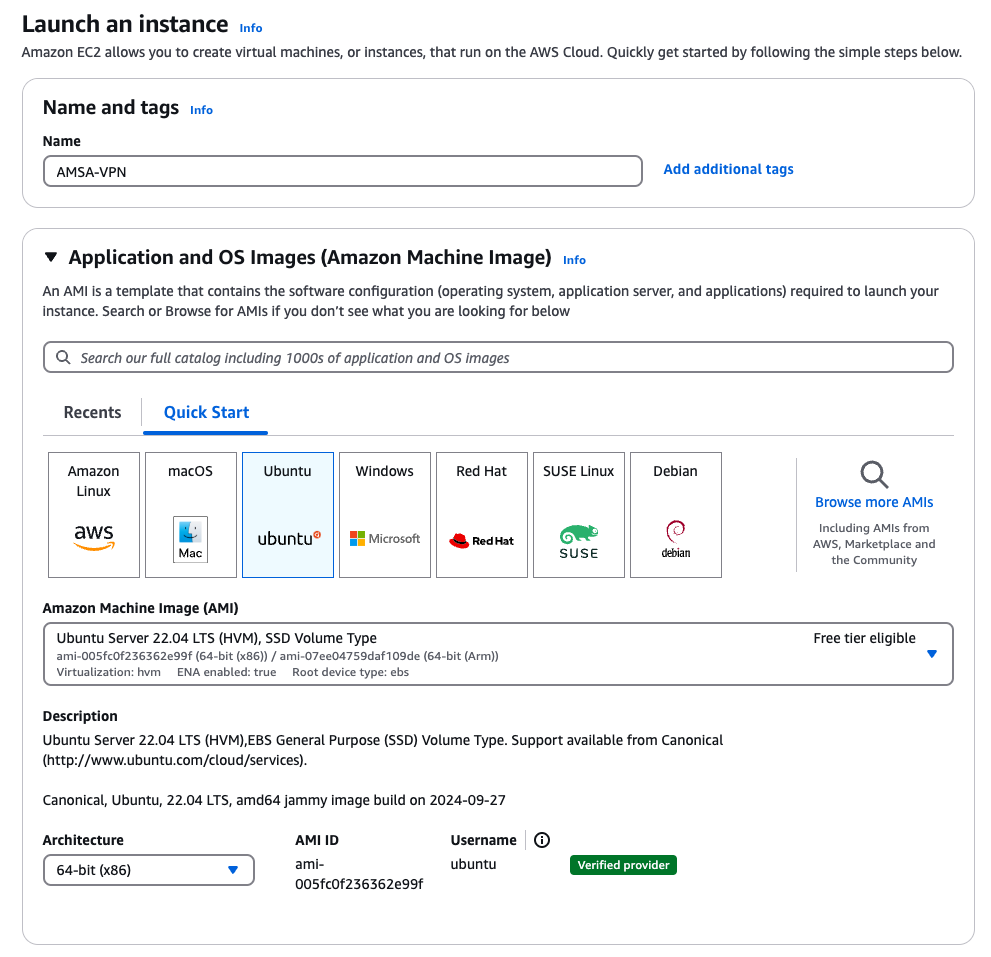
-
Configureu el grup de seguretat: AMSAVPN-SG.
Si reviseu la documentació d'instal·lació del servidor OpenVPN: OpenVPN Access Server System Administrator Guide . Veure que necessitem els següents ports oberts: TCP 443, TCP 943, UDP 1194.
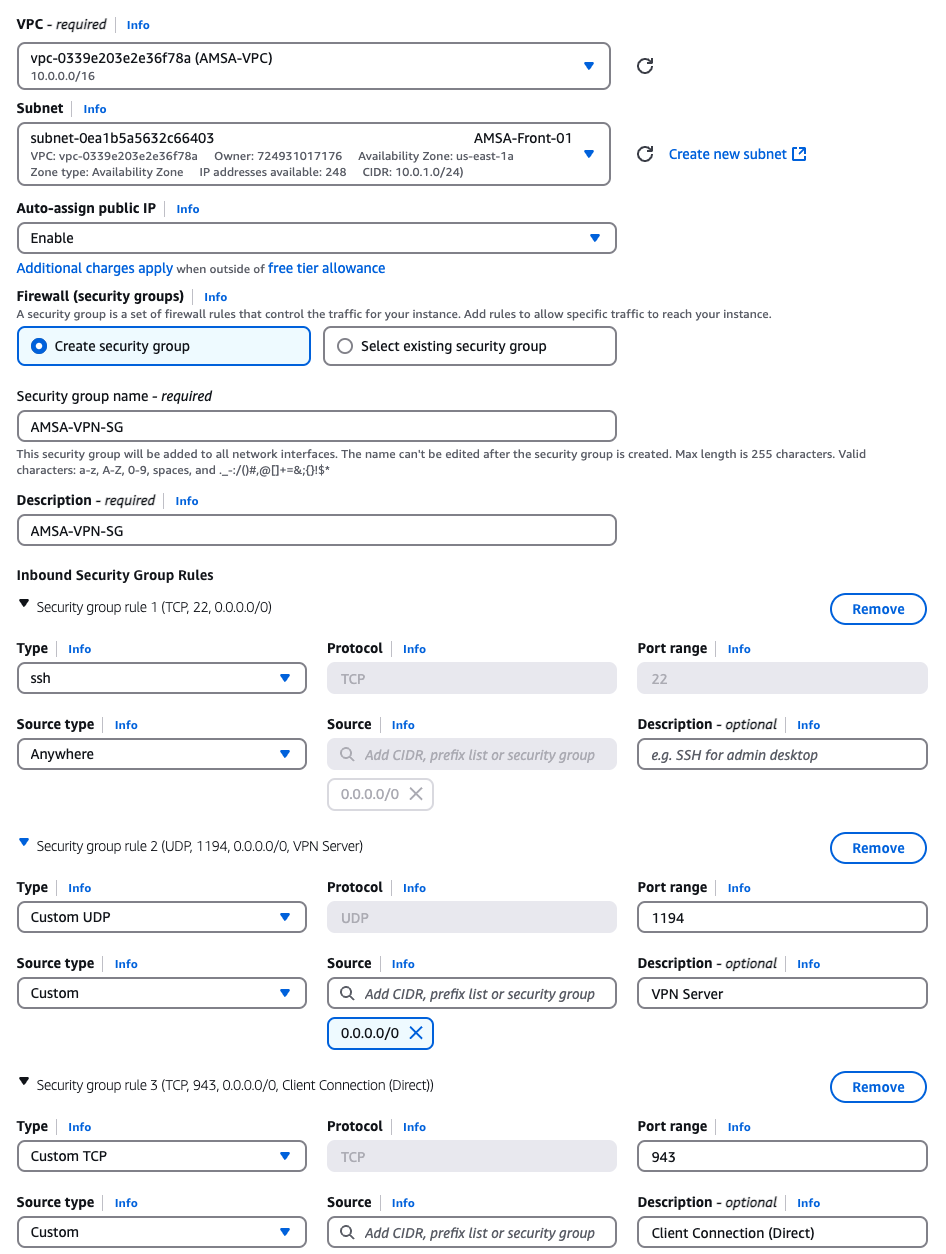
-
Connecteu-vos a la instància EC2 a través de la consola online de AWS o amb una connexió SSH i executeu la següent comanda per instal·lar el servidor OpenVPN:
sudo apt update -y sudo apt install ca-certificates gnupg wget net-tools -y sudo wget https://as-repository.openvpn.net/as-repo-public.asc -qO /etc/apt/trusted.gpg.d/as-repo-public.asc sudo echo "deb [arch=amd64 signed-by=/etc/apt/trusted.gpg.d/as-repo-public.asc] http://as-repository.openvpn.net/as/debian jammy main" | sudo tee /etc/apt/sources.list.d/openvpn-as-repo.list sudo apt update && sudo apt install openvpn-as -y
-
Amb aquestes credencials, podreu accedir a la interfície web del servidor OpenVPN a través del vostre navegador web. Navegueu a la IP pública de la instància EC2 (en el meu cas https://44.199.196.242:943/admin), com no tenim el certificat SSL configurat, ens sortirà un missatge d'advertència, ignoreu-lo i continueu. Inicieu sessió amb les credencials que heu configurat anteriorment.
Nota: Si heu perdut les credencials de l'usuari
openvpn, les podeu recuperar consultat el fitxer de logs del servidor OpenVPN. Per exemple, podeu consultar el fitxer de logs amb la següent comanda:sudo less /usr/local/openvpn_as/init.log
- Accepteu els termes de llicència.
- Aneu a Network Settings i configureu la IP pública de la instància EC2 com a Hostname or IP Address.
- Aneu a VPN Settings a la secció de Routing i afegiu les subxarxes de la VPC que voleu accedir a través de la VPN i també poseu a NO Should client Internet traffic be routed through the VPN? per evitar que tot el tràfic del client sigui redirigit a través de la VPN.

IMPORTANT: Guardeu els canvis i actualitzeu el servidor OpenVPN. Un cop fet us desconectareu de la interfície web i al recarregar-la, haureu de tornar a iniciar sessió.
-
Un cop realitzada la configuració, descarregueu el client OpenVPN Connect per al vostre sistema operatiu i també accediu a la interfície web per descarregar el fitxer de configuració del client.
-
Un cop loguejats, descarregueu el fitxer de configuració del client i importeu-lo a l'aplicació OpenVPN Connect.
-
Un cop descarregat el client, importeu el fitxer de configuració del client a l'aplicació OpenVPN Connect i connecteu-vos al servidor VPN.
Nota: Si no teniu la vostra clau ssh, a les instancies EC2, és el moment de setejar-la. Simplement copieu la vostra clau pública ssh al fitxer
~/.ssh/authorized_keysde l'usuariubuntua la instància EC2 on teniu la VPN, i el mateix als usuarisec2-userde la resta de màquines. -
Un cop tot configurat, actualitzarem el grup de seguretat de les instàncies EC2 per permetre el tràfic al port 22 únicament provinent del servidor VPN. Això significa que les instàncies EC2 només acceptaran tràfic SSH del servidor VPN i no de qualsevol altre origen.
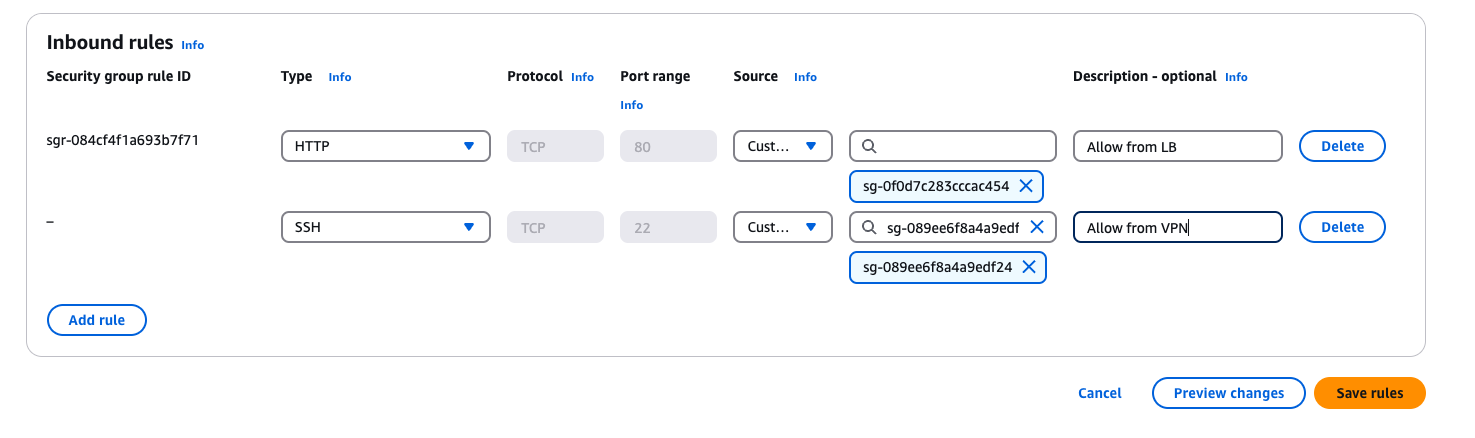
En aquest punt, ja no podreu accedir a les instàncies EC2 on teniu el servei de WordPress a través de SSH, ja que el tràfic SSH només es permet des del servidor VPN. Per accedir a les instàncies EC2, primer heu de connectar-vos al servidor VPN i després connectar-vos a les instàncies EC2. Per fer-ho:
-
Importeu el fitxer de configuració del client OpenVPN Connect a l'aplicació i connecteu-vos al servidor VPN.
TroubleShooting: Si en el fitxer de configuració veieu (Server Hostname) una ip del rang 10.0.X.X, això vol dir que la VPN no s'ha configurat correctament. Assegureu-vos de reiniciar el servidor i tornar a descarregar el fitxer de configuració del client, ha de tenir la ip pública del servidor VPN.
-
Utilitzeu la mateixa contrasenya del usuari
openvpnper connectar-vos al servidor VPN.
-
Si tot ha anat bé, veureu que esteu connectats al servidor VPN.
Finalment, connecteu-vos a les instàncies EC2:
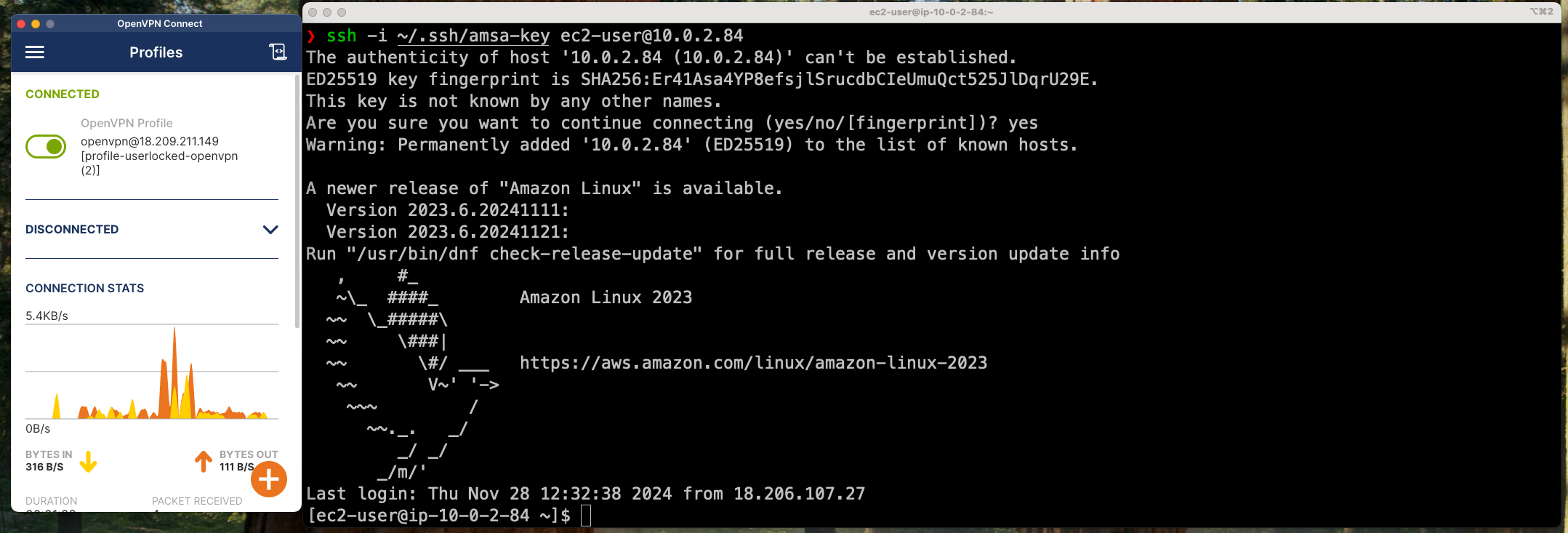
Consideracions importants: El servidor VPN ens permet accedir a les instàncies EC2 a través de SSH, però a partir de l'adreça interna (10.0.X.X) de la instància EC2. No podrem accedir a les instàncies EC2 a través de la seva adreça pública ja que hem configurat la VPN per accedir a les subxarxes de la VPC.
Millores
- Es podria millorar aquesta configuració evitant l'accés a l'interfície web del servidor OpenVPN a través de la IP pública i requerir l'accés a través de la VPN.
- Es podria configurar usuaris i grups per gestionar l'accés a la VPN de forma més granular.
AWS Lambda
AWS Lambda és un servei de computació sense servidor que executa el codi en resposta a esdeveniments i gestiona els recursos de computació necessaris. Aquest servei permet executar codi sense aprovisionar ni gestionar servidors.
Per exemple, podem guardar les nostres fotografies familiars a un bucket de S3 i crear una funció Lambda que redimensioni les imatges, apliqui filtres o qualsevol altra tasca que necessitem. Aquesta funció Lambda s'executarà cada vegada que es carregui una imatge al bucket de S3.
Cas d'ús bioinformàtic
Un laboratori podria voler automatitzar el procés de comptatge de cèl·lules en imatges de microscopi. Això es pot aconseguir amb AWS Lambda i un contenidor Docker amb python i les llibreries necessàries.
Una forma simple d'automatitzar aquest procés és implementar un algorisme que compti les cèl·lules en una imatge de microscopi. Per exemple, podem utilitzar l'algorisme de transformada de Hough per detectar cercles en una imatge:
import cv2
# Load the image
image = cv2.imread('image.png')
# Convert the image to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Apply Gaussian blur
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
# Apply Hough transform
circles = cv2.HoughCircles(blurred, cv2.HOUGH_GRADIENT, dp=1
minDist=20, param1=50, param2=30, minRadius=5, maxRadius=30)
# Count the cells
print('Cell count:', len(circles))
Si volem automatitzar aquest procés, podem utilitzar AWS Lambda per a processar les imatges de microscopi i comptar les cèl·lules. De manera que cada vegada que es carregui una imatge al bucket de S3, la funció Lambda s'executarà i comptarà les cèl·lules en la imatge. Si tenim dockeritzat el nostre codi, podem utilitzar un contenidor Docker per assegurar que tot l'entorn de Python i les llibreries necessàries estiguin disponibles en cada execució de la funció Lambda.
Pasos per a implementar-ho
-
Crea dos buckets S3:
- microscope-images-nom: Per a les imatges originals.
- microscope-images-processed-nom: Per a les imatges processades.
-
Crea una funció Lambda que s'executi cada vegada que es carregui una imatge al bucket
microscope-images-nom. Aquesta funció processarà les imatges utilitzant Python i les llibreries necessàries i carregarà les imatges processades al bucketmicroscope-images-processed-nom. -
Per fer-ho, crea una carpeta anomenada
cell-countingamb els següents fitxers:lambda_function.py: Conté el codi de comptatge de cèl·lules.Dockerfile: Conté les instruccions per construir la imatge Docker.requirements.txt: Conté les llibreries necessàries pel script.entrypoint.sh: Conté la comanda a executar quan el contenidor s'inicia.
cell-counting/ │ ├── lambda_function.py # Script Python per comptar cèl·lules ├── Dockerfile # Fitxer per construir la imatge Docker ├── requirements.txt # Llibreries necessàries (per exemple, opencv-python) └── entrypoint.sh # Script d'inici del contenidor-
lambda_function.py:import boto3 import cv2 import os import numpy as np import matplotlib.pyplot as plt def handler(event, context): # Set the matplotlib config directory to /tmp # This is required to avoid permission issues when saving the plot os.environ['MPLCONFIGDIR'] = '/tmp/matplotlib' output_bucket = os.environ['DST_BUCKET'] s3 = boto3.client('s3') input_bucket = event['Records'][0]['s3']['bucket']['name'] input_key = event['Records'][0]['s3']['object']['key'] filename = os.path.basename(input_key) local_path = '/tmp/' + filename s3.download_file(input_bucket, input_key, local_path) image = cv2.imread(local_path, cv2.IMREAD_COLOR) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) blurred = cv2.GaussianBlur(gray, (5, 5), 0) circles = cv2.HoughCircles(blurred, cv2.HOUGH_GRADIENT, dp=1, minDist=20, param1=50, param2=30, minRadius=5, maxRadius=30) if circles is not None: circles = np.round(circles[0, :]).astype("int") # Loop over the (x, y) coordinates and radius of the circles for (x, y, r) in circles: # Draw the circle in the output image, then draw a rectangle # corresponding to the center of the circle cv2.circle(image, (x, y), r, (0, 255, 0), 4) cv2.rectangle(image, (x - 5, y - 5), (x + 5, y + 5), (0, 128, 255), -1) # Create a plot fig = plt.figure() plt.imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)) plt.axis('off') output_path = '/tmp/' + filename + '_processed.jpg' plt.savefig(output_path) s3.upload_file(output_path, output_bucket, filename + '_processed.jpg') return { 'statusCode': 200, 'body': {"message": "Image processed and uploaded to S3!, Number of cells: " + str(len(circles))} } -
requirements.txt:opencv-contrib-python pandas boto3 numpy matplotlib setuptools -
entrypoint.sh:#!/bin/sh if [ -z "${AWS_LAMBDA_RUNTIME_API}" ]; then exec aws-lambda-rie python -m awslambdaric $@ else exec python -m awslambdaric $@ fi -
Dockerfile:# Use the provided base image FROM public.ecr.aws/lambda/provided:al2023 RUN dnf install -y awscli # Copy requirements.txt COPY requirements.txt ${LAMBDA_TASK_ROOT} RUN dnf install libglvnd-opengl libglvnd-glx python3-pip -y # Install dependencies and the Lambda Runtime Interface Client RUN pip install -r requirements.txt && \ pip install awslambdaric # Copy function code and entrypoint script COPY lambda_function.py ${LAMBDA_TASK_ROOT} COPY entrypoint.sh ${LAMBDA_TASK_ROOT} # Make entrypoint script executable RUN chmod +x entrypoint.sh # Set the ENTRYPOINT to the custom entrypoint script ENTRYPOINT [ "./entrypoint.sh" ] # Set the CMD to the handler for your Lambda function CMD [ "lambda_function.handler" ]
-
Construeix la imatge amb la comanda:
docker build -t cell-counting . -
Crea un repositori ECR amb el nom
cell-counting. -
Inicia sessió a ECR amb la comanda:
aws ecr get-login-password --region us-east-1 | docker login --username AWS --password-stdin <id>.dkr.ecr.us-east-1.amazonaws.com -
Etiqueta la imatge amb la comanda:
docker tag cell-counting:latest <id>.dkr.ecr.us-east-1.amazonaws.com/cell-counting:latest -
Puja la imatge a ECR amb la comanda:
docker push <id>.dkr.ecr.us-east-1.amazonaws.com/cell-counting:latestNota: AWS us indicarà dels passos 6, 7 i 8 la comanda exacta a executar.
-
Creació de la funció Lambda:
- Ves al servei Lambda.
- Clica Crea funció i selecciona Imatge de contenidor.
- Configura:
- Nom de la funció: cell-counting.
- URI de la imatge del contenidor: Selecciona la imatge cell-counting d'ECR.
- Rol d'execució: Utilitza un rol com LabRole amb permisos S3.
-
Configura el disparador de la funció Lambda:
- Clica a la funció cell-counting.
- Clica a Afegeix disparador.
- Selecciona S3.
- Configura:
- Bucket: microscope-images-nom.
- Tipus d'esdeveniment: PUT.
- Configura les variables d'entorn:
- MPLCONFIGDIR: /tmp/matplotlib.
- DST_BUCKET: microscope-images-processed-nom.
- Ajusta els recursos de la funció:
- Memòria: 1024 MB.
- Temps d'execució màxim: 1 minut.
- Emmagatzematge temporal: 512 MB.
-
Prova la funció Lambda:
- Puja una imatge al bucket
microscope-images-nom. - Revisa el resultat al bucket
microscope-images-processed-nom. - Pots trobar imatges reals al campus virtual.
- Puja una imatge al bucket